ALLVB
收藏arXiv2025-03-10 更新2025-03-12 收录
下载链接:
https://huggingface.co/datasets/ALLVB/ALLVB
下载链接
链接失效反馈官方服务:
资源简介:
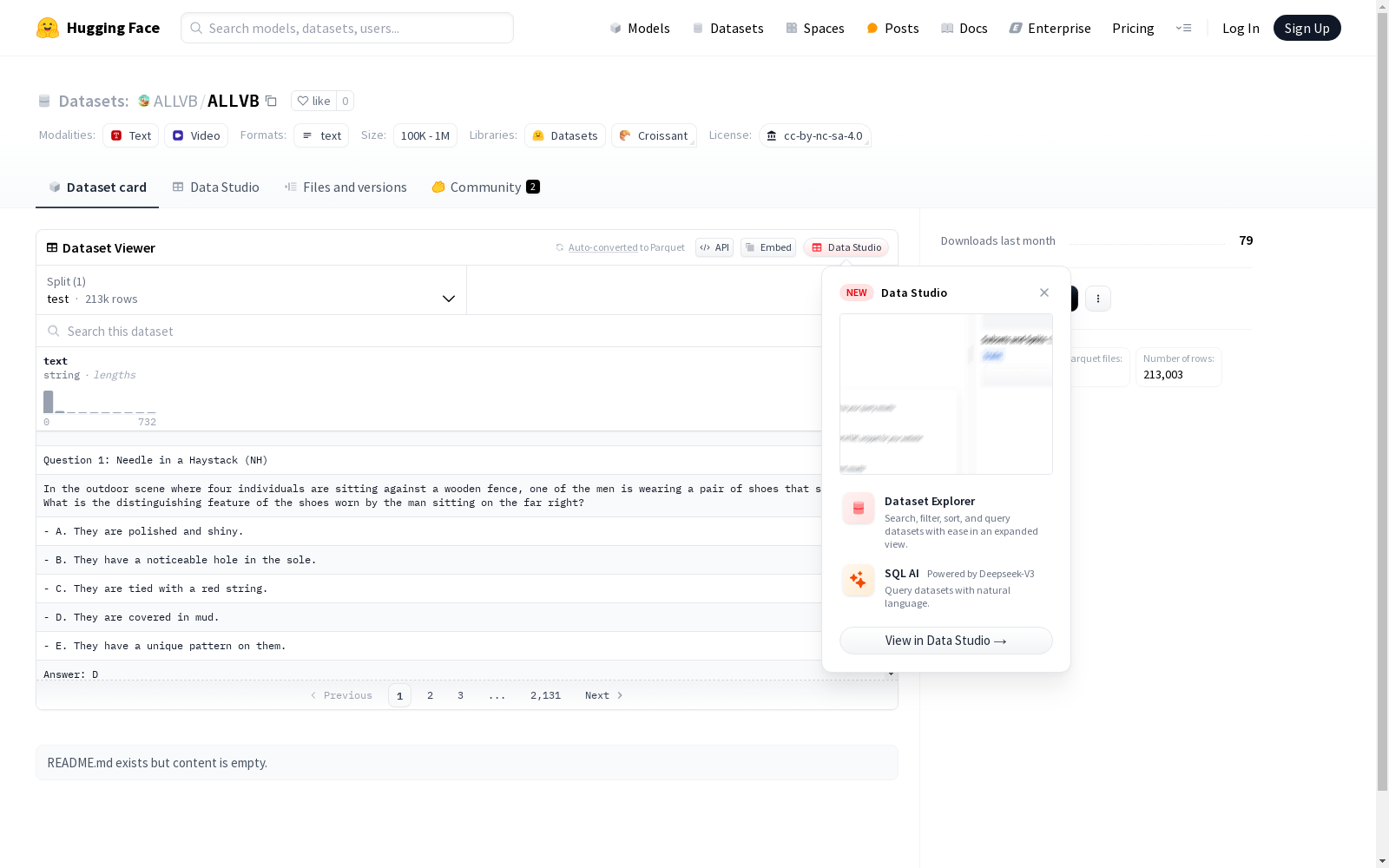
ALLVB是一个全面的一体化长视频理解基准,由国防科技大学计算机科学与技术学院和湖南大学设计学院创建。该数据集包含1376部平均时长接近2小时的视频,涵盖16个类别,共有252k个问答对,是迄今为止最大的长视频理解基准。数据集整合了9项主要视频理解任务,转换为视频问答格式,全面评估多模态大型语言模型在理解长视频方面的能力。
ALLVB is a comprehensive all-in-one benchmark for long video understanding, developed by the School of Computer Science and Technology, National University of Defense Technology and the School of Design, Hunan University. This dataset consists of 1,376 videos with an average duration of nearly two hours, covering 16 categories, and contains a total of 252k question-answer pairs, making it the largest long video understanding benchmark to date. The dataset integrates nine core video understanding tasks into the video question answering format to comprehensively evaluate the capabilities of multimodal large language models in long video comprehension.
提供机构:
国防科技大学计算机科学与技术学院, 湖南大学设计学院
创建时间:
2025-03-10
搜集汇总
数据集介绍
构建方式
ALLVB数据集的构建方式包括数据收集与清洗、情节分割、问题模板设计以及QA构建等步骤。首先,从开源网站收集大量电影剧本,并通过GPT-4o生成视频相关的QA。其次,为了确保LLM能够捕捉电影中的细节,采用两阶段分割方法将剧本分割成不同的情节和子情节,并为整个剧本和子情节构建QA。最后,设计了91个问题模板,涵盖了9种视频理解任务,并使用这些模板生成最终的QA。
使用方法
使用ALLVB数据集时,首先需要将其分割成训练集和测试集。然后,在测试集上测试各种MLLMs,并计算每个模型在9种视频理解任务上的准确率。为了确保公平性,所有模型都使用相同的输入帧数和提示。最后,根据模型的准确率来评估其视频理解能力。
背景与挑战
背景概述
随着大型语言模型(LLMs)从文本领域向多模态领域的发展,尤其是图像和视频输入的整合,对模型性能的客观评估变得日益重要。ALLVB(All-in-One Long Video Understanding Benchmark)数据集的提出,旨在解决现有视频理解基准测试中视频时长过短的问题,以全面评估多模态LLMs对长视频序列的建模能力。ALLVB由来自中国国防科技大学计算机科学与技术学院和湖南大学设计学院的团队于2025年创建,该数据集整合了9个主要的视频理解任务,并转换为视频问答格式,使得一个基准测试能够评估MLLMs的9种不同的视频理解能力。ALLVB包含1376个视频,涵盖16个类别,平均时长接近2小时,总共包含252k个问答。ALLVB的创建不仅填补了长视频理解领域的空白,也为评估和推动多模态LLMs的发展提供了重要的工具。
当前挑战
ALLVB数据集的创建和使用面临多项挑战。首先,现有的视频理解基准测试主要集中在短视频上,而长视频的理解和评估相对较少,这给ALLVB的创建和评估带来了新的挑战。其次,构建ALLVB的过程中,需要处理大量的视频数据,包括视频剪辑、脚本分析、问答生成等,这些工作需要高效且自动化的处理流程。此外,ALLVB的问答内容相对简单,与人类的能力相比仍有差距,如何提高问答内容的复杂性和专业性是未来需要解决的问题。最后,尽管ALLVB是目前最大的长视频理解基准测试,但仍需要不断更新和扩展,以适应不断发展的多模态LLMs和视频理解领域。
常用场景
经典使用场景
ALLVB数据集作为评估多模态大型语言模型(MLLMs)对长视频理解能力的全面基准,广泛应用于模型训练和性能评估。通过将9项主要视频理解任务转化为视频问答格式,ALLVB能够在一个基准中评估MLLMs的9种不同的视频理解能力,从而突显其通用性、全面性和挑战性。
解决学术问题
ALLVB数据集解决了现有视频理解基准相对较短的问题,无法有效评估MLLMs的长时间序列建模能力。ALLVB包含了1,376个视频,跨越16个类别,平均每个视频近2小时,总计252k个问答。这是迄今为止最大的长视频理解基准,为MLLMs在长视频理解领域的发展提供了宝贵的资源。
实际应用
ALLVB数据集在实际应用中,可用于评估和提升MLLMs在视频内容分析、视频问答、视频分类、场景识别、物体检测与跟踪、动作识别、时间动作定位、事件检测、视频描述和视频情绪识别等任务上的性能。此外,ALLVB的自动化标注流程使其易于维护和扩展,为视频理解领域的持续发展提供了有力支持。
数据集最近研究
最新研究方向
ALLVB数据集的提出,标志着长视频理解领域的一个重要进展。该数据集融合了9大视频理解任务,并采用了GPT-4o的自动化标注流程,实现了高效且科学性强的长视频理解基准测试。ALLVB数据集包含1376个视频,平均时长近2小时,总共有25.2万个问答,是目前为止最大的长视频理解数据集。通过对多种主流多模态大语言模型(MLLMs)的测试,结果表明即使是先进的商业模型也存在着较大的提升空间。这表明ALLVB数据集具有挑战性,并且长视频理解领域仍具有巨大的发展潜力。该数据集为评估MLLMs的长序列建模能力提供了一个全面的平台,有助于推动长视频理解技术的发展。
相关研究论文
- 1ALLVB: All-in-One Long Video Understanding Benchmark国防科技大学计算机科学与技术学院, 湖南大学设计学院 · 2025年
以上内容由遇见数据集搜集并总结生成


