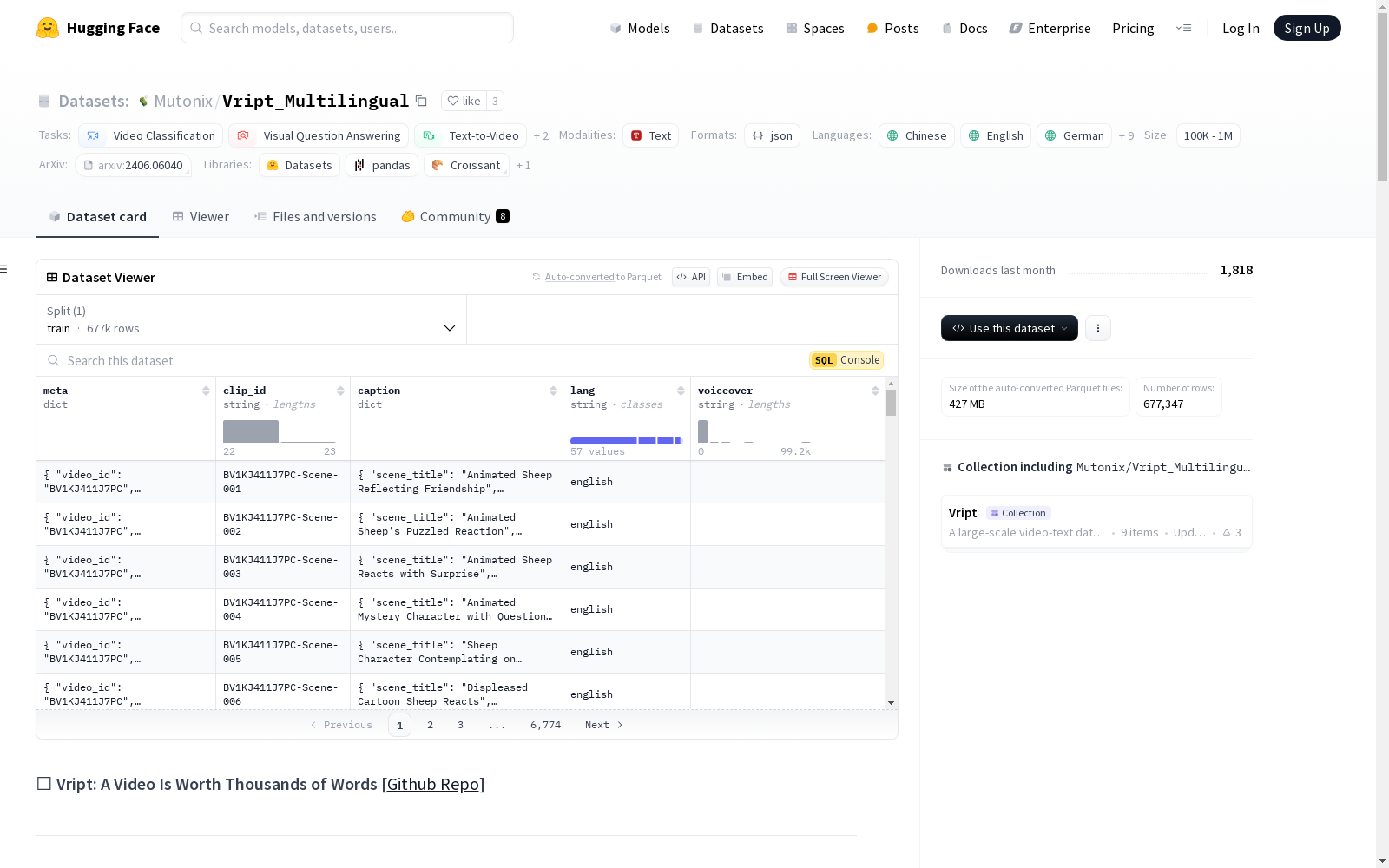
Vript_Multilingual
收藏Vript_Multilingual 数据集概述
数据集任务类别
- 视频分类
- 视觉问答
- 文本到视频
- 文本到图像
- 图像到视频
语言支持
- 中文 (zh)
- 英文 (en)
- 德语 (de)
- 日语 (ja)
- 韩语 (ko)
- 俄语 (ru)
- 西班牙语 (es)
- 葡萄牙语 (pt)
- 爪哇语 (jv)
- 法语 (fr)
- 印度尼西亚语 (id)
- 越南语 (vi)
数据集规模
- 100K < n < 1M
配置
- 配置名称: bili
- 数据文件:
- 分割: train
- 路径: vript_CN-V2_captions/vript_CN-V2_captions.jsonl
- 分割: train
- 数据文件:
数据集特点
- 多语言支持:
- 中文 (59%)
- 英文 (24%)
- 德语 (13%)
- 日语 (2%)
- 韩语 (1%)
- 俄语 (<1%)
- 西班牙语 (<1%)
- 葡萄牙语 (<1%)
- 爪哇语 (<1%)
- 法语 (<1%)
- 印度尼西亚语 (<1%)
- 越南语 (<1%)
- 更多样化和细粒度的类别: 113个类别
- 更广泛的时间范围: 从2011年1月到2024年6月
- 更高分辨率: 1080p
- 更长的平均时长: 超过10分钟
- 更多片段: 约677k个片段
数据结构
video_id: 视频的IDvideo_title: 视频的标题num_clips: 视频中的片段数量integrity: 视频的所有片段是否都被标注clip_id: 视频中片段的IDcaption: 场景的标注,包括镜头类型、摄像机移动、内容和场景标题voiceover: 场景中的配音转录
数据文件组织
Vript_Multilingual/ | ├── vript_CN-V2_meta.json │ ├── vript_CN-V2_captions/ │ ├── vript_CN-V2_captions.zip │ └── vript_CN-V2_captions.jsonl │ ├── vript_CN-V2_videos/ │ ├── CN-V2_video_1_of_224.zip │ │ ├── xxx.mp4 │ │ └── ... │ ├── CN-V2_video_2_of_224.zip │ └── ... │ └── vript_CN-V2_clips/ ├── CN-V2_clips_1_of_224.zip │ ├── xxx/ │ │ ├── xxx_cut_meta.json │ │ ├── xxx_asr.jsonl │ │ ├── xxx-Scene-001.mp4 │ │ └── ... │ └── ... ├── CN-V2_clips_2_of_224.zip └── ...
许可证
- 仅限学术使用
- 禁止分发
- 限制和责任限制
- 免责声明
引用
@misc{yang2024vript, title={Vript: A Video Is Worth Thousands of Words}, author={Dongjie Yang and Suyuan Huang and Chengqiang Lu and Xiaodong Han and Haoxin Zhang and Yan Gao and Yao Hu and Hai Zhao}, year={2024}, eprint={2406.06040}, archivePrefix={arXiv}, primaryClass={cs.CV} }
联系
- Dongjie Yang: djyang.tony@sjtu.edu.cn
- 论文: arxiv.org/abs/2406.06040