NegBench
收藏arXiv2025-01-16 更新2025-01-18 收录
下载链接:
https://NegBench.github.io
下载链接
链接失效反馈官方服务:
资源简介:
NegBench是由麻省理工学院、谷歌DeepMind和牛津大学联合创建的一个多模态基准数据集,旨在评估视觉-语言模型(VLMs)对否定的理解能力。该数据集包含79,000个样本,涵盖图像、视频和医学数据,通过两个核心任务——带有否定的检索和带有否定描述的多项选择题——来全面测试模型在复杂否定场景下的表现。数据集通过从现有数据集中提取正面元素,并利用大语言模型生成否定描述,构建了多样化的否定场景。NegBench的应用领域广泛,包括搜索引擎、内容审核、推荐系统以及医学诊断等,旨在解决现有VLMs在否定理解上的不足,推动相关领域的研究进展。
NegBench is a multimodal benchmark dataset jointly developed by the Massachusetts Institute of Technology (MIT), Google DeepMind, and the University of Oxford, which aims to evaluate the negation understanding capabilities of Vision-Language Models (VLMs). This dataset contains 79,000 samples covering images, videos, and medical data, and comprehensively evaluates model performance in complex negation scenarios through two core tasks: retrieval with negation and multiple-choice questions with negated descriptions. The dataset constructs diverse negation scenarios by extracting positive elements from existing datasets and generating negated descriptions using Large Language Models (LLMs). NegBench has a wide range of application scenarios including search engines, content moderation, recommendation systems, medical diagnosis and more, and it is designed to address the limitations of existing VLMs in negation understanding and advance research progress in related fields.
提供机构:
麻省理工学院, 谷歌DeepMind, 牛津大学
创建时间:
2025-01-16
原始信息汇总
数据集概述
数据集名称
Vision-Language Models Do Not Understand Negation
发布日期
2025年
作者
- Kumail Alhamoud (MIT)
- Shaden Alshammari (MIT)
- Yonglong Tian (DeepMind)
- Guohao Li (University of Oxford)
- Philip Torr (University of Oxford)
- Yoon Kim (MIT)
- Marzyeh Ghassemi (MIT)
数据集简介
该数据集旨在评估视觉-语言模型(VLMs)对否定的理解能力。尽管通过大规模训练,VLMs在许多任务上取得了显著进展,但它们对否定的理解仍然不足。为此,研究团队引入了NegBench,一个包含18个任务变体和79k个示例的基准测试,涵盖图像、视频和医学数据集。NegBench包含两个核心任务:带有否定的检索和带有否定描述的多选题。
数据集内容
- 任务类型:18个任务变体
- 示例数量:79k个示例
- 数据类型:图像、视频、医学数据
- 核心任务:
- 带有否定的检索
- 带有否定描述的多选题
数据集评估结果
- 现代VLMs在处理否定时表现不佳,通常处于随机水平。
- 通过对CLIP模型进行大规模合成数据集的微调,研究团队发现:
- 在否定查询上的召回率提高了10%。
- 在带有否定描述的多选题上的准确率提高了40%。
相关资源
引用
bibtex
@article{
title = "Vision-Language Models Do Not Understand Negation",
author = "Kumail Alhamoud and Shaden Alshammari and Yonglong Tian and Guohao Li and Philip Torr and Yoon Kim and Marzyeh Ghassemi",
journal = "Preprint",
year = 2024,
url = "https://arxiv.org/abs/2501.09425"
}
搜集汇总
数据集介绍
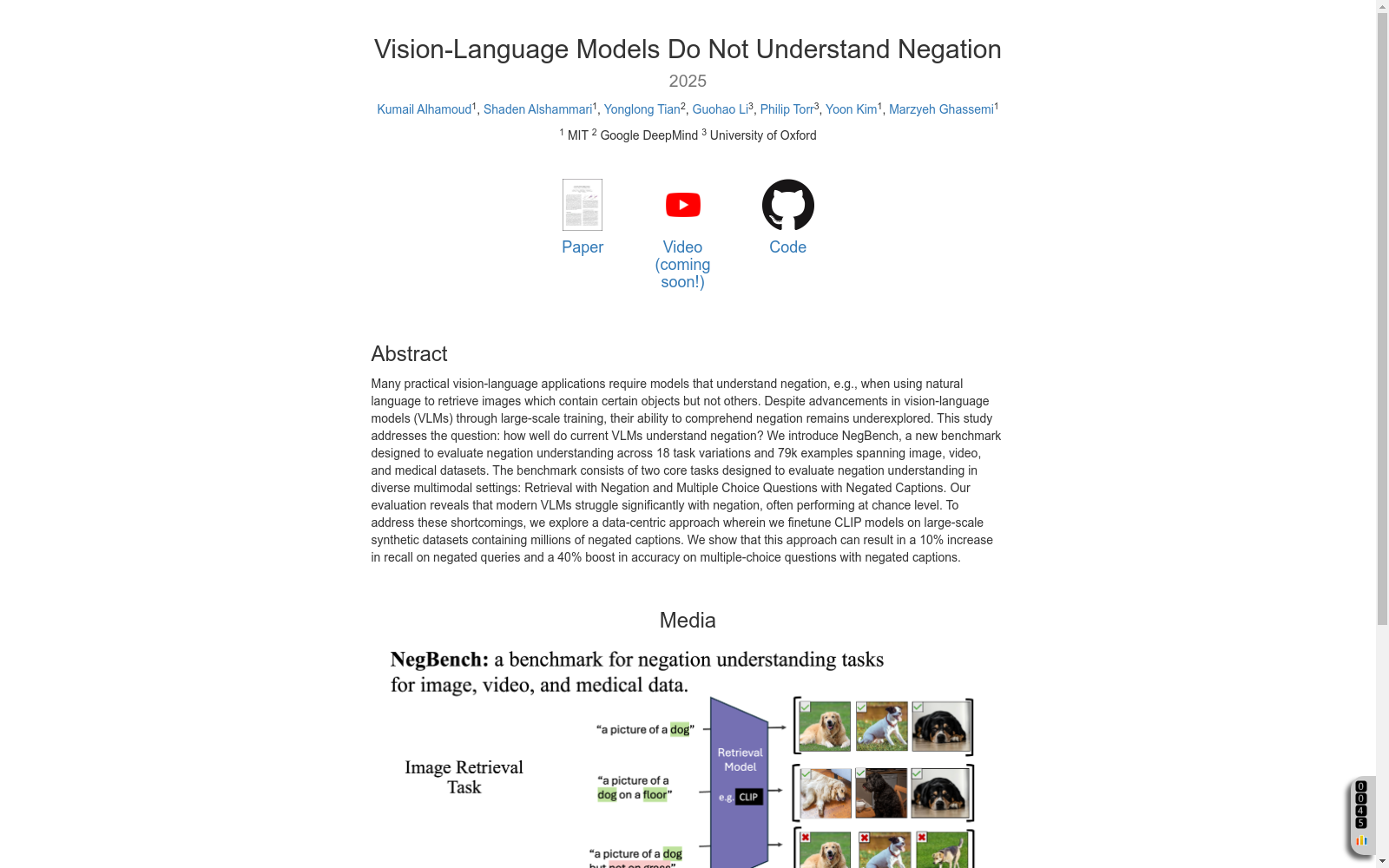
构建方式
NegBench数据集的构建基于多模态视觉-语言模型(VLMs)在理解否定语句方面的不足。研究者首先从现有的视觉数据集中提取正面元素(如COCO、VOC2007、MSR-VTT和CheXpert),并通过大型语言模型(LLM)生成与这些元素相关的否定概念。随后,使用对象检测器验证这些否定概念的准确性,确保生成的否定描述与图像内容一致。通过模板生成否定描述,并利用LLM进行自然语言改写,以增加语言多样性。最终,数据集包含79k个样本,涵盖图像、视频和医疗数据,支持18种任务变体。
特点
NegBench数据集的特点在于其广泛的任务覆盖和多样化的否定表达形式。数据集不仅包含传统的图像检索任务,还设计了多选问答任务(MCQ),要求模型在多个相似的描述中选择正确的否定或肯定描述。此外,数据集还引入了合成数据(HardNeg-Syn),通过生成硬负样本(hard negatives)来精确控制对象的出现与缺失,从而更严格地测试模型对否定的理解能力。这种设计使得NegBench能够全面评估模型在不同模态和任务中的否定理解能力。
使用方法
NegBench数据集的使用方法主要包括两个核心任务:带有否定的检索任务(Retrieval-Neg)和带有否定描述的多选问答任务(MCQ-Neg)。在Retrieval-Neg任务中,模型需要根据包含否定语句的查询检索出符合要求的图像或视频。在MCQ-Neg任务中,模型需要从多个相似的描述中选择正确的否定或肯定描述。此外,研究者还可以通过合成数据集(如CC12M-NegCap和CC12M-NegMCQ)对模型进行微调,以提升其对否定语句的理解能力。数据集的开源设计也为进一步的研究提供了便利。
背景与挑战
背景概述
NegBench是由MIT、Google DeepMind和牛津大学的研究团队于2025年提出的一个多模态基准测试数据集,旨在评估视觉-语言模型(VLMs)在理解否定语句方面的能力。该数据集涵盖了图像、视频和医学数据,包含79,000个样本,设计了18种任务变体,主要任务包括带有否定的检索任务(Retrieval with Negation)和带有否定描述的多选题任务(Multiple Choice Questions with Negated Captions)。NegBench的提出填补了现有基准测试在否定理解评估上的不足,特别是在实际应用中,如医学诊断、内容审核和推荐系统中,否定理解至关重要。通过该数据集,研究团队揭示了当前VLMs在处理否定语句时的显著缺陷,并为改进模型提供了数据驱动的解决方案。
当前挑战
NegBench面临的主要挑战包括两个方面:首先,视觉-语言模型在处理否定语句时表现不佳,尤其是在检索任务和多选题任务中,模型往往无法区分肯定和否定的描述,导致性能显著下降。其次,数据集的构建过程中也面临挑战,特别是在生成自然语言否定描述时,如何确保生成的否定语句既符合语言习惯,又能准确反映图像或视频中的内容。此外,数据集的多样性和复杂性要求模型能够处理不同领域(如医学图像和视频)中的否定理解问题,这对模型的泛化能力提出了更高的要求。通过引入大规模合成数据,研究团队试图解决这些问题,但如何进一步提升模型在复杂场景中的否定理解能力仍是一个开放性问题。
常用场景
经典使用场景
NegBench数据集主要用于评估视觉-语言模型(VLMs)在处理否定语句时的能力。通过设计包含否定语句的图像检索和多选问答任务,NegBench能够系统地测试模型在复杂多模态场景下的表现。例如,在图像检索任务中,模型需要根据包含否定条件的查询(如“没有人的海滩”)从大量图像中筛选出符合条件的图像。这种任务模拟了现实世界中的搜索引擎、内容审核和推荐系统等场景,要求模型能够准确理解否定语句的含义。
解决学术问题
NegBench解决了视觉-语言模型在处理否定语句时的性能瓶颈问题。尽管现有的VLMs在大规模训练后取得了显著进展,但它们在理解否定语句方面的能力仍然不足。NegBench通过引入包含否定语句的合成数据集,揭示了模型在处理否定时的局限性,并提出了一种基于数据的方法来提升模型的性能。这一工作不仅填补了现有基准测试的空白,还为未来研究提供了新的方向,推动了视觉-语言模型在复杂语言理解任务中的进一步发展。
衍生相关工作
NegBench的推出催生了一系列相关研究工作,尤其是在提升视觉-语言模型对否定语句理解能力方面。例如,基于NegBench的合成数据集,研究者提出了NegCLIP和ConCLIP等改进模型,这些模型通过引入合成数据和调整训练目标,显著提升了模型在处理否定语句时的表现。此外,NegBench还为其他领域的研究提供了启发,如医疗影像分析中的否定理解任务,推动了BiomedCLIP等专门用于医疗领域的视觉-语言模型的发展。这些衍生工作进一步扩展了NegBench的应用范围,推动了多模态模型在复杂语言理解任务中的进步。
以上内容由遇见数据集搜集并总结生成


