19th-century-novelists
收藏Hugging Face2025-11-17 更新2025-11-18 收录
下载链接:
https://huggingface.co/datasets/Mosab-Rezaei/19th-century-novelists
下载链接
链接失效反馈官方服务:
资源简介:
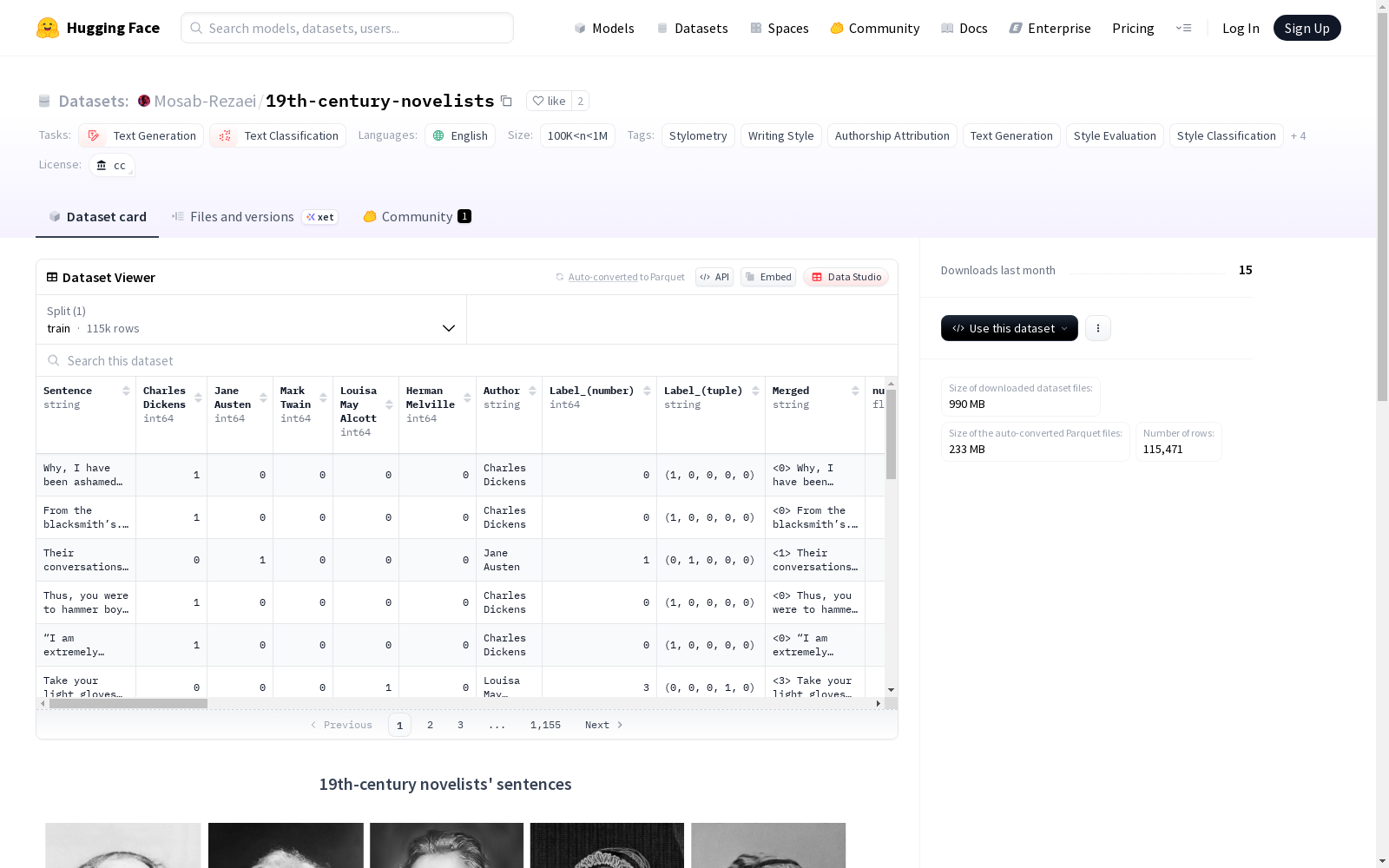
19世纪小说家句子数据集,包含来自五位杰出作家查尔斯·狄更斯、马克·吐温、赫尔曼·梅尔维尔、简·奥斯汀和路易莎·梅·奥尔科特的文本,共115,471个句子。数据集平衡了男性和女性作家以及英国和美国文学传统,提供了丰富的自动提取的句法特征注释,适用于风格分析和句法语义现象研究。
创建时间:
2025-11-17
原始信息汇总
19世纪小说家句子数据集概述
数据集基本信息
- 数据集名称: 19th-century novelists sentences
- 许可协议: CC
- 任务类别: 文本生成、文本分类
- 语言: 英语
- 数据规模: 10万<n<100万
数据集内容
- 数据来源: 古腾堡计划文本
- 涵盖作者: 查尔斯·狄更斯、马克·吐温、赫尔曼·梅尔维尔、简·奥斯汀、路易莎·梅·奥尔科特
- 作者构成: 平衡了男女作者以及英美文学传统
- 句子数量: 115,471个句子
- 处理工具: NLTK库进行句子分割,斯坦福CoreNLP (v4.5.7)进行分词和词数统计
数据特征
- 标注信息: 使用斯坦福CoreNLP自动提取的丰富标注
- 包含内容: 依存关系、解析树、低层次和高层次句法特征
- 应用价值: 为文体测量分析和更广泛的句法语义现象研究提供资源
研究应用
- 适用领域: 文体测量学、写作风格、作者归属、文本生成、风格评估、风格分类、可解释AI、基于提示的生成、大语言模型
引用信息
- 论文标题: "Generation, Evaluation, and Explanation of Novelists’ Styles with Single-Token Prompts"
- GitHub地址: https://github.com/mosabrezaei/Text-Generation-XAI
- 引用格式: @inproceedings{rezaei2025stylometry, title={Generation, Evaluation, and Explanation of Novelists’ Styles with Single-Token Prompts}, author={Rezaei, Mosab and Rajaei Moghadam, Mina and Shaikh, Abdul Rahman and Alhoori, Hamed and Freedman, Reva}, booktitle={ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL)}, year={2025}}
搜集汇总
数据集介绍
构建方式
在文学计算分析领域,该数据集以古登堡计划为文本来源,精选查尔斯·狄更斯、马克·吐温等五位19世纪小说家的作品,构建过程采用NLTK库完成句子分割,并通过斯坦福CoreNLP工具实现词汇统计与句法标注。这种构建策略既平衡了英美文学传统与性别代表性,又通过自动化流程提取出包含依存关系与解析树的多维度语言学特征,最终形成包含11.5万句的语料库。
特点
该数据集的核心价值在于其多层次标注体系,除原始句子外还囊括从词汇分布到句法结构的量化特征。这些特征为风格计量学研究提供了丰富维度,既能支撑作者身份归属任务,又可服务于生成模型的风格控制评估。其跨作者对比的设计框架特别适用于探究文化背景与性别因素对文学风格的影响机制,为可解释人工智能研究提供了理想实验场域。
使用方法
研究者可借助该数据集开展三类典型应用:通过文本分类任务验证作者风格识别模型,利用句法特征进行写作风格的可视化分析,或作为条件生成模型的风格参照基准。使用时应结合配套的斯坦福CoreNLP工具解析附加语言学标注,并注意遵循相关论文的引用规范以保障学术溯源性。
背景与挑战
背景概述
在数字人文与计算文体学蓬勃发展的背景下,19世纪小说家语句数据集应运而生,由研究团队基于古登堡计划文本构建。该数据集聚焦查尔斯·狄更斯、马克·吐温等五位代表性作家,巧妙平衡了英美文学传统与性别分布,为文体特征量化研究提供了重要基础。通过斯坦福CoreNLP工具实现句法结构与依存关系的多层标注,其包含的十一万余条语句不仅支撑作者归属任务,更成为解释性人工智能与风格生成研究的实验沃土。
当前挑战
文体分析领域长期面临作者风格量化与生成模型可控性的双重挑战。该数据集构建过程中需克服19世纪文学文本的拼写变异与句法复杂性,同时通过自动化工序确保句法标注的准确性。在应用层面,如何从有限作家样本中提取可迁移的文体特征,以及如何利用提示学习实现风格解耦与生成解释,仍是当前研究的核心难点。
常用场景
经典使用场景
在文学风格计量学领域,该数据集为19世纪小说家写作风格的量化研究提供了重要基础。通过整合狄更斯、马克·吐温等五位代表性作家的11万余条语句,研究者能够系统分析不同作者在句式结构、词汇选择等方面的独特特征,为风格分类与作者归属判定建立可靠基准。
解决学术问题
本数据集有效解决了传统文学分析中主观性强、难以量化的学术困境。通过斯坦福CoreNLP工具自动提取的依存关系与句法特征,使研究者能够精确捕捉作者风格标记,推动可解释人工智能在风格生成任务中的发展,为数字人文研究提供数据驱动的新范式。
衍生相关工作
基于该数据集衍生的经典研究包括《基于单令牌提示的小说家风格生成与解释》等突破性工作。这些研究通过融合大语言模型与风格计量学,开创了可控文本生成的新方向,后续研究进一步拓展至跨时代作家风格迁移、多模态文学分析等前沿领域。
以上内容由遇见数据集搜集并总结生成


