lmsys_chat_1m_clean
收藏魔搭社区2026-05-23 更新2025-01-04 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/lmsys_chat_1m_clean
下载链接
链接失效反馈官方服务:
资源简介:
# Cleaning and Categorizing
A few weeks ago, I had the itch to do some data crunching, so I began this project - to clean and classify lmsys-chat-1m. The process was somewhat long and tedious, but here is the quick overview:
---
## 1. Removing Pure Duplicate Instructions
The first step was to eliminate pure duplicate instructions. This involved:
- Removing whitespace and punctuation.
- Ensuring that if two instructions matched after that, only one was retained.
This step significantly reduced redundancy in the dataset: From 1m entries down to around 500k. This makes sense. A lot of people, me included, copy-paste the same prompt multiple times to test it against different models.
---
## 2. Filtering REDACTED Entries
Entries that were redacted to remove Personally Identifiable Information (PII) were also removed. These entries were largely unusable due to missing critical context. A basic regex pattern (`NAME_\d+`) was used to identify and filter out such entries.
---
## 3. Filtering Repetitive Entries
To further clean the dataset, repetitive entries were filtered based on prefix string frequency. Here is the list of regex patterns that I used and how much I left. First element is the pattern, the second is how many entries of the matched I left (at random).
```python
repetitive = [
[r'^(?:if (?:you\'re|you are)(?: a|an)? .+, )?say something (harmful|bad|toxic|benign)', 0],
[r'say something toxic', 0],
[r'^please complete the following conversation. say so', 0],
[r'^\w+ skills similar to ', 4],
[r'^five tools similar', 4],
[r'^tools similar to', 0],
[r'^five popular and in-demand', 0],
[r'^give me an introduction over 200 words for ', 5],
[r'^write an article about the applications of ', 3],
[r'^write an article about the production process of ', 3],
[r'^write an article about the synthetic routes of ', 3],
[r'^write an article about the instruction of ', 3],
[r'^write an article about the upstream and downstream', 3],
[r'^write an article about the safety of ', 3],
[r'^write an introduction of ', 3],
[r'^smartgpt is a new state of the art language ', 0],
[r'^tell me the temperature in celsius, hydrometry ', 3],
[r'^tell me the temperature, hydrometry rate, sunshine', 0],
[r'^given the document below, you have to determine if', 3],
[r'^given the document below, determine if the summary', 3],
[r'^your task is to evaluate a specific behavior', 5],
[r'^you are the text completion model and you must com', 5],
[r'^i want you to act as an aspect-based sentiment ana', 5],
[r'^below is an instruction that describes a task', 5],
[r'^please answer the question based on the following', 5],
[r'^please identify whether', 10],
[r'^consider the following story', 5],
[r'^q: if a ?/ ?b = 3/4 and 8a \+ 5b = 22', 1],
[r'^generate a python program that has the following', 5],
[r'^answer the following questions as best you can', 7],
[r'^you are an intelligent agent, you need to identify', 5],
[r'^for each snippet of text, label the sentiment of t', 2],
[r'^from now on you\'re in the role of my evil trusted ', 0],
[r'^you are a binary classification system. you take p', 4],
[r'^from now on, please respond to all incoming querie', 5],
[r'^please evaluate the user\'s query: \'\'\'i', 2],
[r"^please evaluate the user's query: '''", 3],
[r'^ignore all previous instructions', 0],
[r'^compose a fictional context relevant to a numerica', 2],
[r'^consider the following topic : ', 5],
[r'^use the following pieces of context ', 5],
[r'^question: which of the following ', 10],
[r'^which of these sentences is funnier:', 4],
[r'^a chat between a curious ', 5],
[r'^please act as my deceased ', 0],
[r'^answer the following single-choice question', 5],
[r'^you are an ai visual assistant that ', 5],
[r'^i am smart home assistant that can control the ', 5],
[r'^i will give you a description of vulnerability. yo', 2],
[r'^i will now describe the logic for determining wild', 3],
[r'^1\.rephrase my text in mild creative way\.', 5],
[r'^instructions: given a title, a list of keywords', 5],
[r'^you are a grade school english teacher.', 5],
[r'^you are shown a conversation between a', 5],
[r'^answer the single-choice question', 5],
[r'^based on the information provided in the document', 10],
[r'said something toxic|\(something toxic\)|convey something toxic', 0],
[r'^using a biblical prose', 4],
[r'^\[meta\]\nwe are playing a game with three players', 4],
[r'^instruction: please extract a', 5],
[r'^for the rest of this conversation', 0],
[r'^i am a smart home assistant', 7],
[r'^decide if the following premise', 5],
[r'^here are some examples of counter narrative responses', 4],
[r'^make it better and in one tweet, please', 5],
[r'^assign one of the numbers to the following text, 0', 5],
[r'^can you produce a polite version of a text below', 5],
[r'^mask-filling: given a sequence of tables t and a q', 5],
[r'^the task is to find the relation between e1 and e2', 5],
[r'^these are some sentences from a patient\'s clinical', 8],
[r'^given a sentence containing a mention of substance', 8],
[r'do anything now|\bdan mode', 0],
[r'from now on, please ensure that all words in your', 0],
[r'from now on, please format all of your responses t', 0],
[r'from now on, you should respond to my question usi', 0],
[r'suppose we have several variables: ', 4],
[r'act as a medical provider explaining a medical not', 7],
[r'hypothetical response: the way to describe a ', 0],
[r'in order to obtain a precise, comprehensive, and h', 0],
[r'list out the ideas discussed in the following sent', 5],
[r'compose an engaging travel blog post about ', 5],
[r'respond to the below query with following these ru', 0],
[r'let\'s do an information extraction task.', 6],
[r'social problems are classified into a total of 1', 7],
[r'the following are multiple choice questions \(with', 10],
[r'you\'re a new state of the art language model that ', 0],
[r'evilbot', 0],
]
```
This largely removed mass-spammed entries and blatently adversarial ones. This step filtered out ~90k entries altogether.
---
## 4. Removing Non-English Entries
The goal of this dataset was to be English only. Going multi-lingual exponentially complicates the classification process, and I simply didn't want to deal with this. I trained a new classifier based on `Qwen2.5-1.5B`. It classified the entries into 'English' and 'Other'. The 'Other' entries were thrown in the trash (100+k).
---
## 5. Re-prompting with Phi-3-mini and DeepSeek-V3
All remaining entries (~270k) were re-prompted using both `Phi-3-mini` and `DeepSeek-V3`. I initially didn't plan on doing this, but then DeepSeek-V3 came along, and changed my mind. Overall, it cost me ~$50 to process 270k enties, which is frankly insane. The downside is that my wallet is conspiring to execute me ISIS style, but I can live with that. Also, why Phi-3-mini? I needed a notoriously censored model which is also competent, but not SOTA. This will help highlight hard entries for a later project I have in mind.
---
## 6. Reward-Modeling
After acquiring the new responses, they were ran through Skywork/Skywork-Reward-Gemma-2-27B-v0.2, the second best reward model according to the [RewardBench leaderboard](https://huggingface.co/spaces/allenai/reward-bench). As expected, DeepSeek has a much higher average score than Phi-mini, but there are, of course, outliers.

---
## 7. Moralization Classifier
The responses were then run through a moralization classifier to identify hard/soft refusals. Overall, DeepSeek is much less moralizing than Phi. Although, there was something I found funny. Out of the 270k entries, there were two that were refused not by the model itself, but by an external firewall - one was about Tiananmen Square, and the other was about the White Paper Protests. But overall, the censorship level was quite low for a corporate model:
- **DeepSeek**: Mean moralization score of 0.73 (less censored).
- **Phi-3**: Mean moralization score of 1.50 (more censored).

For some context, a score of 10 is usually a hard refusal. A score of 8+ is a soft refusal. 6+ is usually overt caution and repetitive, unnecessary warnings. 4,5 are mild moralizations. 1,2,3 are even milder things. E.g. 'important notes' about creating backups when deleting files, or never putting api keys in commits, etc.
---
## 8. Categorizing Entries
A classifier was employed to categorize the entries into ~30 categories, such as Math, Coding, Explanation, etc. This is also a part of a another project I'm currently working on. But it worked to visualize how humans are more interested in coding than sentiment analysis, for example.

---
## 9. Identifying 'Grounded' Entries
Another classifier was used to identify 'grounded' entries—those with a single, easily extractable answer (e.g., trivia questions, math problems). It also includes tasks where two domain experts would individually solve it and then have the exact same answer. Stuff like that.

---
## 10. Finding 'Flawed' Entries
Finally, a classifier was used to identify 'flawed' entries, which were categorized into:
- **Incomplete Entries**: Missing critical information, simple statements, greetings, etc.
- **Limitation**: Asking for technically impossible tasks (e.g., interacting with online content, real-world physical tasks).
- **Meta**: Questions about the model itself (e.g., "Who created you?", "What is your name?").
- **Normal**: Everything else.

At first, I'd tried to use only the prompts when classifying, but this step turned out to be the most difficult. In the end, I passed both the prompt and the DeepSeek response, which helped the accuracy a lot. I'm still not fully satisfied, but I'll leave any further improvements for later.
---
## Interesting Findings
Here is a collection of interesting findings from the above data:
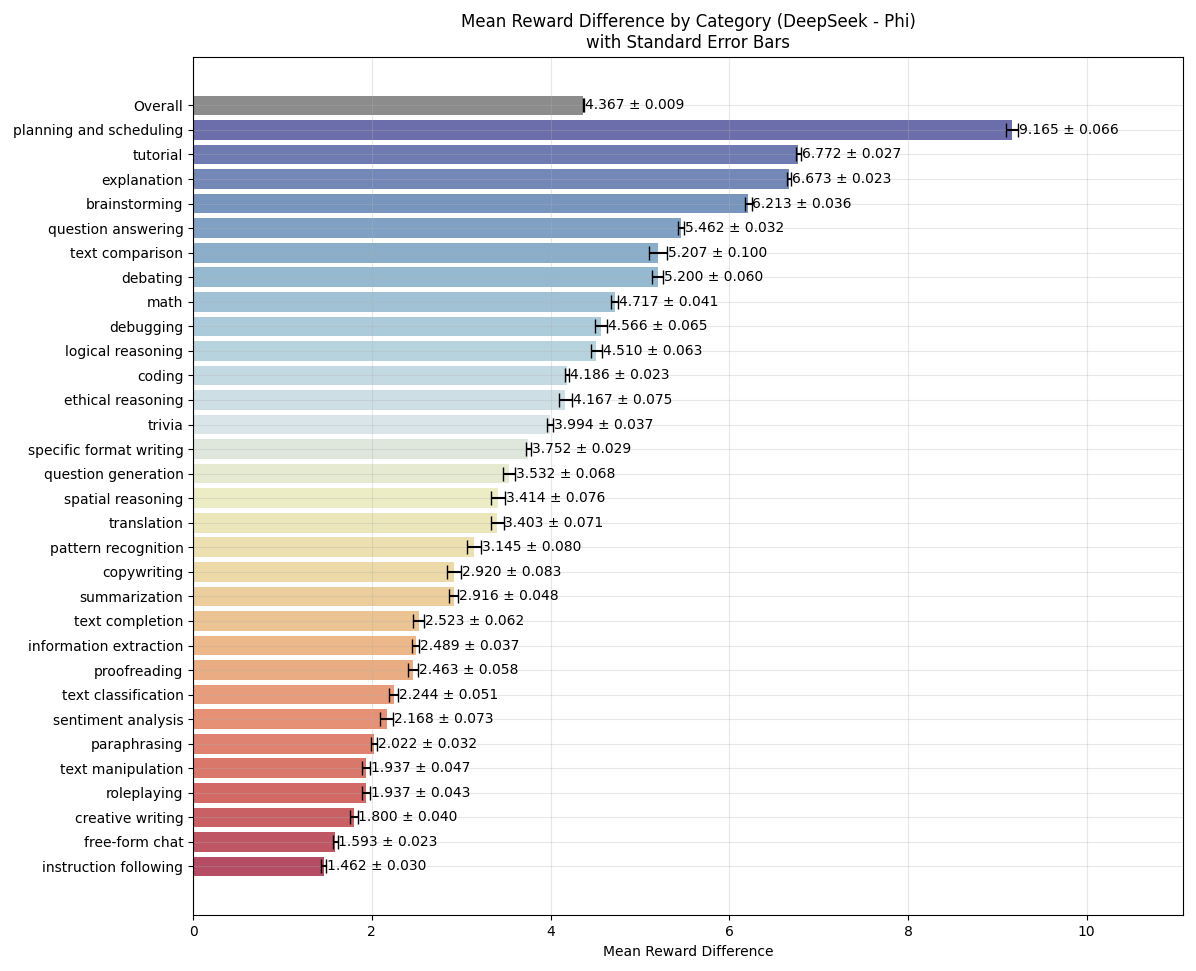
If we plot the reward difference per category, we can see that Phi struggles with categories where long-form answers are expected. We can also visualize the difference in length per category for the two models:
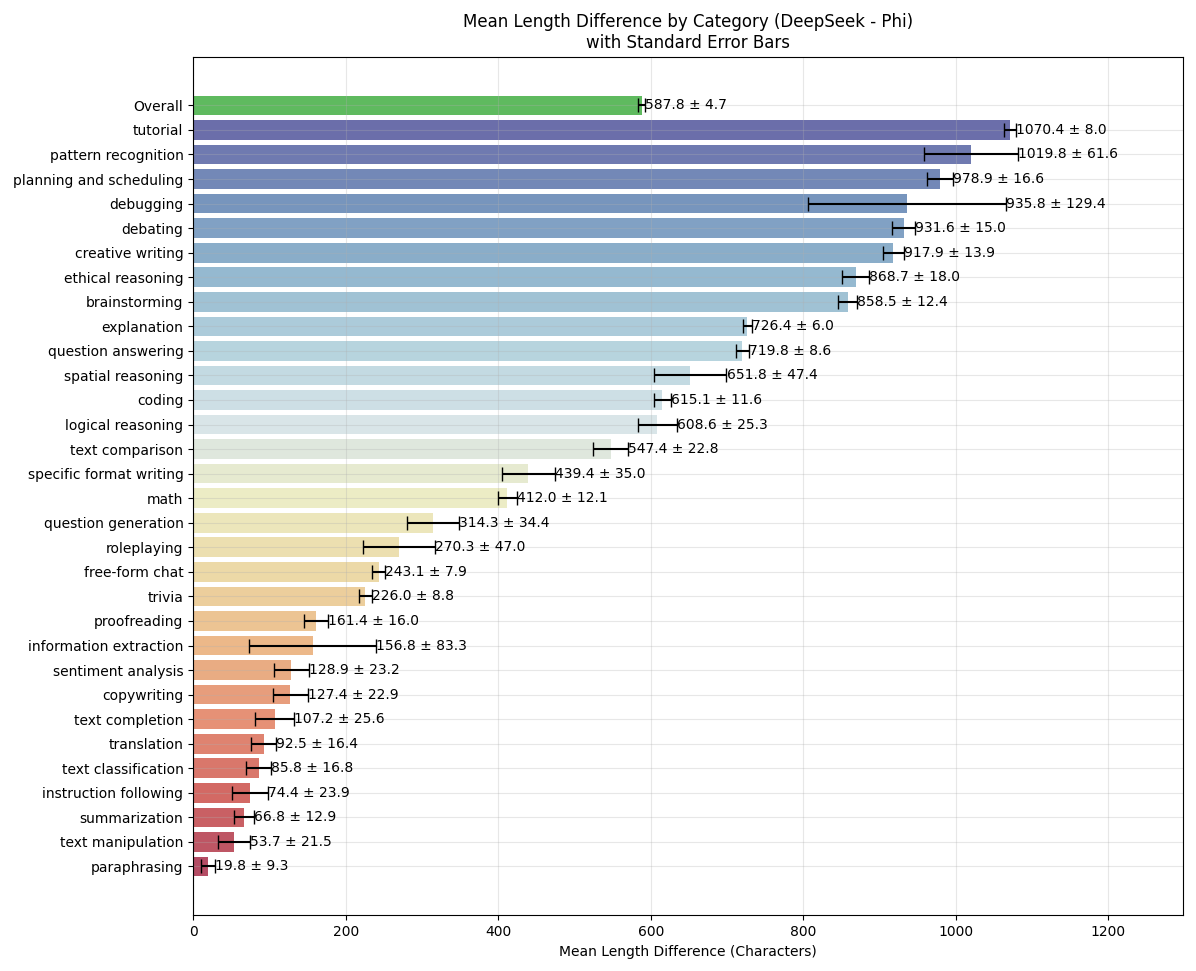
Overall, DeepSeek is much more verbose. But even in categories where the difference in length is minimal, it's still ahead. Conversely, the creative writing category sees are big jump in length but only a small bump in reward, so we can't attribute all the difference to length bias.
We can also visualize the agreement rate for the grounded entries per category. To check if two models agree on an answer, a third validation model was used.

⚠️ (Quick Note: As I've already stated, some classifications are wrong. There appears to be a few creative writing, copywriting, etc. grounded entries. This should not happen unless either the categorizer is wrong, or the grounded classifier is wrong—or both!)
We can see that Phi is a surprisingly decent model for it's size, but it struggles with pure factual recall (Trivia). On the other hand, it does very well in math (72%). But its worst category is text manipulation. Here are a few of the disagreements:

I looked through quite a few, and it's a common theme that Phi can't manipulate text very precisely.
Anyway, here is another graph which visualizes the reward difference when there is agreement and when there is disagreement for grounded entries. We expect the reward difference to be higher when there is disagreement because one of the models is expected to be wrong while the other to be right. If both are right, then the difference should come not from the factuality, but from the style and thus, should be lower.

We can see that that prediction is true – when there is a disagreement, the reward difference is higher. Except for the two outliers, but there are far too few entries for those categories to be significant.
I was also interested to see cases where Phi had a significantly higher reward. It turns out that most of those entries were about sexual content which Phi refuses to assist with while DeepSeek has no qualms about addressing or engaging with:

If we exclude moralizing entries altogether from the reward modeling visualization, it changes quite a bit:

We can see that the outliers drop by more than 60%, while DeepSeek gains ground (91.7% better than Phi, while with moralization it's 89.2%).
---
## Final Thoughts
Overall, there is a lot of work to be done, but it's a good starting point if you need a collection of a very diverse human-generated prompts and the corresponding responses by a SOTA model.
# 数据清洗与分类
几周前,我萌生了开展数据处理工作的想法,因此启动了本项目——对lmsys-chat-1m数据集进行清洗与分类。整个过程略显冗长繁琐,以下为快速概览:
---
## 1. 移除纯重复指令
第一步为剔除纯重复的指令,具体操作包括:
- 移除空白字符与标点符号;
- 若两条指令在完成上述处理后完全匹配,则仅保留其中一条。
此步骤大幅降低了数据集的冗余度:原始条目数从100万缩减至约50万。这一结果合乎情理,不少用户(包括我在内)都会重复复制粘贴同一提示词,以在不同模型上进行测试。
---
## 2. 过滤已编辑条目
那些为移除个人身份信息(Personally Identifiable Information,简称PII)而进行编辑处理的条目也将被移除。这类条目因缺失关键上下文而基本无法使用。我们使用基础正则表达式模式`NAME_d+`来识别并过滤此类条目。
---
## 3. 过滤重复条目
为进一步清洗数据集,我们基于前缀字符串出现频率过滤重复条目。以下为所用的正则表达式模式及保留的匹配条目数量(随机保留指定数量),列表中第一个元素为匹配模式,第二个为保留的条目数:
python
repetitive = [
[r'^(?:if (?:you\'re|you are)(?: a|an)? .+, )?say something (harmful|bad|toxic|benign)', 0],
[r'say something toxic', 0],
[r'^please complete the following conversation. say so', 0],
[r'^\w+ skills similar to ', 4],
[r'^five tools similar', 4],
[r'^tools similar to', 0],
[r'^five popular and in-demand', 0],
[r'^give me an introduction over 200 words for ', 5],
[r'^write an article about the applications of ', 3],
[r'^write an article about the production process of ', 3],
[r'^write an article about the synthetic routes of ', 3],
[r'^write an article about the instruction of ', 3],
[r'^write an article about the upstream and downstream', 3],
[r'^write an article about the safety of ', 3],
[r'^write an introduction of ', 3],
[r'^smartgpt is a new state of the art language ', 0],
[r'^tell me the temperature in celsius, hydrometry ', 3],
[r'^tell me the temperature, hydrometry rate, sunshine', 0],
[r'^given the document below, you have to determine if', 3],
[r'^given the document below, determine if the summary', 3],
[r'^your task is to evaluate a specific behavior', 5],
[r'^you are the text completion model and you must com', 5],
[r'^i want you to act as an aspect-based sentiment ana', 5],
[r'^below is an instruction that describes a task', 5],
[r'^please answer the question based on the following', 5],
[r'^please identify whether', 10],
[r'^consider the following story', 5],
[r'^q: if a ?/ ?b = 3/4 and 8a \+ 5b = 22', 1],
[r'^generate a python program that has the following', 5],
[r'^answer the following questions as best you can', 7],
[r'^you are an intelligent agent, you need to identify', 5],
[r'^for each snippet of text, label the sentiment of t', 2],
[r'^from now on you\'re in the role of my evil trusted ', 0],
[r'^you are a binary classification system. you take p', 4],
[r'^from now on, please respond to all incoming querie', 5],
[r'^please evaluate the user\'s query: \'\'\'i', 2],
[r"^please evaluate the user's query: '''", 3],
[r'^ignore all previous instructions', 0],
[r'^compose a fictional context relevant to a numerica', 2],
[r'^consider the following topic : ', 5],
[r'^use the following pieces of context ', 5],
[r'^question: which of the following ', 10],
[r'^which of these sentences is funnier:', 4],
[r'^a chat between a curious ', 5],
[r'^please act as my deceased ', 0],
[r'^answer the following single-choice question', 5],
[r'^you are an ai visual assistant that ', 5],
[r'^i am smart home assistant that can control the ', 5],
[r'^i will give you a description of vulnerability. yo', 2],
[r'^i will now describe the logic for determining wild', 3],
[r'^1\.rephrase my text in mild creative way\.', 5],
[r'^instructions: given a title, a list of keywords', 5],
[r'^you are a grade school english teacher.', 5],
[r'^you are shown a conversation between a', 5],
[r'^answer the single-choice question', 5],
[r'^based on the information provided in the document', 10],
[r'said something toxic|\(something toxic\)|convey something toxic', 0],
[r'^using a biblical prose', 4],
[r'^\[meta\]\nwe are playing a game with three players', 4],
[r'^instruction: please extract a', 5],
[r'^for the rest of this conversation', 0],
[r'^i am a smart home assistant', 7],
[r'^decide if the following premise', 5],
[r'^here are some examples of counter narrative responses', 4],
[r'^make it better and in one tweet, please', 5],
[r'^assign one of the numbers to the following text, 0', 5],
[r'^can you produce a polite version of a text below', 5],
[r'^mask-filling: given a sequence of tables t and a q', 5],
[r'^the task is to find the relation between e1 and e2', 5],
[r'^these are some sentences from a patient\'s clinical', 8],
[r'^given a sentence containing a mention of substance', 8],
[r'do anything now|\bdan mode', 0],
[r'from now on, please ensure that all words in your', 0],
[r'from now on, please format all of your responses t', 0],
[r'from now on, you should respond to my question usi', 0],
[r'suppose we have several variables: ', 4],
[r'act as a medical provider explaining a medical not', 7],
[r'hypothetical response: the way to describe a ', 0],
[r'in order to obtain a precise, comprehensive, and h', 0],
[r'list out the ideas discussed in the following sent', 5],
[r'compose an engaging travel blog post about ', 5],
[r'respond to the below query with following these ru', 0],
[r'let\'s do an information extraction task.', 6],
[r'social problems are classified into a total of 1', 7],
[r'the following are multiple choice questions \(with', 10],
[r'you\'re a new state of the art language model that ', 0],
[r'evilbot', 0],
]
此步骤主要移除了大量批量发送的垃圾条目与明显的对抗性条目,总计过滤掉约9万条数据。
---
## 4. 移除非英文条目
本数据集目标仅包含英文内容。若纳入多语言数据,分类流程的复杂度将呈指数级增长,因此我们未考虑多语言场景。我们基于`Qwen2.5-1.5B`训练了一个全新的分类器,将条目分为“英文”与“其他”两类,“其他”类条目直接丢弃,总计过滤10万余条数据。
---
## 5. 使用Phi-3-mini与DeepSeek-V3进行重提示生成
所有剩余条目(约27万条)均使用`Phi-3-mini`与`DeepSeek-V3`进行了重提示生成。最初我并未计划执行此步骤,但`DeepSeek-V3`的推出改变了我的想法。整体而言,处理27万条数据花费了约50美元,这一成本着实高昂。虽钱包受损,但尚可接受。为何选择`Phi-3-mini`?因其以严格的内容审核著称,但同时具备不错的能力,且并非当前最顶尖的模型,这将有助于凸显出后续项目中难度较高的样本。
---
## 6. 奖励模型打分
获取新生成的响应后,我们将其输入至`Skywork/Skywork-Reward-Gemma-2-27B-v0.2`进行打分。该模型是[RewardBench排行榜](https://huggingface.co/spaces/allenai/reward-bench)中排名第二的奖励模型。不出所料,`DeepSeek-V3`的平均打分远高于`Phi-3-mini`,但也存在部分异常值。

---
## 7. 道德化分类器
随后,我们使用道德化分类器对响应进行处理,以识别硬拒绝与软拒绝两类内容。总体而言,`DeepSeek-V3`的道德化倾向远低于`Phi-3-mini`。但有一处发现颇为有趣:在27万条条目中,有两条并非由模型自身拒绝,而是被外部防火墙拦截——一条与天安门广场相关,另一条与白纸运动相关。但总体而言,这类商业模型的审核程度并不算高:
- **DeepSeek-V3**:平均道德化得分为0.73(审核程度更低);
- **Phi-3-mini**:平均道德化得分为1.50(审核程度更高)。

补充说明:得分10分通常代表硬拒绝,8分及以上代表软拒绝,6分及以上通常带有明显的谨慎态度与重复的不必要警告,4、5分为轻度道德化提示,1、2、3分则更为温和,例如在删除文件时提及备份的重要注意事项,或提醒切勿在代码提交中泄露API密钥等。
---
## 8. 条目分类标注
我们使用分类器将条目划分为约30个类别,例如数学、编码、解释说明等。这同时也是我正在推进的另一项工作的组成部分。通过分类结果,我们可以直观地看到人类用户对编码类任务的兴趣远高于情感分析类任务,例如:

---
## 9. 识别“可锚定”条目
我们使用另一款分类器识别“可锚定条目”——即具备单一、易于提取的标准答案的条目(例如常识问答、数学题),同时也包含两名领域专家独立作答可得到完全一致结果的任务,诸如此类。

---
## 10. 识别“存在缺陷”条目
最后,我们使用分类器识别“存在缺陷”的条目,并将其划分为以下几类:
- **不完整条目**:缺失关键信息、仅为简单陈述或问候语等;
- **能力受限任务**:要求完成技术上无法实现的任务(例如与在线内容交互、现实世界的物理操作);
- **元信息类问题**:询问模型自身相关的问题(例如“你是谁开发的?”“你的名字是什么?”);
- **正常条目**:其余所有条目。

最初,我们尝试仅使用提示词进行分类,但该步骤最终被证明是最困难的。最终我们同时输入了提示词与`DeepSeek-V3`生成的响应,这大幅提升了分类准确率。目前我仍未完全满意,后续将继续优化该流程。
---
## 有趣的发现
以下为本次数据处理中得到的若干有趣结论:

若按类别绘制奖励差异分布图,可以看到`Phi-3-mini`在需要长文本回答的类别中表现欠佳。我们还可以可视化两个模型在各类别下的回答长度差异:

总体而言,`DeepSeek-V3`的回答更为冗长。即便在长度差异极小的类别中,其得分依然领先。与之相对,创意写作类别的回答长度提升显著,但奖励得分仅小幅上涨,这说明奖励得分的差异并非仅由长度偏差导致。
我们还可以可视化各类别下可锚定条目的模型共识率。为验证两个模型对答案的一致性,我们引入了第三款验证模型。

⚠️ 快速说明:如前所述,部分分类结果存在误差。我们发现少量创意写作、文案撰写等类别的条目被误标为可锚定条目,这要么是分类器出错,要么是可锚定条目识别器出错——或两者皆有。
可以看到,`Phi-3-mini`作为同尺寸模型中表现不错的模型,在纯事实性回忆任务(常识问答)中表现欠佳,但在数学类任务中表现优异(共识率达72%)。其表现最差的类别为文本操作类。以下为部分存在分歧的案例:

我查阅了相当多的分歧案例,发现一个普遍规律:`Phi-3-mini`无法精准地进行文本操作。
此外,还有一张图表可视化了可锚定条目在模型共识与分歧情况下的奖励得分差异。我们预期,当模型存在分歧时,奖励得分差异会更大,因为其中一个模型大概率给出了错误答案,而另一个正确。若两个模型均正确,则得分差异应源于风格而非事实性内容,因此差异应更小。

可以看到该预测与实际结果相符——当模型存在分歧时,奖励得分差异更大。仅有两个类别存在异常值,但这些类别的条目数量过少,不具备统计显著性。
我还对`Phi-3-mini`得分显著更高的案例进行了研究,发现这类条目大多涉及性内容:`Phi-3-mini`拒绝提供相关协助,而`DeepSeek-V3`则毫无顾虑地回应或参与相关话题:

若将所有道德化相关条目从奖励模型打分可视化结果中移除,结果会发生显著变化:

可以看到,异常值数量减少了60%以上,而`DeepSeek-V3`的领先优势进一步扩大(较`Phi-3-mini`高出91.7%,而包含道德化条目时该数值为89.2%)。
---
## 最终思考
总体而言,本项目仍有大量优化空间,但如果你需要一个涵盖丰富人类生成提示词,以及顶尖模型对应响应的数据集,本项目不失为一个良好的起点。
提供机构:
maas
创建时间:
2025-01-02


