flickr30k-vietnamese
收藏Hugging Face2026-01-07 更新2026-01-08 收录
下载链接:
https://huggingface.co/datasets/ai-enthusiasm-community/flickr30k-vietnamese
下载链接
链接失效反馈官方服务:
资源简介:
Flickr30k-Vietnamese是基准Flickr30k数据集的越南语本地化版本,专门为越南跨模态研究而策划。该数据集包含31,783张来自Flickr的图片,每张图片配有五个相应的描述。此版本提供了原始英文标题和高质量的越南语翻译,支持在双语环境下进行图像描述、文本到图像检索和多模态学习等任务。
创建时间:
2026-01-07
原始信息汇总
Flickr30k-Vietnamese 数据集概述
数据集基本信息
- 名称: Flickr30k-Vietnamese
- 维护团队: AI Enthusiasm
- 语言: 越南语 (vi)、英语 (en)
- 许可证: CC-BY-4.0
- 数据规模: 100k < n < 1M
- 任务类别: 图像到文本 (image-to-text)、文本到图像 (text-to-image)
- 标签: vision, image-captioning, coco, vietnamese
- 主页: https://aienthusiasm.vn
数据集详情
- 来源: 基准数据集 Flickr30k 的本地化版本,专为越南语跨模态研究而策划。
- 内容: 包含 31,783 张来自 Flickr 的图像,每张图像配有五条对应的描述。
- 特点: 提供原始英文描述以及高质量的越南语翻译,支持双语上下文下的任务。
- 用途: 适用于图像描述生成、文本到图像检索和多模态学习等任务。
数据集结构
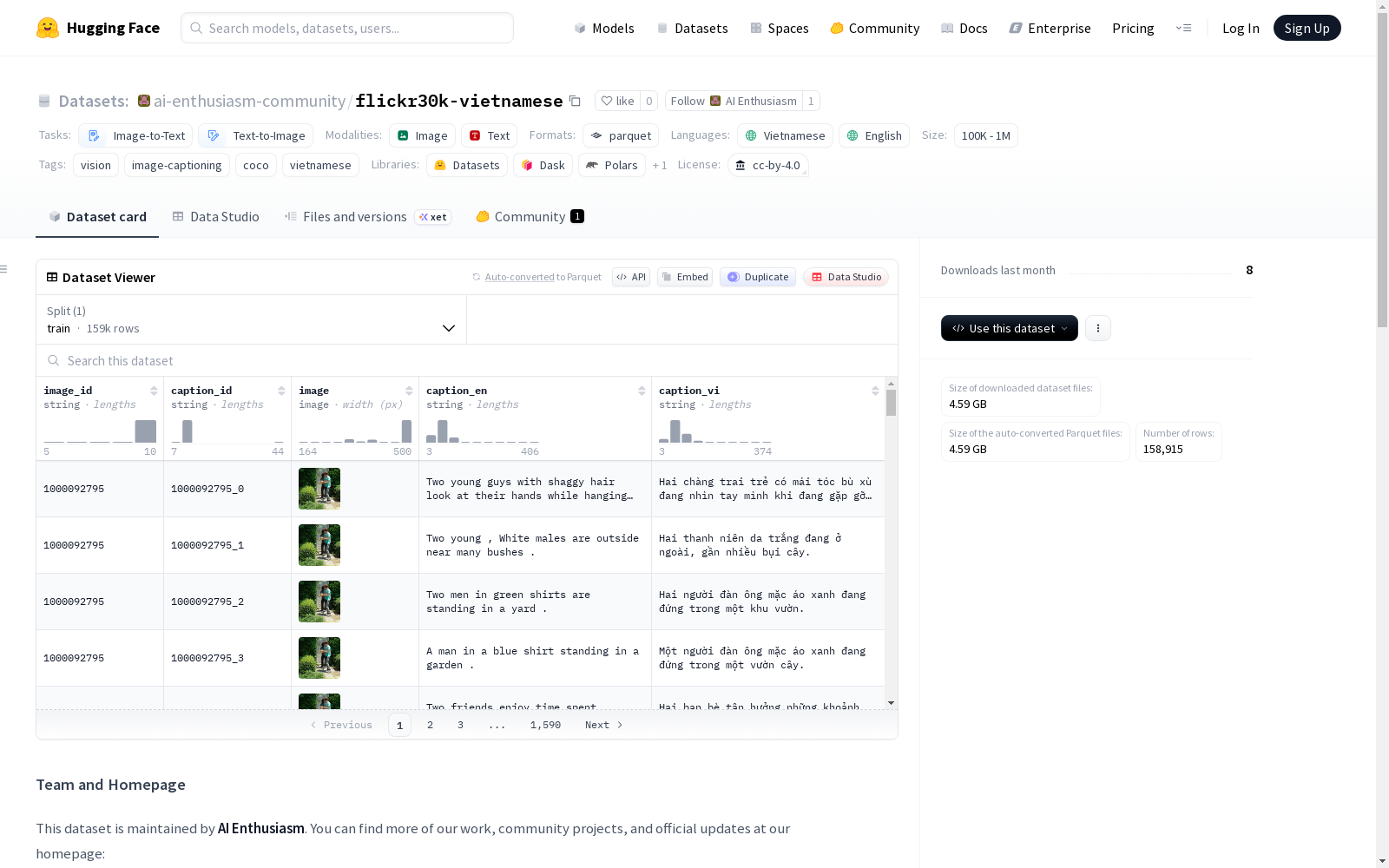
- 格式: 扁平化的表格格式,针对 Hugging Face Dataset Viewer 和高速 Parquet 处理进行了优化。
- 数据实例: 每个实例代表一个图像-描述对。由于每张图像包含五条描述,图像数据会在五行中重复以确保与标准训练流程兼容。
- 数据字段:
image_id: 原始的 Flickr 标识字符串。caption_id: 每条描述的唯一标识符,格式为{image_id}_{comment_number}。image: 包含视觉数据的图像对象。caption_en: 原始的英文描述文本。caption_vi: 翻译后的越南语描述文本。
数据划分与规模
- 划分: 训练集 (train)
- 训练集样本数: 158,915
- 训练集大小 (字节): 20,746,408,346.95
- 下载大小 (字节): 4,588,173,407
- 数据集总大小 (字节): 20,746,408,346.95
使用方式
可通过 Hugging Face datasets 库直接访问:
python
from datasets import load_dataset
dataset = load_dataset("ai-enthusiasm-community/flickr30k-vietnamese")
引用信息
@article{young2014image, title={From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions}, author={Young, Peter and Lai, Alice and Hodosh, Micah and Hockenmaier, Julia}, journal={Transactions of the Association for Computational Linguistics}, volume={2}, pages={67--78}, year={2014}, publisher={MIT Press} }
搜集汇总
数据集介绍
构建方式
在跨模态研究领域,数据集的构建往往需要兼顾视觉与文本的对应关系。Flickr30k-Vietnamese 数据集以 Flickr30k 基准数据集为基础,精选了 31,783 张来自 Flickr 平台的图像,每张图像均配有五条描述性文本。该版本不仅保留了原始的英文标注,还通过专业翻译流程生成了高质量的越南语译文,形成了双语对照的平行语料,为跨语言视觉语言任务提供了坚实基础。
特点
该数据集的核心特点体现在其双语结构与扁平化设计上。每张图像均对应五条英文描述及其越南语翻译,构建了丰富的多模态对齐样本。数据以扁平表格形式组织,图像数据在五个标注行中重复出现,确保了与标准训练流程的兼容性。这种设计既支持图像描述生成、文本到图像检索等任务,也为越南语环境下的多模态学习提供了独特资源。
使用方法
研究人员可通过 Hugging Face 的 datasets 库直接加载该数据集,便捷地获取图像与双语标注信息。典型应用场景包括训练跨语言图像描述模型、进行双语文本-图像检索实验,以及探索多模态表示学习。数据集的标准化格式便于集成到现有机器学习流程中,支持视觉与语言模型的联合训练与评估。
背景与挑战
背景概述
Flickr30k-Vietnamese数据集作为跨模态研究领域的重要资源,由AI Enthusiasm团队于近年构建,旨在扩展Flickr30k基准数据集的语种覆盖范围。该数据集源自2014年由Peter Young等人提出的原始Flickr30k数据集,其核心研究问题聚焦于图像描述生成与跨语言检索任务,通过提供高质量的越南语翻译标注,为越南语环境下的视觉语言理解研究提供了关键支持。这一努力不仅促进了多语言人工智能技术的发展,也为东南亚地区的本土化AI应用奠定了数据基础,推动了跨文化语境下的多模态模型性能评估与创新。
当前挑战
在图像描述生成领域,Flickr30k-Vietnamese数据集致力于解决越南语环境下视觉内容与自然语言对齐的挑战,包括跨语言语义一致性保持、文化特定概念准确翻译以及低资源语言标注质量保障等难题。数据构建过程中,团队面临的主要挑战涉及大规模图像描述的高精度人工翻译、双语对齐的语义完整性维护,以及原始图像数据与多语言标注间的结构适配,这些因素共同构成了数据集在技术实现与学术应用上的核心难点。
常用场景
经典使用场景
在跨模态人工智能研究领域,Flickr30k-Vietnamese数据集为图像描述生成任务提供了关键支持。该数据集通过将原始Flickr30k图像与高质量的越南语翻译描述配对,构建了一个双语视觉-语言基准。研究人员能够利用这一资源训练和评估模型,使其能够自动生成准确、流畅的越南语图像描述,从而推动多语言环境下的图像理解技术发展。
实际应用
在实际应用层面,Flickr30k-Vietnamese数据集为开发多语言图像搜索引擎、无障碍技术工具以及内容本地化平台提供了数据基础。例如,在东南亚地区的电子商务和社交媒体平台中,基于该数据集训练的模型能够自动为商品图片生成越南语描述,提升用户体验和内容可访问性。此外,它还可用于教育技术领域,辅助视觉障碍人士通过语音描述理解图像内容。
衍生相关工作
围绕该数据集,学术界衍生了一系列经典研究工作,主要集中在多语言图像描述生成模型和跨语言检索系统。例如,研究者利用该数据集的双语特性,开发了基于Transformer的编码器-解码器架构,实现了英语到越南语的描述迁移。同时,该数据集也促进了视觉-语言预训练模型在低资源语言上的适配研究,为后续如ViLT、BLIP等模型在越南语场景下的微调与评估提供了重要基准。
以上内容由遇见数据集搜集并总结生成


