iris-clase
收藏Hugging Face2025-04-09 更新2025-04-10 收录
下载链接:
https://huggingface.co/datasets/Jesus02/iris-clase
下载链接
链接失效反馈官方服务:
资源简介:
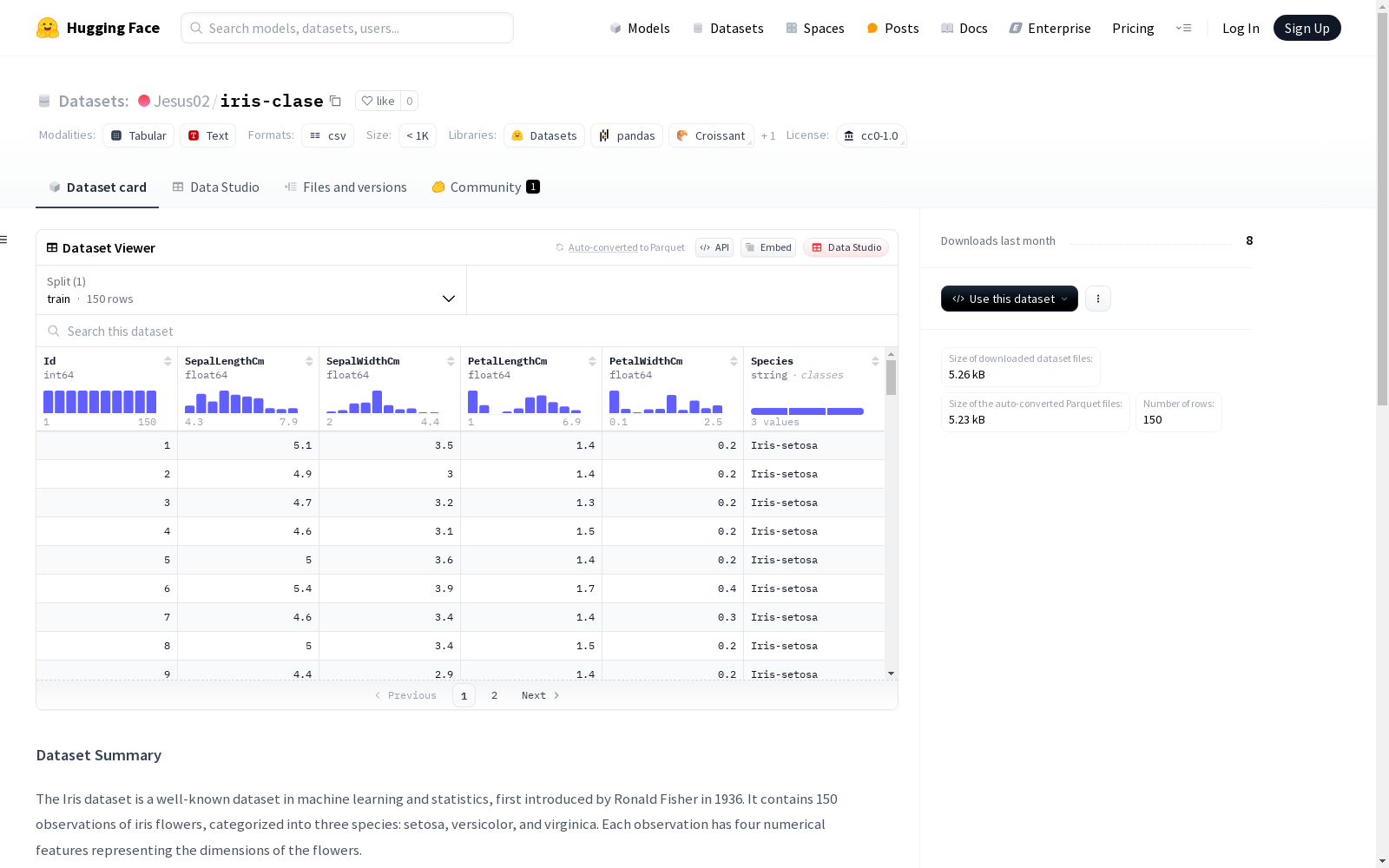
鸢尾花数据集是机器学习和统计学中著名的.datasets,最早由Ronald Fisher于1936年提出。该数据集包含150个鸢尾花样本,分为三个品种:Setosa、Versicolor和Virginica。每个样本都有四个表示花朵尺寸的数值特征。
创建时间:
2025-04-05
搜集汇总
数据集介绍
构建方式
作为模式识别领域的经典基准数据集,Iris数据集由统计学家Ronald Fisher于1936年通过系统性测量构建而成。研究者采用标准化方法采集了150个鸢尾花样本的形态学数据,每个样本精确记录了四个关键形态特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度,并由植物学家对样本所属的三个物种进行专业鉴定。这种严谨的实证研究方法确保了数据在计量生物学领域的科学价值。
特点
该数据集以其简洁而富有代表性的特征结构著称,四个连续型数值特征构成了清晰的分类边界,特别适合演示线性判别分析等经典算法。样本均匀分布在setosa、versicolor和virginica三个物种类别中,不存在类别不平衡问题。其小规模特性使得算法验证过程高效便捷,而特征间的线性可分性又为教学演示提供了直观的视觉化可能。
使用方法
在实践应用中,该数据集通常作为机器学习入门的首个实战案例,通过Scikit-learn等工具库可快速加载并进行预处理。研究者可采用交叉验证方法评估分类模型性能,或通过散点矩阵等可视化手段探索特征相关性。由于其清洁的数据质量和明确的分类目标,常被用于演示从决策树到支持向量机等各种监督学习算法的基本原理。
背景与挑战
背景概述
鸢尾花数据集(Iris dataset)是机器学习与统计学领域最具标志性的基准数据集之一,由著名统计学家Ronald Fisher于1936年在《优生学年鉴》中首次提出。该数据集系统地记录了三种鸢尾花(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的萼片与花瓣形态测量数据,每个样本包含四个精确的形态特征维度。作为模式识别领域的开创性研究案例,Fisher通过多元统计方法首次验证了植物分类的定量化可行性,为后续判别分析理论的发展奠定了实证基础。八十余年来,该数据集因其简洁性、完备性和典型性,持续服务于分类算法评估、统计教学和可解释机器学习研究,成为检验模型性能的黄金标准之一。
当前挑战
尽管鸢尾花数据集在算法验证方面具有重要价值,其固有局限性也逐渐显现。从领域问题视角,仅包含150个样本的小规模特性难以满足现代深度学习模型的训练需求,三类物种的线性可分特征也降低了复杂分类器的评估区分度。在数据构建层面,1930年代的采集条件导致样本多样性受限,缺乏环境变异因素(如地理分布、季节差异)的考量,且四个形态特征之间存在高度相关性。随着高维数据分析需求的增长,该数据集在特征稀疏性和非线性关系表征方面的不足日益突出,促使研究者通过生成对抗网络等技术对其进行扩展增强。
常用场景
经典使用场景
在机器学习领域,iris-clase数据集作为经典分类任务基准,常被用于验证监督学习算法的性能。其简洁的四维特征结构和清晰的类别划分,使其成为初学者理解特征工程和模型评估的首选案例。各类教材和在线课程频繁引用该数据集,演示从决策树到支持向量机等算法的分类边界可视化。
解决学术问题
该数据集有效解决了模式识别中多维特征分类的基准测试问题,为比较不同分类器的准确率、召回率等指标提供了标准化平台。Fisher通过该数据集首次验证了线性判别分析的实用性,推动了统计分类理论的发展,其度量数据至今仍是研究特征相关性对分类影响的重要样本。
衍生相关工作
基于该数据集衍生的经典工作包括Scikit-learn库中的分类算法测试框架,以及R语言中的多元统计可视化包。近年来,深度学习领域通过生成对抗网络对该数据集进行扩展,创造出高维合成数据以测试小样本学习算法。UCI机器学习知识库将其作为标准参考数据集,启发了后续数十个类似结构的数据集构建。
以上内容由遇见数据集搜集并总结生成


