high-school-exams-vi
收藏Hugging Face2025-06-02 更新2025-06-03 收录
下载链接:
https://huggingface.co/datasets/danganhdat/high-school-exams-vi
下载链接
链接失效反馈官方服务:
资源简介:
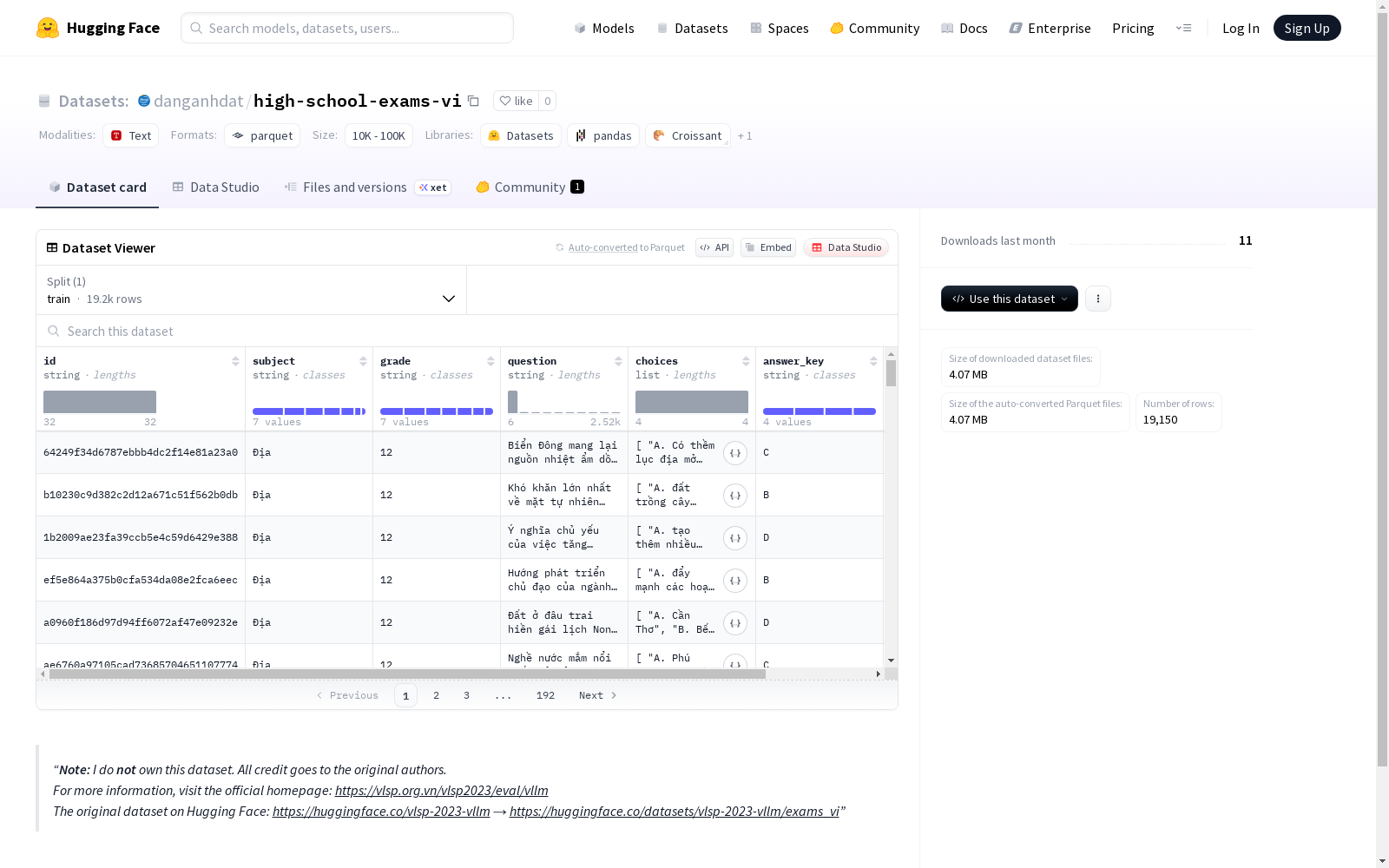
这是一个包含考试问题的数据集,具体为越南语考试问题。数据集中的字段包括问题ID、科目、年级、问题内容、选项、正确答案标识和正确答案。训练集包含了19150个示例,数据集大小为8235219字节。
This is a dataset consisting of examination questions, specifically Vietnamese-language examination questions. The dataset contains the following fields: question ID, subject, grade, question content, options, correct answer identifier, and correct answer. The training set includes 19150 instances, with a total size of 8235219 bytes.
创建时间:
2025-05-29
搜集汇总
数据集介绍
构建方式
在越南教育评估领域,high-school-exams-vi数据集通过系统收集越南高中阶段的标准化考试题目构建而成。数据来源于越南语言与语音处理协会(VLSP)2023年评估活动,涵盖了多学科的真实考试内容。构建过程中,题目被结构化处理为包含问题、选项和标准答案的格式,确保了数据的完整性和一致性。
特点
该数据集包含19150个样本,覆盖多个学科和年级,每个样本具有唯一的ID标识。题目设计为多项选择题形式,提供了清晰的选项序列和标准答案键。数据以训练集形式组织,总大小约8.24MB,适用于教育领域的自然语言处理任务。其多学科特性为研究跨领域知识推理提供了丰富素材。
使用方法
使用者可通过Hugging Face平台直接下载该数据集,数据文件以标准格式存储于train分割中。研究人员可基于问题、选项和答案键字段构建自动答题模型,或开展教育数据挖掘研究。数据集支持对越南高中教育体系的评估分析,为多语言教育技术开发提供基准资源。
背景与挑战
背景概述
high-school-exams-vi数据集由越南语言与语音处理社区(VLSP)于2023年构建,旨在推动越南语教育评估领域的人工智能研究。该数据集汇集了越南高中多学科考试题目,涵盖语文、数学等核心科目,为自然语言处理模型提供了标准化的学术能力测试基准。其设计初衷在于解决越南语教育数据稀缺的问题,通过大规模真实考试题目促进语言模型在复杂推理和知识应用方面的性能提升,对东南亚地区教育技术发展具有重要参考价值。
当前挑战
该数据集核心挑战在于应对越南语教育评估中多学科知识融合与复杂逻辑推理的难题,要求模型同时掌握语言理解与学科专业知识。构建过程中需克服考试题目版权协调、多科目答案标准化以及语言文化特异性处理等障碍,例如越南语特有的语法结构和学科术语的统一标注。此外,确保题目难度分布均衡且符合实际教育大纲要求,也是数据集质量保障的关键环节。
常用场景
经典使用场景
在越南教育技术领域,high-school-exams-vi数据集作为标准化的高中学科评估资源,广泛应用于教育智能系统的开发。该数据集通过涵盖数学、物理、化学等多学科的选择题形式,为语言模型提供了结构化的知识理解与推理测试平台。研究人员常利用其丰富的题目内容和标准答案,系统评估模型在学科知识掌握、逻辑推理以及越南语理解方面的综合能力,从而推动教育自动化技术的深入发展。
实际应用
在实际教育场景中,该数据集为智能辅导系统、自适应学习平台以及自动化评卷工具的开发提供了核心支持。教育机构可基于其题目库构建个性化练习系统,实时检测学生的学习盲点;技术企业则能利用其评估框架优化越南语教育产品的知识推理模块。这种应用不仅提升了教学效率,更通过标准化评估推动了教育公平,使优质教育资源得以更广泛地惠及越南各地学生。
衍生相关工作
围绕该数据集衍生的经典研究主要集中在多模态知识推理与低资源语言教育技术领域。VLSP-2023评测竞赛中以该数据为基础的越南语言模型评估任务,催生了包括知识增强型预训练、跨学科试题生成在内的一系列创新方法。后续研究进一步拓展至考试题目难度预测、错题模式分析等方向,形成了以学科知识图谱构建与智能教育应用为核心的完整研究脉络。
以上内容由遇见数据集搜集并总结生成


