myanmar_qna_dataset
收藏Hugging Face2025-12-23 更新2025-12-24 收录
下载链接:
https://huggingface.co/datasets/freococo/myanmar_qna_dataset
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含缅甸语的问答对(QnA),这些问答对是在ChatGPT-5的帮助下生成问题,并使用Gemini 3.0 Pro生成缅甸语问答对。数据集旨在用于研究、AI培训和教育目的。每个条目包含以下字段:'question'(缅甸语的问题文本)、'answer'(缅甸语的对应答案文本)、'total_sentences'(问题和答案中的句子总数)和'qna_id'(每个问答对的唯一标识符)。数据集采用CC0 1.0许可证,可自由用于任何目的,无需署名。
创建时间:
2025-12-22
原始信息汇总
Myanmar QnA Dataset v1 数据集概述
基本信息
- 标题: Myanmar QnA Dataset v1
- 版本: 1.0
- 许可协议: CC0 1.0 (Public Domain)
- 语言: 缅甸语 / 缅甸文 (Burmese / Myanmar)
- 标签: 问答, 缅甸, 缅甸语, 自然语言处理, 机器学习, 数据集, 人工智能, 教育
- 规模类别: 10K<n<100K
- 数据集类型: 文本
- 任务类别: 问答, 文本生成
数据规模
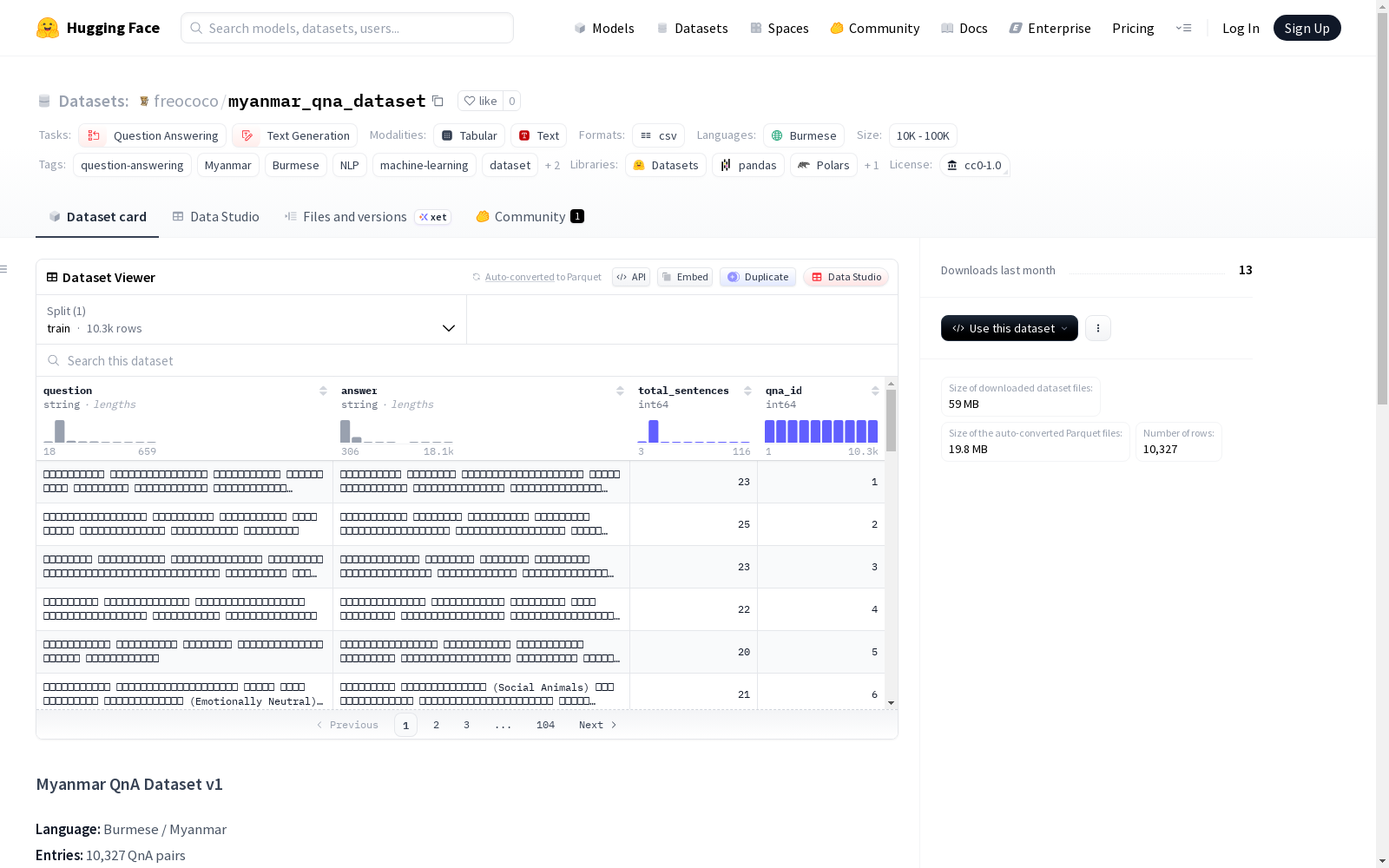
- 条目数量: 10,327 个问答对
- 总句子数: 约 209,447 句
数据描述
该数据集包含缅甸语问答对,借助 ChatGPT-5(用于问题构思)和 Gemini 3.0 Pro(用于缅甸语问答生成)辅助创建。数据集旨在用于研究、人工智能训练和教育目的。
每个条目包含以下字段:
question: 缅甸语问题文本。answer: 对应的缅甸语答案文本。total_sentences: 问题和答案中的句子总数。qna_id: 每个问答对的唯一标识符。
使用方法
可以直接使用 Hugging Face datasets 库加载数据集:
python
from datasets import load_dataset
dataset = load_dataset("freococo/myanmar_qna_dataset")
print(dataset["train"][0])
致谢
- OpenAI 提供 ChatGPT 5,协助构思问题。
- Google 提供 Gemini 3.0 Pro,协助生成缅甸语问答数据集。
- HuggingFace 提供免费平台托管和共享此数据集。
许可声明
本数据集采用 CC0 1.0 许可,这意味着可以自由用于任何目的,无需署名。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,缅甸语问答数据集的构建通常面临资源稀缺的挑战。本数据集通过结合先进的大语言模型技术,采用双阶段生成策略:首先利用ChatGPT-5以英语为媒介设计问题框架,随后借助Gemini 3.0 Pro将问题转化为缅甸语并生成相应的答案,最终形成包含10,327对高质量问答的数据集合。
特点
该数据集专为缅甸语自然语言处理任务设计,其核心特征在于覆盖广泛的问答主题,并确保语言的地道性与文化适应性。每个条目不仅包含完整的问答对,还标注了句子总数与唯一标识符,为研究者提供了结构化的文本分析基础。数据以CC0 1.0许可发布,支持无限制的学术与商业应用。
使用方法
研究人员可通过Hugging Face平台便捷地访问此数据集,使用datasets库直接加载并进行模型训练或评估。该资源适用于问答系统构建、文本生成模型微调及缅甸语语言理解研究,为低资源语言的自然语言处理任务提供了重要的实验数据支撑。
背景与挑战
背景概述
在自然语言处理领域,缅甸语(Burmese)作为低资源语言,长期以来面临公开数据稀缺的困境,制约了相关模型的发展与应用。Myanmar QnA Dataset v1 的创建,正是为了应对这一挑战,由研究者freococo于近期发布,旨在构建一个高质量的缅甸语问答数据集。该数据集利用ChatGPT-5进行问题设计,并借助Gemini 3.0 Pro生成缅甸语问答对,共包含10,327组条目,覆盖约209,447个句子,以CC0 1.0许可公开共享。其核心研究问题聚焦于提升缅甸语问答系统的性能,为机器翻译、教育辅助及本土化AI应用提供关键数据支撑,有望推动东南亚语言处理技术的进步。
当前挑战
该数据集致力于解决缅甸语问答任务中的核心挑战,即低资源语言环境下模型训练数据不足导致的性能瓶颈。具体而言,构建过程中面临多重困难:首先,缅甸语作为复杂脚本语言,其语法结构和词汇资源相对匮乏,自动化生成需克服语言建模的准确性难题;其次,依赖大语言模型如ChatGPT-5和Gemini 3.0 Pro进行跨语言生成,可能引入文化语境偏差或翻译不准确问题,影响数据质量;此外,数据规模虽达万级,但相比高资源语言仍显有限,需进一步扩展以增强模型泛化能力。这些挑战共同凸显了低资源语言数据集开发的复杂性与必要性。
常用场景
实际应用
在实际应用中,该数据集可用于开发智能教育工具、客户服务聊天机器人以及信息检索系统,服务于缅甸语用户群体。例如,在教育领域,它能支持自适应学习平台自动生成练习题与解答;在商业场景中,可增强本地化AI助手的问答能力,提升服务效率与用户体验。
衍生相关工作
基于该数据集,研究者已衍生出多项经典工作,包括缅甸语预训练语言模型的微调、跨语言问答系统的构建以及低资源语言评估基准的设立。这些工作不仅拓展了数据集的效用,还催生了针对东南亚语言的新兴研究方向,为全球NLP社区贡献了宝贵资源。
以上内容由遇见数据集搜集并总结生成


