traffic-accidents-reports-kd-smollm2-360M-7k
收藏Hugging Face2025-09-04 更新2025-09-05 收录
下载链接:
https://huggingface.co/datasets/zBotta/traffic-accidents-reports-kd-smollm2-360M-7k
下载链接
链接失效反馈官方服务:
资源简介:
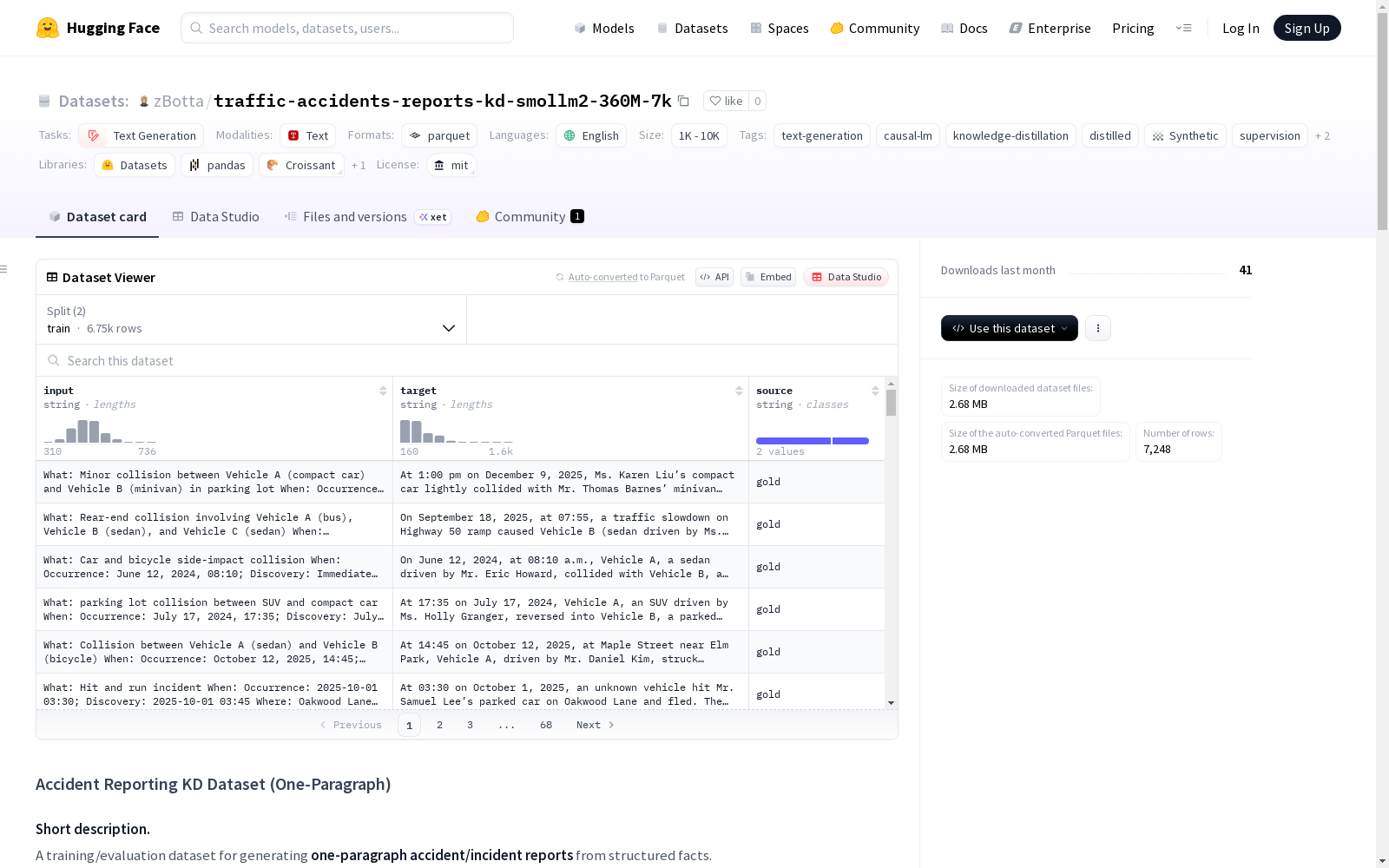
这是一个用于生成单段事故/事件报告的培训和评估数据集,由结构化事实组成。该数据集结合了来自zBotta/traffic-accidents-reports-5k数据集的黄金人类目标(gold human targets)和由模型zBotta/smollm2-accident-reporter-360m生成的教师软目标(teacher-generated soft targets),以支持对小学生的知识蒸馏(knowledge distillation,KD)。输出风格为中性语调的单段文本,涵盖What、When、Where、Who、How、Why和应急措施(ContingencyActions)。
创建时间:
2025-09-01
原始信息汇总
数据集概述
基本信息
- 数据集名称: Accident Reporting KD Dataset (One-Paragraph)
- 用途: 用于从结构化事实生成单段事故/事件报告的训练/评估数据集
- 语言: 英语
- 许可证: MIT
- 规模: 1K<n<10K
数据内容
- 训练集: 6748个样本,包含原始黄金示例和教师生成的软目标
- 评估集: 500个样本,仅包含黄金参考
数据模式
- 输入字段:
input,结构化事实的扁平字符串,格式为What: …, When: …, Where: …, Who: …, How: …, Why: …, ContingencyActions: … - 目标字段:
target,从事实生成的单段叙述(训练中为黄金或教师生成,评估中为黄金) - 来源字段:
source,标识训练行的来源("gold"或"teacher")
输出风格
- 单段落
- 中性语气
- 涵盖内容:What、When、Where、Who、How、Why、ContingencyActions
来源与生成过程
- 基础数据集: zBotta/traffic-accidents-reports-5k
- 教师模型: zBotta/smollm2-accident-reporter-360m
- KD增强: 随机选择50%的训练输入,使用确定性提示教师模型生成目标,并进行后处理确保单段落输出
- 评估集: 未改动,保持仅黄金参考以进行无偏评估
引用
@misc{accident_kd_dataset, title = {Accident Reporting KD Dataset (One-Paragraph)}, author = {zBotta}, year = {2025}, note = {Synthetic KD augmentations generated by zBotta/smollm2-accident-reporter-360m} }
搜集汇总
数据集介绍
构建方式
在交通安全与自然语言处理交叉领域,该数据集采用知识蒸馏技术构建。以zBotta/traffic-accidents-reports-5k作为基础数据源,通过教师模型zBotta/smollm2-accident-reporter-360m对50%的训练样本进行确定性推理生成合成文本,再与原始人工标注的黄金数据融合。合成文本经过严格后处理,包括响应标记提取、段落截断和格式规范化,确保生成单段落事故报告。评估集则保持纯黄金数据以保障评估无偏性。
使用方法
使用该数据集时,可通过HuggingFace datasets库直接加载,支持训练与评估分划的灵活调用。典型应用场景包括训练学生模型进行知识蒸馏,通过对比教师生成文本与黄金标准优化模型性能。输入数据为结构化事实字符串,输出预期为连贯的单段落事故报告。评估时建议使用保留的黄金标准评估集进行性能验证,确保模型生成文本在事实准确性、语言流畅度和结构完整性方面达到实用标准。
背景与挑战
背景概述
交通事故报告生成作为自然语言处理领域的重要应用方向,旨在将结构化事件数据转化为连贯的文本叙述。该数据集由研究者zBotta于2025年创建,基于原始数据集zBotta/traffic-accidents-reports-5k构建,通过知识蒸馏技术融合人工标注样本与教师模型生成样本。其核心研究在于探索小参数语言模型在专业领域文本生成中的性能优化,为事故报告自动化生成提供高质量训练资源,对提升交通安全管理效率具有显著意义。
当前挑战
本数据集主要解决交通事故报告生成任务中结构化信息到自然语言转换的挑战,包括事件要素的完整性覆盖、时空逻辑的连贯性表达以及应急措施的规范性描述。在构建过程中面临双重挑战:一方面需确保教师模型生成文本与人工标注在风格和质量上的一致性,另一方面要通过严格的后处理流程消除生成文本中的重复片段和格式错误,同时维持单段落输出的文体规范。这些挑战对知识蒸馏过程中的数据质量控制提出了较高要求。
常用场景
经典使用场景
在交通安全管理领域,该数据集被广泛应用于训练文本生成模型,将结构化的交通事故要素自动转化为连贯的单段落报告。模型通过学习输入字段中的时间、地点、人员等关键信息,生成符合规范的事故描述文本,显著提升了报告撰写的效率与标准化程度。
解决学术问题
该数据集有效解决了自然语言生成中结构化数据到流畅文本的转换难题,为知识蒸馏技术提供了高质量的软标签数据。通过融合人工标注与教师模型生成的数据,它克服了传统监督学习对大量标注数据的依赖,推动了小参数模型在专业领域文本生成任务中的性能突破。
实际应用
实际应用中,该数据集支撑的模型可部署于交通管理部门的事故处理系统,实现现场勘查数据的实时报告生成。保险行业亦可借助此类技术快速生成事故定损报告,提升理赔流程自动化水平,同时确保文本内容的规范性与法律合规性。
数据集最近研究
最新研究方向
在交通安全与自然语言处理交叉领域,该数据集正推动知识蒸馏技术在事故报告生成任务中的前沿探索。通过融合人工标注的真实报告与教师模型生成的合成数据,研究者能够训练出更轻量且高效的学生模型,满足实时事故处理系统对低延迟高精度的需求。当前研究热点集中于提升生成文本的事实一致性、时序逻辑严谨性以及应急措施的合理性,这些进展对智能交通管理、保险自动化理赔及公共安全数字化转型具有显著意义。
以上内容由遇见数据集搜集并总结生成


