ettin-pretraining-data
收藏魔搭社区2025-12-05 更新2025-09-13 收录
下载链接:
https://modelscope.cn/datasets/jhu-clsp/ettin-pretraining-data
下载链接
链接失效反馈官方服务:
资源简介:
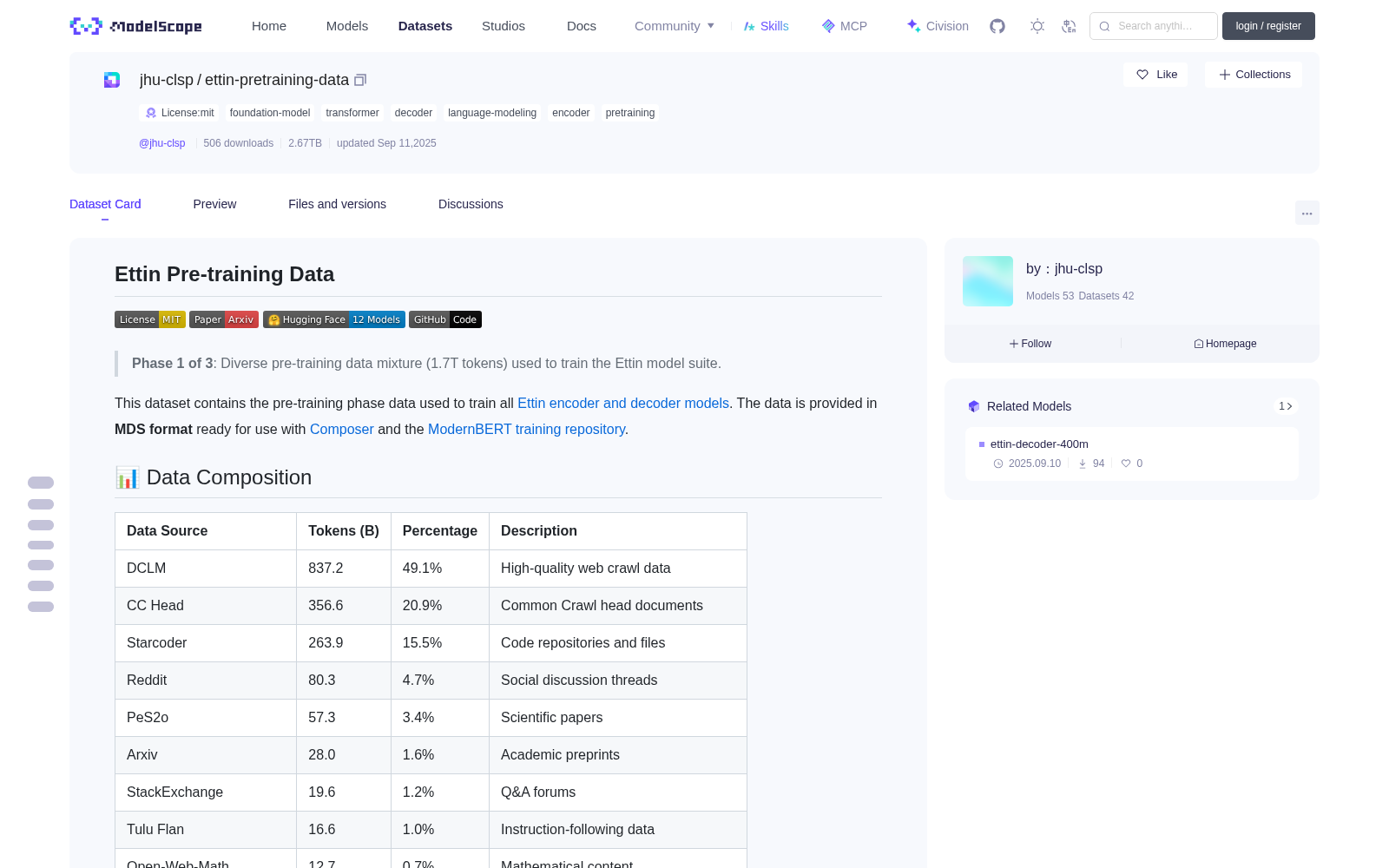
# Ettin Pre-training Data
[](https://opensource.org/licenses/MIT)
[](https://arxiv.org/abs/2507.11412)
[](https://huggingface.co/jhu-clsp)
[](https://github.com/jhu-clsp/ettin-encoder-vs-decoder)
> **Phase 1 of 3**: Diverse pre-training data mixture (1.7T tokens) used to train the Ettin model suite.
This dataset contains the pre-training phase data used to train all [Ettin encoder and decoder models](https://huggingface.co/jhu-clsp). The data is provided in **MDS format** ready for use with [Composer](https://github.com/mosaicml/composer) and the [ModernBERT training repository](https://github.com/answerdotai/ModernBERT).
## 📊 Data Composition
| Data Source | Tokens (B) | Percentage | Description |
|:------------|:-----------|:-----------|:------------|
| DCLM | 837.2 | 49.1% | High-quality web crawl data |
| CC Head | 356.6 | 20.9% | Common Crawl head documents |
| Starcoder | 263.9 | 15.5% | Code repositories and files |
| Reddit | 80.3 | 4.7% | Social discussion threads |
| PeS2o | 57.3 | 3.4% | Scientific papers |
| Arxiv | 28.0 | 1.6% | Academic preprints |
| StackExchange | 19.6 | 1.2% | Q&A forums |
| Tulu Flan | 16.6 | 1.0% | Instruction-following data |
| Open-Web-Math | 12.7 | 0.7% | Mathematical content |
| Algebraic StackExchange | 12.6 | 0.7% | Math Q&A |
| CC News | 7.3 | 0.4% | News articles |
| Wikipedia | 7.3 | 0.4% | Encyclopedia articles |
| **Total** | **1,704.7** | **100.0%** | Diverse mixture for foundation training |
## 🚀 Usage
For pre-training, see the ModernBERT repo: https://github.com/AnswerDotAI/ModernBERT
### Direct Access
```python
from streaming import StreamingDataset
# Load the streaming dataset
dataset = StreamingDataset(
remote='https://huggingface.co/datasets/jhu-clsp/ettin-pretraining-data',
local='/tmp/ettin-pretraining-data',
shuffle=True
)
# Access samples
for sample in dataset:
text = sample['text']
# Process your data...
```
## 📁 Structure
Each folder contains one data source in MDS (Mosaic Data Shard) format:
- `arxiv/` - Academic papers from ArXiv
- `books/` - Literature and reference books
- `cc_head/` - High-quality Common Crawl documents
- `cc_news/` - News articles from Common Crawl
- `dclm/` - DataComp-LM filtered web data
- `open_web_math/` - Mathematical web content
- `algebraic_stackexchange/` - Math Q&A from StackExchange
- `pes2o/` - Scientific papers (PeS2o dataset)
- `reddit/` - Reddit discussion threads
- `stackexchange/` - General StackExchange Q&A
- `starcoder/` - Code from GitHub repositories
- `tulu_flan/` - Instruction-following examples
- `wikipedia/` - Wikipedia articles
## 🔗 Related Resources
- **Models**: [Ettin Model Suite](https://huggingface.co/collections/jhu-clsp/encoders-vs-decoders-the-ettin-suite-686303e16142257eed8e6aeb) (17M-1B parameters)
- **Phase 2**: [Mid-training Data](https://huggingface.co/datasets/jhu-clsp/ettin-extension-data) (250B tokens)
- **Phase 3**: [Decay Phase Data](https://huggingface.co/datasets/jhu-clsp/ettin-decay-data) (50B tokens)
- **Training Order**: [Batch-level Data Order](https://huggingface.co/datasets/jhu-clsp/ettin-data-order)
- **Paper**: [Arxiv link](https://arxiv.org/abs/2507.11412)
- **Code**: [GitHub Repository](https://github.com/jhu-clsp/ettin-encoder-vs-decoder)
## Citation
```bibtex
@misc{weller2025seqvsseqopen,
title={Seq vs Seq: An Open Suite of Paired Encoders and Decoders},
author={Orion Weller and Kathryn Ricci and Marc Marone and Antoine Chaffin and Dawn Lawrie and Benjamin Van Durme},
year={2025},
eprint={2507.11412},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.11412},
}
```
# Ettin 预训练数据集
[](https://opensource.org/licenses/MIT)
[](https://arxiv.org/abs/2507.11412)
[](https://huggingface.co/jhu-clsp)
[](https://github.com/jhu-clsp/ettin-encoder-vs-decoder)
> **三阶段中的第一阶段**:用于训练Ettin模型套件的多样化预训练数据混合集(1.7万亿Token)。
本数据集包含用于训练所有[Ettin编码器与解码器模型](https://huggingface.co/jhu-clsp)的预训练阶段数据。该数据以**MDS(Mosaic Data Shard)格式**提供,可直接与[Composer](https://github.com/mosaicml/composer)及[ModernBERT训练仓库](https://github.com/answerdotai/ModernBERT)配合使用。
## 📊 数据构成
| 数据来源 | Token数(十亿) | 占比 | 描述 |
|:------------|:-----------|:-----------|:------------|
| DCLM | 837.2 | 49.1% | 高质量网络爬取数据 |
| CC Head | 356.6 | 20.9% | Common Crawl 头部文档 |
| Starcoder | 263.9 | 15.5% | 代码仓库与文件 |
| Reddit | 80.3 | 4.7% | 社交讨论线程 |
| PeS2o | 57.3 | 3.4% | 学术论文 |
| Arxiv | 28.0 | 1.6% | 学术预印本 |
| StackExchange | 19.6 | 1.2% | 问答论坛 |
| Tulu Flan | 16.6 | 1.0% | 指令跟随数据 |
| Open-Web-Math | 12.7 | 0.7% | 数学内容 |
| Algebraic StackExchange | 12.6 | 0.7% | 数学问答 |
| CC News | 7.3 | 0.4% | 新闻文章 |
| Wikipedia | 7.3 | 0.4% | 百科全书文章 |
| **总计** | **1,704.7** | **100.0%** | 用于基础训练的多样化混合数据 |
## 🚀 使用方法
如需进行预训练,请参考ModernBERT仓库:https://github.com/AnswerDotAI/ModernBERT
### 直接访问
python
from streaming import StreamingDataset
# 加载流式数据集
dataset = StreamingDataset(
remote='https://huggingface.co/datasets/jhu-clsp/ettin-pretraining-data',
local='/tmp/ettin-pretraining-data',
shuffle=True
)
# 访问样本
for sample in dataset:
text = sample['text']
# 处理你的数据...
## 📁 数据集结构
每个文件夹包含一个MDS(Mosaic Data Shard)格式的数据来源文件:
- `arxiv/` - ArXiv学术论文
- `books/` - 文学与参考书籍
- `cc_head/` - 高质量Common Crawl文档
- `cc_news/` - Common Crawl新闻文章
- `dclm/` - DataComp-LM过滤后的网络数据
- `open_web_math/` - 网络数学内容
- `algebraic_stackexchange/` - StackExchange数学问答
- `pes2o/` - 科学论文(PeS2o数据集)
- `reddit/` - Reddit讨论线程
- `stackexchange/` - 通用StackExchange问答
- `starcoder/` - GitHub仓库代码
- `tulu_flan/` - 指令跟随示例
- `wikipedia/` - 维基百科文章
## 🔗 相关资源
- **模型套件**:[Ettin模型套件](https://huggingface.co/collections/jhu-clsp/encoders-vs-decoders-the-ettin-suite-686303e16142257eed8e6aeb)(1700万-10亿参数)
- **第二阶段**:[中期训练数据集](https://huggingface.co/datasets/jhu-clsp/ettin-extension-data)(2500亿Token)
- **第三阶段**:[衰减阶段数据集](https://huggingface.co/datasets/jhu-clsp/ettin-decay-data)(500亿Token)
- **训练顺序**:[批次级数据顺序](https://huggingface.co/datasets/jhu-clsp/ettin-data-order)
- **论文**:[ArXiv论文链接](https://arxiv.org/abs/2507.11412)
- **代码仓库**:[GitHub代码仓库](https://github.com/jhu-clsp/ettin-encoder-vs-decoder)
## 引用格式
bibtex
@misc{weller2025seqvsseqopen,
title={Seq vs Seq: An Open Suite of Paired Encoders and Decoders},
author={Orion Weller and Kathryn Ricci and Marc Marone and Antoine Chaffin and Dawn Lawrie and Benjamin Van Durme},
year={2025},
eprint={2507.11412},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.11412},
}
提供机构:
maas创建时间:
2025-09-10
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于训练Ettin模型套件的预训练数据,包含1.7T tokens的多样化混合内容,覆盖网页爬取、代码、学术论文等13个来源。数据以MDS格式提供,可直接与Composer和ModernBERT训练仓库配合使用。
以上内容由遇见数据集搜集并总结生成


