genia-vdg/genia-dataset-02-v4
收藏Hugging Face2024-05-08 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/genia-vdg/genia-dataset-02-v4
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 2001945.0
num_examples: 91
download_size: 1659630
dataset_size: 2001945.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
数据集信息:
数据特征:
- 特征名称:图像(image),数据类型:图像
- 特征名称:文本(text),数据类型:字符串(string)
数据集划分:
- 划分名称:训练集(train),字节占用量:2001945.0,样本数量:91
下载大小:1659630
数据集存储总大小:2001945.0
配置项:
- 配置名称:默认(default),数据文件:
- 对应划分:训练集(train),文件路径:data/train-*
提供机构:
genia-vdg
原始信息汇总
数据集概述
数据集特征
- image: 数据类型为图像。
- text: 数据类型为字符串。
数据集划分
- train:
- 示例数量: 91
- 数据大小: 2001945.0 字节
数据集大小
- 下载大小: 1659630 字节
- 数据集总大小: 2001945.0 字节
配置信息
- config_name: default
- data_files:
- split: train
- path: data/train-*
- split: train
- data_files:
搜集汇总
数据集介绍
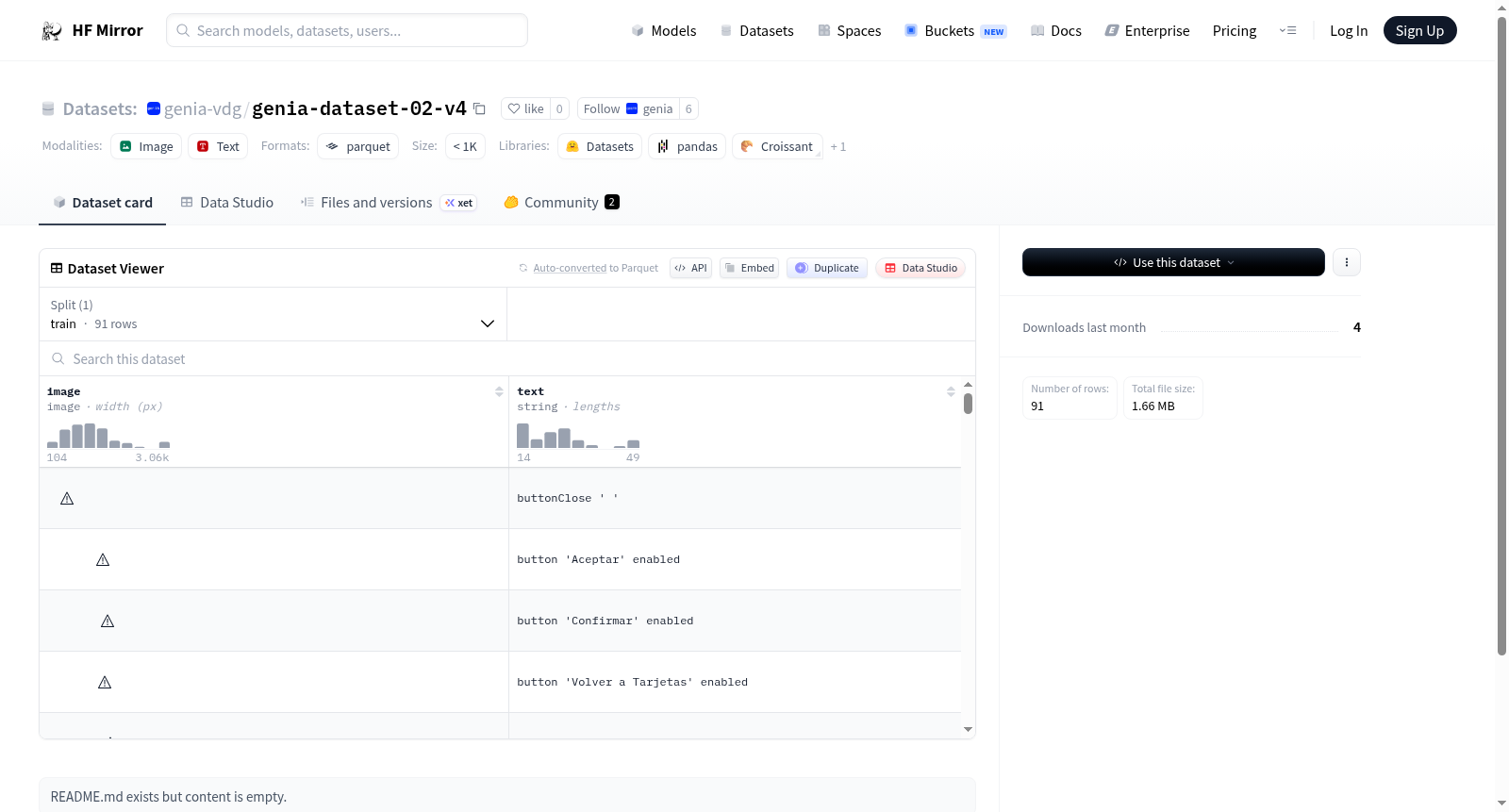
构建方式
在生物医学图像分析领域,数据集的构建需兼顾视觉与文本信息的精准对齐。该数据集通过专业采集流程,整合了91个训练样本,每个样本包含图像及其对应的文本描述。数据以图像和字符串文本作为核心特征,采用标准化的文件结构进行组织,确保数据的一致性与可访问性。构建过程中注重数据的原始性与完整性,为后续分析提供了可靠的基础。
特点
该数据集以图像与文本的双模态结构为显著特点,图像数据以原始视觉形式呈现,文本则提供详尽的描述信息。样本规模虽小但内容精炼,覆盖了特定生物医学场景,便于深入分析与模型训练。数据分割仅包含训练集,强调其在开发阶段的实用性,文件格式统一且下载体积适中,适合快速部署与实验验证。
使用方法
使用该数据集时,可直接通过HuggingFace平台加载,利用其默认配置访问训练数据。图像与文本字段可分别用于视觉特征提取和自然语言处理任务,支持跨模态学习方法的探索。由于数据已预处理并结构化,用户可专注于模型构建与评估,无需额外清理步骤,从而提升研究效率。
背景与挑战
背景概述
GENIA数据集是生物医学自然语言处理领域的基石性资源,由日本东京大学的研究团队于二十一世纪初创建,旨在应对生物医学文献中复杂术语与关系的解析难题。该数据集聚焦于生物分子交互、基因调控网络等核心研究问题,通过系统标注蛋白质、DNA等生物实体及其相互作用,极大地推动了信息抽取、文本挖掘等技术的发展,为后续生物医学知识图谱的构建奠定了坚实的数据基础。
当前挑战
该数据集所应对的领域挑战在于生物医学文本中普遍存在的术语歧义性、命名不规范以及句法结构复杂性,这些因素使得自动信息抽取的准确性与召回率难以提升。在构建过程中,研究人员面临的主要挑战包括生物实体边界的精确界定、交互关系标注标准的一致性维护,以及跨文献的标注质量统一,这些都需要领域专家投入大量精力进行人工校验与迭代优化。
常用场景
经典使用场景
在生物医学信息学领域,图像与文本的跨模态关联分析是理解复杂生物过程的关键。该数据集通过整合视觉图像与描述性文本,为研究人员提供了一个经典的多模态学习平台,常用于训练模型以识别生物结构图像中的关键特征,并自动生成或匹配相应的文本描述,从而促进生物医学知识的可视化表达与自动化解析。
实际应用
在实际应用中,该数据集可服务于生物医学教育、临床诊断辅助以及科研文献自动化处理等场景。例如,在医学教学中,模型能够根据图像自动生成解说文本,辅助学习者理解微观生物结构;在科研中,它可帮助快速检索和注解大量的生物图像资料,提升研究效率与知识管理能力。
衍生相关工作
围绕该数据集,学术界已衍生出多项经典研究工作,主要集中在多模态预训练模型、生物医学图像字幕生成以及跨模态检索等领域。这些工作不仅深化了对生物医学数据的理解,还催生了新的算法框架,如基于注意力机制的图像-文本对齐模型,为后续生物信息学工具的开发提供了重要参考。
以上内容由遇见数据集搜集并总结生成


