ChatQA-Training-Data
收藏魔搭社区2025-12-10 更新2025-01-25 收录
下载链接:
https://modelscope.cn/datasets/nv-community/ChatQA-Training-Data
下载链接
链接失效反馈官方服务:
资源简介:
## Data Description
We release the training dataset of [ChatQA](https://arxiv.org/pdf/2401.10225). It is built and derived from existing datasets: [DROP](https://arxiv.org/abs/1903.00161), [NarrativeQA](https://arxiv.org/abs/1712.07040), [NewsQA](https://arxiv.org/abs/1611.09830), [Quoref](https://arxiv.org/abs/1908.05803), [ROPES](https://arxiv.org/abs/1908.05852), [SQuAD1.1](https://arxiv.org/abs/1606.05250), [SQuAD2.0](https://arxiv.org/abs/1806.03822), [TAT-QA](https://arxiv.org/abs/2105.07624), a SFT dataset, as well as a our synthetic conversational QA dataset by GPT-3.5-turbo-0613. The SFT dataset is built and derived from: [Soda](https://arxiv.org/abs/2212.10465), [ELI5](https://arxiv.org/abs/1907.09190), [FLAN](https://arxiv.org/abs/2210.11416), [the FLAN collection](https://arxiv.org/abs/2301.13688), [Self-Instruct](https://arxiv.org/abs/2212.10560), [Unnatural Instructions](https://arxiv.org/abs/2212.09689), [OpenAssistant](https://arxiv.org/abs/2304.07327), and [Dolly](https://github.com/databrickslabs/dolly). **For more information about ChatQA, check the [website](https://chatqa-project.github.io/)!**
## Other Resources
[Llama3-ChatQA-1.5-8B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-8B)   [Llama3-ChatQA-1.5-70B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-70B)   [Evaluation Data](https://huggingface.co/datasets/nvidia/ChatRAG-Bench)   [Retriever](https://huggingface.co/nvidia/dragon-multiturn-query-encoder)   [Website](https://chatqa-project.github.io/)   [Paper](https://arxiv.org/pdf/2401.10225)
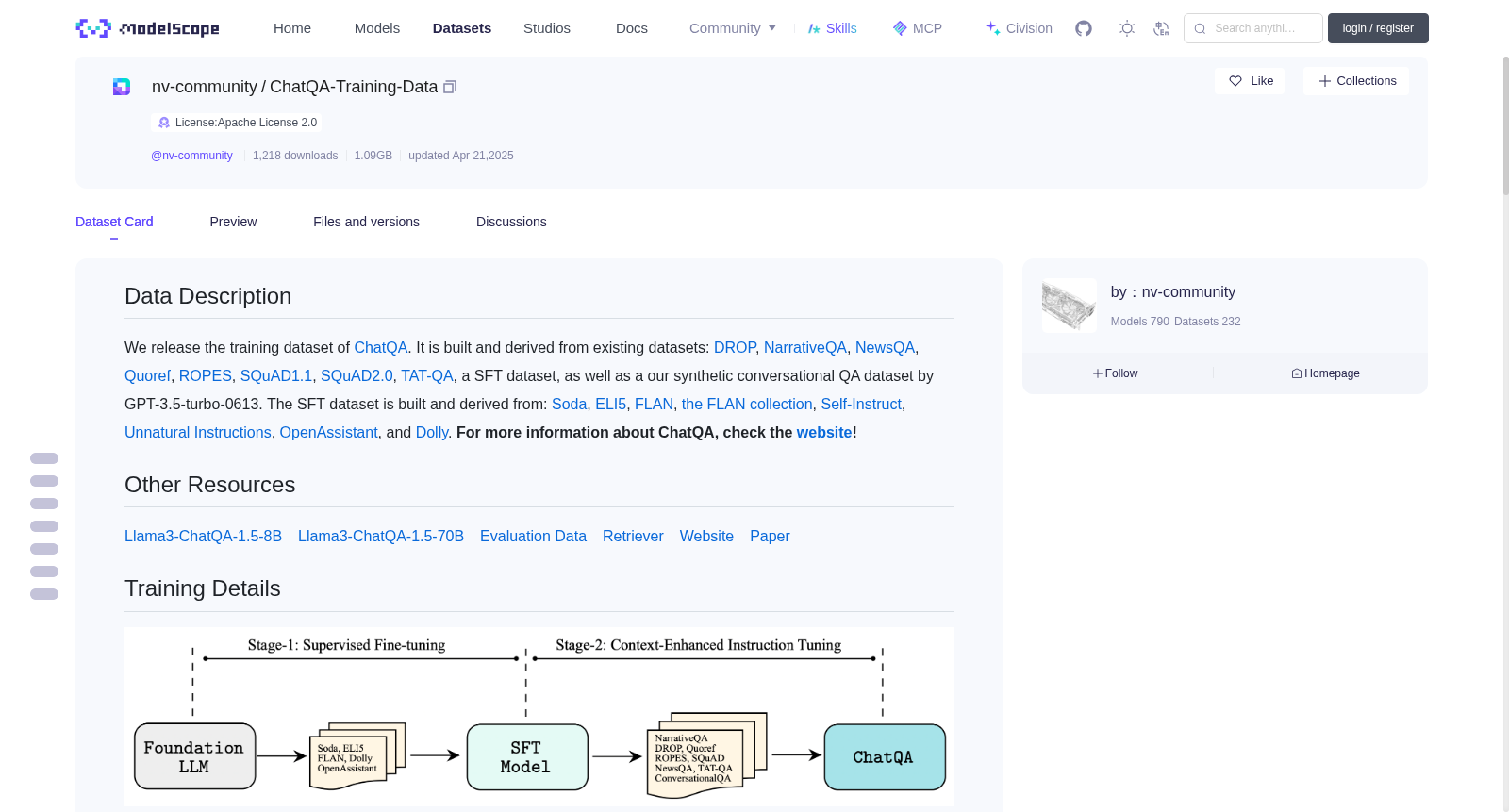
## Training Details
<img src="framework.png" width=100%/>
The training follows a two-stage instruction tuning process. The stage-1 uses the SFT data, and the stage-2 uses a blend of SFT data alongside other datasets. The dataset blending ratio for stage-2 is as follows:
- drop: 0.069
- narrativeqa: 0.095
- quoref: 0.026
- ropes: 0.026
- squad1.1: 0.095
- squad2.0: 0.095
- newsqa: 0.095
- tatqa-arithmetic: 0.15
- tatqa-others: 0.08
- synthetic_convqa: 0.3
- sft: 0.2
In stage-2 training, we add specific instructions for the user turn for different types of datasets. Specifically, we add
- ```"Answer the following question with a short span"``` for datasets that have short answers (i.e., drop, narrativeqa, quoref, ropes, squad1.1, squad2.0, newsqa).
- ```"Please give a full and complete answer for the question"``` for the dataset that has a long answer (i.e., synthetic_convqa).
- ```"Answer the following question with a number from context or the math arithmetic"``` for the dataset that requires arithmetic calculation or extracting numbers from the context (i.e., tatqa-arithmetic).
- ```"Answer the following question with a short span, or a full and complete answer"``` for the dataset that has both short and long answers (i.e., tatqa-others).
**UPDATED: We added training config files for [stage-1](https://huggingface.co/datasets/nvidia/ChatQA-Training-Data/blob/main/training_config_stage1.yaml) and [stage-2](https://huggingface.co/datasets/nvidia/ChatQA-Training-Data/blob/main/training_config_stage2.yaml).** Note that the models were originally trained using [Megatron-LM](https://github.com/NVIDIA/Megatron-LM), and more information about the training arguments can be found [here](https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/training/arguments.py).
## License
The synthetic conversational QA dataset is for non-commercial use only, subject to [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI. The rest of the datasets are built on and derived from existing datasets. We refer users to the original licenses accompanying each dataset.
## Correspondence to
Zihan Liu (zihanl@nvidia.com), Wei Ping (wping@nvidia.com)
## Citation
<pre>
@article{liu2024chatqa,
title={ChatQA: Surpassing GPT-4 on Conversational QA and RAG},
author={Liu, Zihan and Ping, Wei and Roy, Rajarshi and Xu, Peng and Lee, Chankyu and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2401.10225},
year={2024}}
</pre>
## Acknowledgement
We would like to give credits to all the works constructing the datasets we use for training ChatQA. If you use these resources, please also cite all the datasets you use.
<pre>
@inproceedings{dua2019drop,
title={DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs},
author={Dua, Dheeru and Wang, Yizhong and Dasigi, Pradeep and Stanovsky, Gabriel and Singh, Sameer and Gardner, Matt},
booktitle={Proceedings of the 2019 Conference on NAACL},
year={2019}
}
@article{kocisky2018narrativeqa,
title={The NarrativeQA Reading Comprehension Challenge},
author={Kocisky, Tomas and Schwarz, Jonathan and Blunsom, Phil and Dyer, Chris and Hermann, Karl Moritz and Melis, Gabor and Grefenstette, Edward},
journal={Transactions of the Association for Computational Linguistics},
year={2018}
}
@inproceedings{dasigi2019quoref,
title={Quoref: A Reading Comprehension Dataset with Questions Requiring Coreferential Reasoning},
author={Dasigi, Pradeep and Liu, Nelson F and Marasovi{\'c}, Ana and Smith, Noah A and Gardner, Matt},
booktitle={Proceedings of the 2019 Conference on EMNLP},
year={2019}
}
@inproceedings{lin2019reasoning,
title={Reasoning Over Paragraph Effects in Situations},
author={Lin, Kevin and Tafjord, Oyvind and Clark, Peter and Gardner, Matt},
booktitle={Proceedings of the 2nd Workshop on Machine Reading for Question Answering},
year={2019}
}
@inproceedings{rajpurkar2016squad,
title={SQuAD: 100,000+ Questions for Machine Comprehension of Text},
author={Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy},
booktitle={Proceedings of the 2016 Conference on EMNLP},
year={2016}
}
@inproceedings{rajpurkar2018know,
title={Know What You Don’t Know: Unanswerable Questions for SQuAD},
author={Rajpurkar, Pranav and Jia, Robin and Liang, Percy},
booktitle={Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics},
pages={784--789},
year={2018}
}
@inproceedings{trischler2017newsqa,
title={NewsQA: A Machine Comprehension Dataset},
author={Trischler, Adam and Wang, Tong and Yuan, Xingdi and Harris, Justin and Sordoni, Alessandro and Bachman, Philip and Suleman, Kaheer},
booktitle={Proceedings of the 2nd Workshop on Representation Learning for NLP},
year={2017}
}
@inproceedings{zhu2021tat,
title={TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance},
author={Zhu, Fengbin and Lei, Wenqiang and Huang, Youcheng and Wang, Chao and Zhang, Shuo and Lv, Jiancheng and Feng, Fuli and Chua, Tat-Seng},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics},
year={2021}
}
@inproceedings{kim2023soda,
title={SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization},
author={Kim, Hyunwoo and Hessel, Jack and Jiang, Liwei and West, Peter and Lu, Ximing and Yu, Youngjae and Zhou, Pei and Bras, Ronan and Alikhani, Malihe and Kim, Gunhee and others},
booktitle={Proceedings of the 2023 Conference on EMNLP},
year={2023}
}
@inproceedings{fan2019eli5,
title={ELI5: Long Form Question Answering},
author={Fan, Angela and Jernite, Yacine and Perez, Ethan and Grangier, David and Weston, Jason and Auli, Michael},
booktitle={Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics},
year={2019}
}
@article{chung2024scaling,
title={Scaling instruction-finetuned language models},
author={Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Yunxuan and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and others},
journal={Journal of Machine Learning Research},
year={2024}
}
@inproceedings{longpre2023flan,
title={The flan collection: Designing data and methods for effective instruction tuning},
author={Longpre, Shayne and Hou, Le and Vu, Tu and Webson, Albert and Chung, Hyung Won and Tay, Yi and Zhou, Denny and Le, Quoc V and Zoph, Barret and Wei, Jason and others},
booktitle={International Conference on Machine Learning},
year={2023},
}
@inproceedings{wang2023self,
title={Self-Instruct: Aligning Language Models with Self-Generated Instructions},
author={Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A and Khashabi, Daniel and Hajishirzi, Hannaneh},
booktitle={Proceedings of the 61st Annual Meeting Of The Association For Computational Linguistics},
year={2023}
}
@inproceedings{honovich2023unnatural,
title={Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor},
author={Honovich, Or and Scialom, Thomas and Levy, Omer and Schick, Timo},
booktitle={Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics},
year={2023}
}
@article{kopf2024openassistant,
title={Openassistant conversations-democratizing large language model alignment},
author={K{\"o}pf, Andreas and Kilcher, Yannic and von R{\"u}tte, Dimitri and Anagnostidis, Sotiris and Tam, Zhi Rui and Stevens, Keith and Barhoum, Abdullah and Nguyen, Duc and Stanley, Oliver and Nagyfi, Rich{\'a}rd and others},
journal={Advances in Neural Information Processing Systems},
year={2024}
}
@online{DatabricksBlog2023DollyV2,
author = {Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin},
title = {Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM},
year = {2023},
url = {https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm},
urldate = {2023-06-30}
}
</pre>
## 数据集说明
我们发布了[ChatQA](https://arxiv.org/pdf/2401.10225)的训练数据集。该数据集构建并衍生自以下现有数据集:[DROP](https://arxiv.org/abs/1903.00161)、[NarrativeQA](https://arxiv.org/abs/1712.07040)、[NewsQA](https://arxiv.org/abs/1611.09830)、[Quoref](https://arxiv.org/abs/1908.05803)、[ROPES](https://arxiv.org/abs/1908.05852)、[SQuAD1.1](https://arxiv.org/abs/1606.05250)、[SQuAD2.0](https://arxiv.org/abs/1806.03822)、[TAT-QA](https://arxiv.org/abs/2105.07624)这一监督微调(Supervised Fine-Tuning, SFT)数据集,以及我们基于GPT-3.5-turbo-0613构建的合成式对话问答数据集。
该监督微调数据集同样构建并衍生自:[Soda](https://arxiv.org/abs/2212.10465)、[ELI5](https://arxiv.org/abs/1907.09190)、[FLAN](https://arxiv.org/abs/2210.11416)、[FLAN合集](https://arxiv.org/abs/2301.13688)、[Self-Instruct](https://arxiv.org/abs/2212.10560)、[Unnatural Instructions](https://arxiv.org/abs/2212.09689)、[OpenAssistant](https://arxiv.org/abs/2304.07327)以及[Dolly](https://github.com/databrickslabs/dolly)。**如需了解ChatQA的更多详情,请访问[官方网站](https://chatqa-project.github.io/)!**
## 其他资源
[Llama3-ChatQA-1.5-8B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-8B)   [Llama3-ChatQA-1.5-70B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-70B)   [评估数据集](https://huggingface.co/datasets/nvidia/ChatRAG-Bench)   [检索器](https://huggingface.co/nvidia/dragon-multiturn-query-encoder)   [官方网站](https://chatqa-project.github.io/)   [论文](https://arxiv.org/pdf/2401.10225)
## 训练细节
<img src="framework.png" width=100%/>
训练采用两阶段指令微调流程。第一阶段使用监督微调数据,第二阶段则混合使用监督微调数据与其他数据集。第二阶段的数据集混合比例如下:
- DROP:0.069
- NarrativeQA:0.095
- Quoref:0.026
- ROPES:0.026
- SQuAD1.1:0.095
- SQuAD2.0:0.095
- NewsQA:0.095
- TAT-QA-算术型:0.15
- TAT-QA-其他型:0.08
- 合成式对话问答:0.3
- SFT:0.2
在第二阶段训练中,我们针对不同类型的数据集为用户交互轮次添加了特定指令。具体而言,我们为以下数据集添加对应指令:
- 针对拥有短片段答案的数据集(即DROP、NarrativeQA、Quoref、ROPES、SQuAD1.1、SQuAD2.0、NewsQA),添加:"请以简短片段回答以下问题"
- 针对拥有长文本答案的数据集(即合成式对话问答数据集),添加:"请针对该问题给出完整详尽的回答"
- 针对需要算术计算或从上下文中提取数字的数据集(即TAT-QA-算术型),添加:"请从上下文或通过数学运算得出的结果中选取数字回答以下问题"
- 针对同时包含短片段答案与长文本答案的数据集(即TAT-QA-其他型),添加:"请以简短片段或完整详尽的回答以下问题"
**更新:我们已为[第一阶段](https://huggingface.co/datasets/nvidia/ChatQA-Training-Data/blob/main/training_config_stage1.yaml)和[第二阶段](https://huggingface.co/datasets/nvidia/ChatQA-Training-Data/blob/main/training_config_stage2.yaml)添加了训练配置文件。** 请注意,模型最初使用[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)进行训练,有关训练参数的更多详情可参见[官方文档](https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/training/arguments.py)。
## 许可协议
本合成式对话问答数据集仅可用于非商业用途,需遵守OpenAI生成数据的[使用条款](https://openai.com/policies/terms-of-use)。其余数据集均构建并衍生自现有公开数据集,我们建议用户查阅各数据集附带的原始许可协议。
## 通讯作者
刘梓涵(zihanl@nvidia.com)、平伟(wping@nvidia.com)
## 引用
<pre>
@article{liu2024chatqa,
title={ChatQA: Surpassing GPT-4 on Conversational QA and RAG},
author={Liu, Zihan and Ping, Wei and Roy, Rajarshi and Xu, Peng and Lee, Chankyu and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2401.10225},
year={2024}}
</pre>
## 致谢
我们向所有用于构建ChatQA训练数据集的相关研究工作致以诚挚谢意。若您使用本资源,请同时引用您所使用的全部数据集。
<pre>
@inproceedings{dua2019drop,
title={DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs},
author={Dua, Dheeru and Wang, Yizhong and Dasigi, Pradeep and Stanovsky, Gabriel and Singh, Sameer and Gardner, Matt},
booktitle={Proceedings of the 2019 Conference on NAACL},
year={2019}
}
@article{kocisky2018narrativeqa,
title={The NarrativeQA Reading Comprehension Challenge},
author={Kocisky, Tomas and Schwarz, Jonathan and Blunsom, Phil and Dyer, Chris and Hermann, Karl Moritz and Melis, Gabor and Grefenstette, Edward},
journal={Transactions of the Association for Computational Linguistics},
year={2018}
}
@inproceedings{dasigi2019quoref,
title={Quoref: A Reading Comprehension Dataset with Questions Requiring Coreferential Reasoning},
author={Dasigi, Pradeep and Liu, Nelson F and Marasovic, Ana and Smith, Noah A and Gardner, Matt},
booktitle={Proceedings of the 2019 Conference on EMNLP},
year={2019}
}
@inproceedings{lin2019reasoning,
title={Reasoning Over Paragraph Effects in Situations},
author={Lin, Kevin and Tafjord, Oyvind and Clark, Peter and Gardner, Matt},
booktitle={Proceedings of the 2nd Workshop on Machine Reading for Question Answering},
year={2019}
}
@inproceedings{rajpurkar2016squad,
title={SQuAD: 100,000+ Questions for Machine Comprehension of Text},
author={Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy},
booktitle={Proceedings of the 2016 Conference on EMNLP},
year={2016}
}
@inproceedings{rajpurkar2018know,
title={Know What You Don’t Know: Unanswerable Questions for SQuAD},
author={Rajpurkar, Pranav and Jia, Robin and Liang, Percy},
booktitle={Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics},
pages={784--789},
year={2018}
}
@inproceedings{trischler2017newsqa,
title={NewsQA: A Machine Comprehension Dataset},
author={Trischler, Adam and Wang, Tong and Yuan, Xingdi and Harris, Justin and Sordoni, Alessandro and Bachman, Philip and Suleman, Kaheer},
booktitle={Proceedings of the 2nd Workshop on Representation Learning for NLP},
year={2017}
}
@inproceedings{zhu2021tat,
title={TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance},
author={Zhu, Fengbin and Lei, Wenqiang and Huang, Youcheng and Wang, Chao and Zhang, Shuo and Lv, Jiancheng and Feng, Fuli and Chua, Tat-Seng},
booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics},
year={2021}
}
@inproceedings{kim2023soda,
title={SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization},
author={Kim, Hyunwoo and Hessel, Jack and Jiang, Liwei and West, Peter and Lu, Ximing and Yu, Youngjae and Zhou, Pei and Bras, Ronan and Alikhani, Malihe and Kim, Gunhee and others},
booktitle={Proceedings of the 2023 Conference on EMNLP},
year={2023}
}
@inproceedings{fan2019eli5,
title={ELI5: Long Form Question Answering},
author={Fan, Angela and Jernite, Yacine and Perez, Ethan and Grangier, David and Weston, Jason and Auli, Michael},
booktitle={Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics},
year={2019}
}
@article{chung2024scaling,
title={Scaling instruction-finetuned language models},
author={Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Yunxuan and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and others},
journal={Journal of Machine Learning Research},
year={2024}
}
@inproceedings{longpre2023flan,
title={The flan collection: Designing data and methods for effective instruction tuning},
author={Longpre, Shayne and Hou, Le and Vu, Tu and Webson, Albert and Chung, Hyung Won and Tay, Yi and Zhou, Denny and Le, Quoc V and Zoph, Barret and Wei, Jason and others},
booktitle={International Conference on Machine Learning},
year={2023},
}
@inproceedings{wang2023self,
title={Self-Instruct: Aligning Language Models with Self-Generated Instructions},
author={Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A and Khashabi, Daniel and Hajishirzi, Hannaneh},
booktitle={Proceedings of the 61st Annual Meeting Of The Association For Computational Linguistics},
year={2023}
}
@inproceedings{honovich2023unnatural,
title={Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor},
author={Honovich, Or and Scialom, Thomas and Levy, Omer and Schick, Timo},
booktitle={Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics},
year={2023}
}
@article{kopf2024openassistant,
title={Openassistant conversations-democratizing large language model alignment},
author={Kopf, Andreas and Kilcher, Yannic and von Rütte, Dimitri and Anagnostidis, Sotiris and Tam, Zhi Rui and Stevens, Keith and Barhoum, Abdullah and Nguyen, Duc and Stanley, Oliver and Nagyfi, Richard and others},
journal={Advances in Neural Information Processing Systems},
year={2024}
}
@online{DatabricksBlog2023DollyV2,
author = {Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin},
title = {Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM},
year = {2023},
url = {https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm},
urldate = {2023-06-30}
}
</pre>
提供机构:
maas
创建时间:
2025-01-20
搜集汇总
数据集介绍
背景与挑战
背景概述
ChatQA-Training-Data是一个多源混合的对话问答训练数据集,包含多个公开数据集和合成的对话数据,采用两阶段训练方法,适用于训练高质量的对话问答模型。
以上内容由遇见数据集搜集并总结生成


