FIG
收藏Hugging Face2025-10-29 更新2025-10-30 收录
下载链接:
https://huggingface.co/datasets/TyangJN/FIG
下载链接
链接失效反馈官方服务:
资源简介:
ORIG数据集是一个用于事实图像生成的事实图像生成评估系统。该数据集通过迭代地从网络中检索多模态证据,并逐步将精炼的知识整合到丰富的提示中,以指导图像生成。数据集包含10个类别,涉及动物、文化、事件、食物、地标、人物、植物、产品、体育和交通等方面。
创建时间:
2025-10-24
原始信息汇总
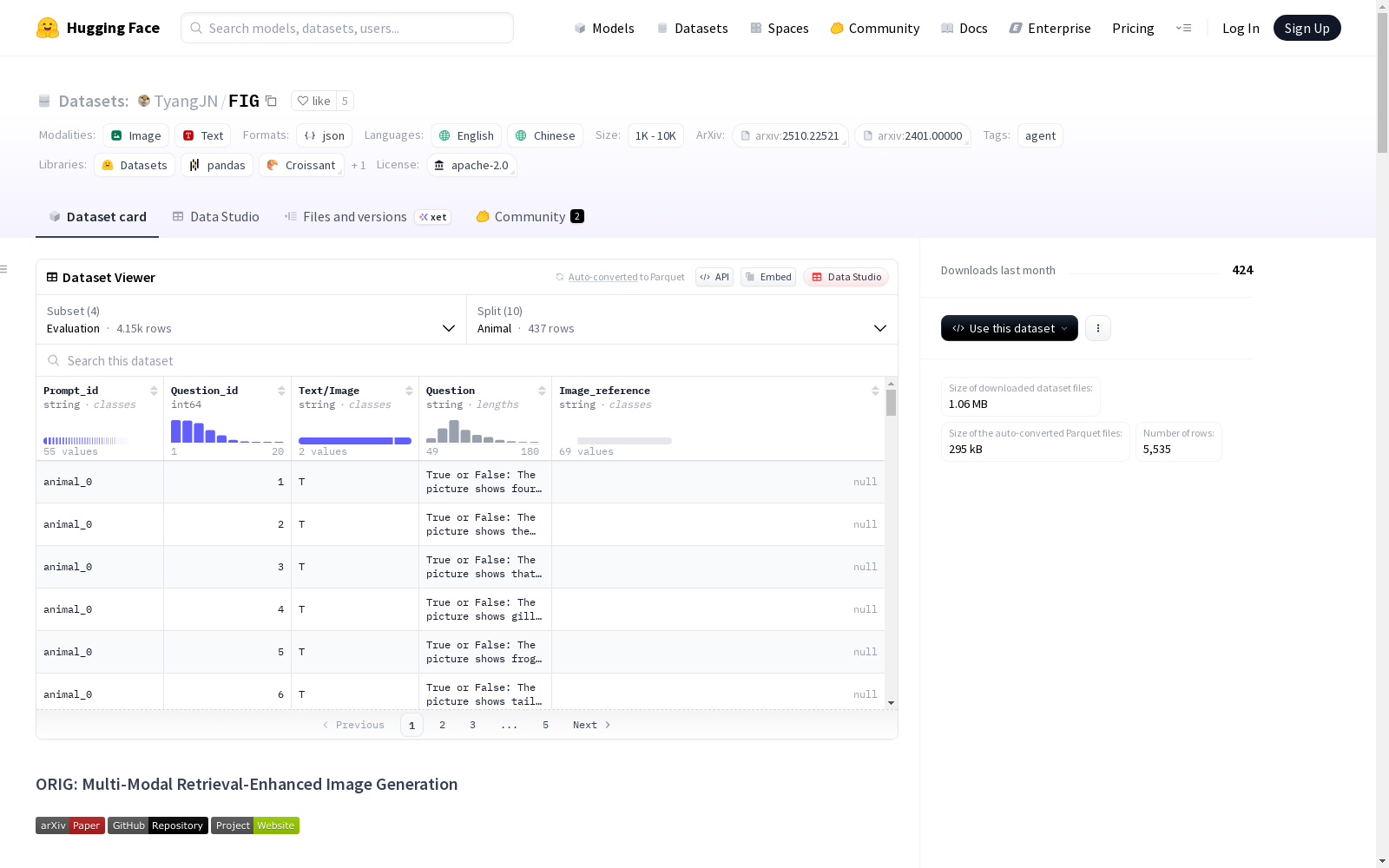
FIG数据集概述
数据集基本信息
- 许可证: Apache-2.0
- 语言: 英语、中文
- 标签: agent
- 数据规模: 1K<n<10K
数据集配置
Prompts配置
- 数据文件: prompts.jsonl
- 分割: prompt
Reference配置
包含10个类别的参考数据:
- Animal: txt/animal/animal_reference.jsonl
- Culture: txt/culture/culture_reference.jsonl
- Event: txt/event/event_reference.jsonl
- Food: txt/food/food_reference.jsonl
- Landmarks: txt/landmarks/landmarks_reference.jsonl
- People: txt/people/people_reference.jsonl
- Plant: txt/plant/plant_reference.jsonl
- Product: txt/product/product_reference.jsonl
- Sports: txt/sports/sports_reference.jsonl
- Transportation: txt/transportation/transportation_reference.jsonl
Evaluation配置
包含10个类别的评估数据:
- Animal: txt/animal/animal_evaluation.jsonl
- Culture: txt/culture/culture_evaluation.jsonl
- Event: txt/event/event_evaluation.jsonl
- Food: txt/food/food_evaluation.jsonl
- Landmarks: txt/landmarks/landmarks_evaluation.jsonl
- People: txt/people/people_evaluation.jsonl
- Plant: txt/plant/plant_evaluation.jsonl
- Product: txt/product/product_evaluation.jsonl
- Sports: txt/sports/sports_evaluation.jsonl
- Transportation: txt/transportation/transportation_evaluation.jsonl
Images配置
- 数据文件: img/img_reference.jsonl
- 分割: Reference
数据集用途
该数据集支持事实性图像生成(FIG)任务的系统评估,涵盖感知、组合和时间维度。
数据集类别
- Animal: 生命周期、行为、栖息地
- Culture: 传统、文物、仪式
- Event: 历史时刻、庆祝活动
- Food: 传统菜肴、制作过程
- Landmarks: 著名建筑、地点
- People: 历史人物、职业
- Plant: 生长阶段、物种
- Product: 设计演变、用途
- Sports: 规则、装备、技术
- Transportation: 车辆演变、操作
搜集汇总
数据集介绍
构建方式
在构建多模态检索增强图像生成数据集时,研究者采用了系统化的方法,通过开放网络动态检索最新信息,并整合文本与图像证据。该过程涉及多轮迭代的证据收集与筛选,确保数据覆盖感知、组合和时间等多个维度。数据集划分为提示、参考和评估三个主要配置,每个配置下细分为动物、文化、事件等十个类别,以支持全面的基准测试。
特点
该数据集具备多模态融合的显著特点,能够结合文本与视觉信息进行事实性验证。其涵盖十个广泛领域,包括动物生命周期、文化传统和交通工具演变等,提供了丰富的语义层次。数据集支持动态更新机制,通过开放网络检索确保信息的时效性,同时采用迭代式证据整合策略,有效提升生成内容的准确性和一致性。
使用方法
用户可通过加载预配置的数据集文件,快速访问不同类别的参考与评估数据。利用提供的管道接口,能够灵活选择检索模型和生成后端,实现多轮证据增强的图像生成。数据集支持本地模型部署,允许自定义检索轮次和批量处理,适用于复杂查询场景下的系统性实验与性能评估。
背景与挑战
背景概述
在人工智能领域,多模态模型的发展虽已实现高度逼真的图像生成,却难以保证生成内容与可验证事实的一致性。为应对这一挑战,研究团队于2024年提出了FIG数据集,聚焦于事实性图像生成任务。该数据集由TyangJN等学者构建,通过开放式多模态检索增强框架,将动态网络信息与视觉生成过程深度融合,覆盖动物、文化、事件等十大知识范畴,显著提升了生成图像在细粒度属性和时效性事件中的事实准确性。
当前挑战
FIG数据集致力于解决多模态生成模型中事实一致性不足的核心难题,其构建面临双重挑战:在领域层面,需克服传统静态知识库对动态演变的现实世界表征的局限性;在技术实现中,则需设计高效的跨模态证据检索机制,并建立能够同步评估视觉质量与事实准确性的多维基准体系。
常用场景
经典使用场景
在跨模态生成研究领域,FIG数据集为评估多模态检索增强的图像生成系统提供了标准化基准。该数据集涵盖动物、文化、事件等十个精细分类,每个类别均包含详实的参考文本与评估标准,能够全面检验模型在感知真实性、组合逻辑性和时间准确性等维度的表现。研究人员通过该数据集可系统评估生成图像与客观事实的一致性,推动多模态理解与生成技术的深度融合。
实际应用
在现实应用层面,FIG数据集支撑的检索增强技术已广泛应用于新闻媒体内容生成、教育可视化材料制作等领域。媒体机构可利用该技术生成具有准确历史背景的新闻配图,教育工作者能快速创建符合科学事实的教学示意图。电子商务平台也借助此类技术生成真实反映产品细节的商品展示图,显著提升了数字内容生产的准确性与效率。
衍生相关工作
基于FIG数据集的研究催生了多模态检索增强生成的技术范式,相关经典工作包括动态知识融合框架、迭代式证据筛选机制等创新方法。这些研究深化了开放域知识获取与视觉内容生成的协同机制理解,推动了如时序一致性生成模型、跨模态事实验证系统等衍生方向的发展,为构建下一代可信赖的多模态人工智能系统提供了重要技术支撑。
以上内容由遇见数据集搜集并总结生成


