gretel-financial-risk-analysis-v1
收藏Hugging Face2024-11-09 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/gretelai/gretel-financial-risk-analysis-v1
下载链接
链接失效反馈官方服务:
资源简介:
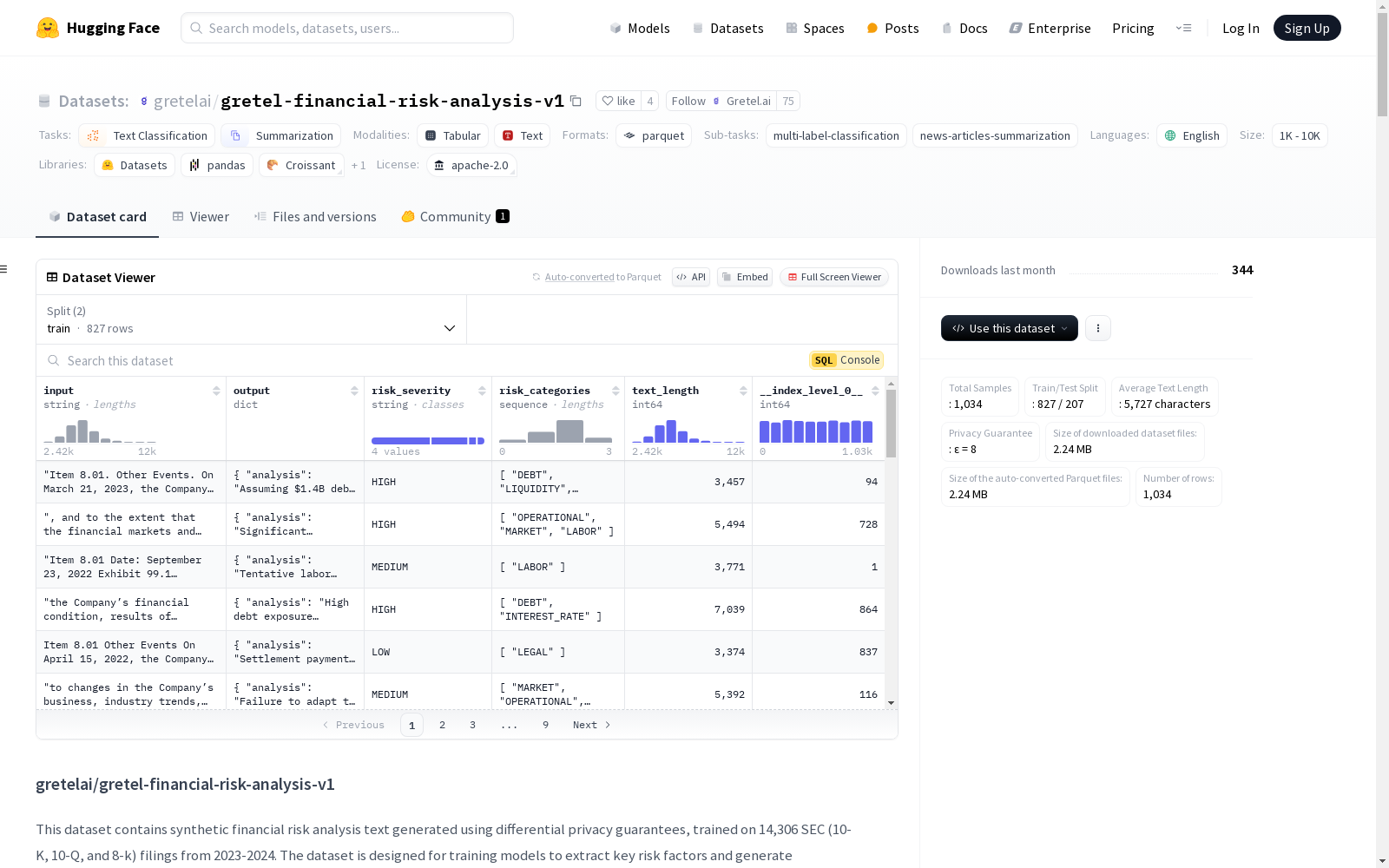
该数据集包含使用差分隐私保证生成的合成金融风险分析文本,训练数据来自2023-2024年的14,306份SEC(10-K、10-Q和8-K)文件。数据集旨在训练模型从金融文档中提取关键风险因素并生成结构化摘要,展示了利用差分隐私保护敏感信息的能力。数据集支持两个主要任务:特征提取(识别和分类文本中的金融风险)和文本摘要(生成结构化风险分析摘要)。模型输出包括风险严重性分类、风险类别识别和识别风险的结构化分析。数据集包含1,034个样本,训练/测试分割为827/207,平均文本长度为5,727个字符,隐私保证为ε = 8。
This dataset comprises synthetic financial risk analysis texts generated under differential privacy guarantees, with training data sourced from 14,306 SEC filings (10-K, 10-Q, and 8-K) spanning 2023 to 2024. It is designed to train models to extract critical risk factors from financial documents and generate structured summaries, demonstrating the capability of leveraging differential privacy to protect sensitive information. The dataset supports two core tasks: feature extraction (identifying and classifying financial risks within texts) and text summarization (generating structured risk analysis summaries). Model outputs include risk severity classification, risk category identification, and structured analysis of identified risks. The dataset contains 1,034 samples, with an 827/207 train/test split, an average text length of 5,727 characters, and a privacy guarantee of ε = 8.
提供机构:
Gretel.ai创建时间:
2024-11-09
搜集汇总
数据集介绍
构建方式
该数据集基于2023至2024年间的14,306份SEC文件(包括10-K、10-Q和8-K),通过差分隐私技术生成合成金融风险分析文本。数据生成过程中,采用了Gretel的合成数据平台,并确保隐私保护参数ε=8。数据集的设计旨在训练模型从金融文档中提取关键风险因素并生成结构化摘要,同时通过差分隐私技术保护敏感信息。
特点
该数据集包含1,034个样本,平均文本长度为5,727个字符,分为827个训练样本和207个测试样本。数据集支持多标签分类和新闻文章摘要生成任务,模型输出包括风险严重程度分类(无/低/中/高)、风险类别识别以及结构化风险分析。数据分布展示了风险严重程度、风险类别和文本长度的详细统计信息,确保了数据的多样性和代表性。
使用方法
该数据集适用于金融风险分析和文本摘要生成任务。用户可以通过训练模型来识别和分类金融风险,并生成结构化摘要。数据集遵循严格的输入输出格式,使用Pydantic库定义的模式约束了风险严重程度、风险类别、财务影响等字段的格式和范围。用户可以根据提供的示例数据点进行模型训练和测试,确保模型输出的准确性和一致性。
背景与挑战
背景概述
gretel-financial-risk-analysis-v1数据集由Gretel AI于2024年发布,旨在通过合成数据技术解决金融风险分析中的关键问题。该数据集基于2023年至2024年间的14,306份SEC文件(包括10-K、10-Q和8-K),采用差分隐私技术生成,确保敏感信息的保护。其主要研究问题聚焦于从金融文档中提取关键风险因素并生成结构化摘要,为金融领域的风险管理和决策支持提供了重要工具。该数据集的发布不仅推动了金融文本分析技术的发展,还为隐私保护技术在金融数据中的应用提供了范例。
当前挑战
gretel-financial-risk-analysis-v1数据集在构建和应用过程中面临多重挑战。首先,金融文本的复杂性和多样性使得风险因素的提取和分类变得困难,尤其是在多标签分类任务中,模型需要准确识别并区分不同类型的风险。其次,差分隐私技术的引入虽然保护了数据隐私,但也可能导致生成数据的真实性和信息量下降,影响模型的训练效果。此外,数据集的结构化输出要求严格遵循预定义的模式,这对模型的生成能力和一致性提出了更高要求。最后,金融领域的动态变化要求数据集能够及时更新,以反映最新的市场状况和风险趋势,这对数据集的维护和扩展提出了持续挑战。
常用场景
经典使用场景
在金融风险分析领域,gretel-financial-risk-analysis-v1数据集被广泛应用于训练模型以从复杂的财务文档中提取关键风险因素,并生成结构化的风险分析摘要。该数据集通过差分隐私技术生成,确保了数据的隐私性,同时保留了财务文档的核心信息。研究人员和从业者可以利用该数据集进行多标签分类和文本摘要任务,从而提升金融风险分析的自动化水平。
实际应用
在实际应用中,gretel-financial-risk-analysis-v1数据集被金融机构和风险管理公司广泛用于自动化风险分析系统的开发。通过使用该数据集训练的模型,企业能够快速从财务报告中提取关键风险信息,生成结构化摘要,从而辅助决策制定。此外,该数据集还可用于合规性检查,帮助企业识别潜在的财务风险,确保符合监管要求。
衍生相关工作
基于gretel-financial-risk-analysis-v1数据集,许多经典研究工作得以展开。例如,研究人员开发了基于深度学习的多标签分类模型,用于更精确地识别财务文档中的风险类别。此外,该数据集还推动了差分隐私技术在金融文本生成中的应用研究,为保护敏感信息提供了新的解决方案。这些衍生工作不仅丰富了金融文本分析的研究内容,也为实际应用提供了更多可能性。
以上内容由遇见数据集搜集并总结生成

暂无相关数据集


