buddhi-dataset
收藏Hugging Face2024-07-31 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/aiplanet/buddhi-dataset
下载链接
链接失效反馈官方服务:
资源简介:
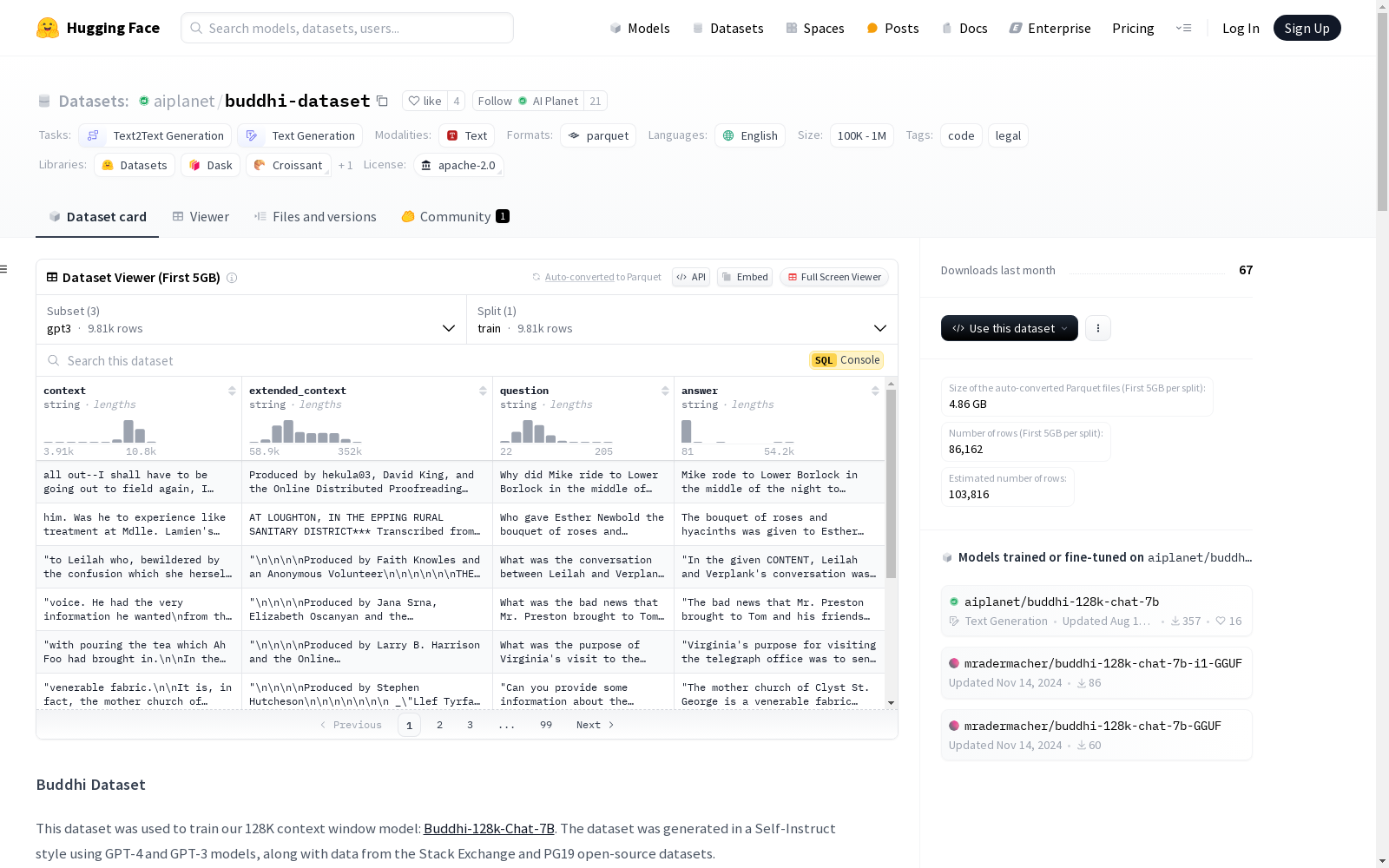
该数据集用于训练Buddhi-128K-Chat模型,包含GPT-3、GPT-4和Stack Exchange的配置,每个配置具有特定的特征和分割。数据集通过GPT-4和GPT-3模型生成,结合了Stack Exchange和PG19开源数据集的数据。该数据集支持文本到文本生成和文本生成任务,主要使用英语,并采用Apache 2.0许可证,标记为'代码'和'法律'。
创建时间:
2024-07-31
原始信息汇总
数据集概述
数据集配置
GPT-3 配置
- 特征:
context: 字符串extended_context: 字符串question: 字符串answer: 字符串
- 分割:
train:- 字节数: 2001754143
- 样本数: 9811
- 下载大小: 1233505501
- 数据集大小: 2001754143
GPT-4 配置
- 特征:
text: 字符串parsed:answer: 字符串context: 字符串question: 字符串
length: 整数answer: 字符串question: 字符串extended_context: 字符串context: 字符串
- 分割:
train:- 字节数: 11106468810
- 样本数: 29428
- 下载大小: 6843468823
- 数据集大小: 11106468810
Stack-Exchange 配置
- 特征:
text: 字符串meta:language: 字符串question_score: 字符串source: 字符串timestamp: 时间戳url: 字符串
length: 整数ques_ans: 字符串pars:answer: 字符串question: 字符串
question: 字符串answer: 字符串
- 分割:
train:- 字节数: 738769924
- 样本数: 59992
- 下载大小: 383679768
- 数据集大小: 738769924
数据文件
- GPT-3:
train:gpt3/train-*
- GPT-4:
train:gpt4/train-*
- Stack-Exchange:
train:stack-exchange/train-*
许可证
- Apache-2.0
任务类别
- 文本到文本生成
- 文本生成
语言
- 英语
标签
- 代码
- 法律
大小类别
- 100K<n<1M
搜集汇总
数据集介绍
构建方式
Buddhi数据集通过自指导(Self-Instruct)方式生成,结合了GPT-4和GPT-3模型的输出,并整合了Stack Exchange和PG19开源数据集的内容。该数据集旨在训练具有128K上下文窗口的Buddhi-128k-Chat模型,通过YaRN技术扩展了上下文长度,使其能够处理更长的文档和对话。
特点
Buddhi数据集的特点在于其多样化的数据来源和丰富的上下文信息。数据集包含多个配置,如gpt3、gpt4和stack-exchange,每个配置都提供了详细的上下文、扩展上下文、问题和答案字段。这些字段的设计使得数据集特别适用于需要长上下文理解的任务,如文档摘要、叙事生成和复杂问答。
使用方法
使用Buddhi数据集时,用户可以通过HuggingFace平台下载数据集,并根据不同的配置(如gpt3、gpt4和stack-exchange)进行训练和推理。数据集的提示模板要求用户将指令包裹在[INST]和[/INST]标记中,以充分利用指令微调的优势。此外,用户可以参考提供的Colab链接进行vLLM推理,进一步探索模型的长上下文处理能力。
背景与挑战
背景概述
Buddhi数据集是由AI Planet团队开发,旨在支持其128K上下文窗口模型Buddhi-128k-Chat-7B的训练。该数据集结合了GPT-4和GPT-3模型的自指导生成技术,以及Stack Exchange和PG19开源数据集的内容,专注于提升模型在长文本处理和复杂问答任务中的表现。Buddhi-128k-Chat模型基于Mistral 7B Instruct模型进行微调,采用了YaRN技术扩展上下文窗口至128,000个token,使其在处理长文档和对话时具有更强的上下文理解能力。该模型的推出标志着在开源社区中长上下文处理能力的重要进展。
当前挑战
Buddhi数据集面临的挑战主要包括两个方面。首先,在领域问题方面,该数据集旨在解决长文本生成和复杂问答任务中的上下文理解问题,这要求模型能够准确捕捉和利用长距离依赖关系,避免信息丢失或误解。其次,在数据集构建过程中,如何有效地整合和清洗来自不同来源的数据(如Stack Exchange和PG19),确保数据的一致性和高质量,是一个技术难点。此外,扩展模型的上下文窗口至128K token,需要在保持模型性能的同时,优化计算资源的使用,这对算法的设计和实现提出了更高的要求。
常用场景
经典使用场景
Buddhi数据集在自然语言处理领域中被广泛应用于长文本理解和生成任务。其128K的上下文窗口使其特别适合处理需要长期记忆和复杂上下文分析的任务,如长篇文档的摘要生成、多轮对话系统的开发以及复杂的问答系统。通过结合GPT-3和GPT-4的生成能力,该数据集能够提供高质量的文本生成和上下文理解能力,极大地推动了长文本处理技术的发展。
衍生相关工作
Buddhi数据集的推出催生了一系列相关研究工作,特别是在长文本生成和上下文扩展领域。基于Buddhi的模型,研究人员开发了多种改进版本,如NousResearch/Yarn-Mistral-7b-128k和Eric111/Yarn-Mistral-7b-128k-DPO等,这些模型在长文本任务中表现出色。此外,Buddhi的成功也激发了更多关于上下文扩展技术的研究,推动了自然语言处理技术的进一步发展。
数据集最近研究
最新研究方向
在自然语言处理领域,Buddhi数据集的最新研究方向聚焦于扩展上下文窗口的模型优化与应用。通过采用YaRN技术,Buddhi-128k-Chat模型能够处理长达128,000个token的上下文,这一突破性进展为长文档摘要、复杂对话生成及深度问答任务提供了新的可能性。当前研究热点包括如何进一步提升模型在长上下文环境下的推理能力,以及探索其在多领域任务中的泛化性能。此外,结合GPT-4和GPT-3生成的数据,Buddhi数据集在自我指导学习(Self-Instruct)框架下的应用也备受关注,为开放源代码社区提供了高质量的训练资源。这一系列研究不仅推动了长上下文模型的发展,也为大规模语言模型的实际应用开辟了新的路径。
以上内容由遇见数据集搜集并总结生成


