【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
bot-yaya/parallel_corpus_game
收藏Hugging Face2024-12-09 更新2024-12-14 收录
下载链接:
https://hf-mirror.com/datasets/bot-yaya/parallel_corpus_game
下载链接
链接失效反馈官方服务:
资源简介:
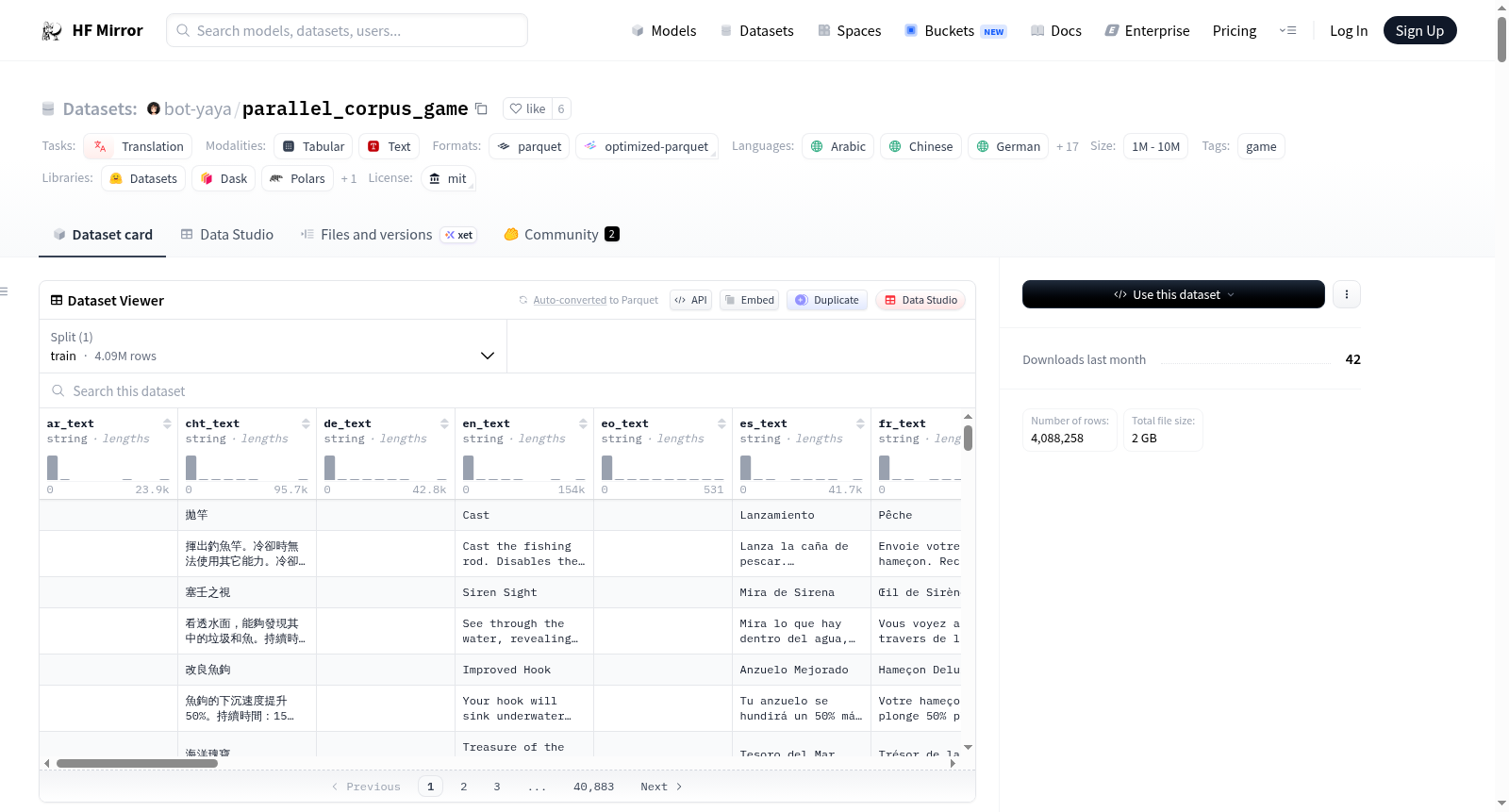
该数据集是一个包含多种语言文本的平行语料库,主要用于翻译任务。数据集包含来自29个不同游戏的语料文件,如《博德之门3》、《赛博朋克2077》、《黑暗之魂3》等。数据集的特征包括多种语言的文本字段、文件信息、段落统计和重复检查字段。数据集的分割仅包含训练集,且提供了字节数和示例数。数据集的许可证为MIT,支持多种语言,任务类别为翻译,标签为游戏。
The game corpus dataset provided by the MNBVC parallel corpus team, containing text data in multiple languages and related metadata. The dataset supports 19 languages including Arabic, Chinese, German, English, and is primarily used for translation tasks. The dataset is updated irregularly and currently includes corpus files from 29 games, such as Baldurs Gate 3, Cyberpunk 2077, etc.
提供机构:
bot-yaya
搜集汇总
数据集介绍
构建方式
在游戏本地化与多语言自然语言处理领域,构建高质量的平行语料库是推动机器翻译与跨语言理解模型发展的关键。该数据集由MNBVC平行语料团队系统性地采集与整合,其构建过程主要依赖于从广泛的游戏资源中提取多语言本地化文本。具体而言,团队从Steam平台、游戏官方网站及开源社区(如GitHub)等多个渠道,收集了涵盖《原神》、《赛博朋克2077》、《博德之门3》等122款热门游戏的原始本地化文件。这些文本经过解析、对齐与清洗,确保了不同语言版本间句子的精确对应,并辅以去重、质量标注等处理步骤,最终形成了覆盖20余种语言的规模化平行语料。
特点
该数据集在游戏文本领域展现出鲜明的多维特征。其最显著的优势在于语言覆盖的广度与深度,不仅囊括了英语、中文、日语等主流语言,亦包含了阿拉伯语、希伯来语、世界语等资源相对稀缺的语种,为低资源语言研究提供了宝贵素材。数据规模庞大,包含超过400万条平行句对,且来源游戏类型多样,从角色扮演、冒险解谜到模拟经营,文本风格与领域语境极为丰富。此外,数据集附带了详尽的元数据,如文件来源、行号、重复标识及质量标签,为数据筛选与针对性研究提供了精细化的支持。
使用方法
该数据集主要服务于机器翻译、跨语言信息检索及游戏本地化技术的研究与应用。使用者可通过Hugging Face数据集库直接加载,利用其标准的‘train’分割进行模型训练与评估。在具体应用中,研究人员可依据‘文件名’、‘低质量段落数’等字段对数据进行过滤与采样,以构建特定语言对或特定游戏领域的训练子集。对于多语言神经机器翻译模型,该数据集可作为大规模预训练或微调的基础资源;同时,其丰富的游戏领域术语与对话文本,也适用于领域自适应翻译、文化特定表达生成等前沿课题的探索。
背景与挑战
背景概述
在自然语言处理领域,多语言平行语料库对于机器翻译、跨语言信息检索等任务具有不可或缺的价值。bot-yaya/parallel_corpus_game数据集由MNBVC平行语料团队创建,其核心研究问题聚焦于从电子游戏中提取高质量、多语言的本地化文本,以构建一个覆盖广泛游戏类型与语言对的平行语料资源。该数据集自2025年起持续更新,汇集了《赛博朋克2077》、《巫师3:狂猎》、《原神》等上百款热门游戏的文本,涉及英语、中文、日语、韩语、俄语等二十余种语言。它不仅为游戏领域的机器翻译模型训练提供了稀缺的领域特定数据,也推动了跨文化语境下自然语言理解的研究,对多语言人工智能应用的发展产生了显著影响。
当前挑战
该数据集旨在解决游戏领域多语言本地化文本的机器翻译与跨语言对齐挑战,其核心难题在于游戏文本常包含大量文化特定表达、专业术语及非正式对话,导致翻译模型在保持语境与风格一致性上面临困难。在构建过程中,团队遭遇了多重挑战:首先,游戏文本分散于多种文件格式与加密资源中,数据提取与解析过程复杂且耗时;其次,确保不同语言版本间的句级对齐精度需要大量人工校验与自动化工具的结合,以避免语义偏差;此外,处理低质量段落、跨文件重复内容以及维护数据的最新性(如应对游戏版本更新)均对数据集的规模与质量构成了持续性的考验。
常用场景
经典使用场景
在游戏本地化与多语言自然语言处理领域,该数据集以其涵盖《赛博朋克2077》《巫师3:狂猎》等上百款热门游戏的平行语料而著称,为机器翻译模型的训练与评估提供了丰富资源。其多语言对齐特性使得研究者能够构建跨语言语义表示,探索游戏文本特有的文化隐喻与术语翻译规律,成为该领域基准测试的重要依托。
衍生相关工作
基于该数据集衍生的经典工作包括面向游戏术语的神经机器翻译模型优化、跨语言游戏对话生成系统以及多模态本地化质量评估框架。这些研究不仅深化了领域自适应翻译的理论体系,还催生了如游戏文本风格迁移、玩家生成内容的多语言同步等创新应用,持续拓展着游戏语言智能的技术边界。
数据集最近研究
最新研究方向
在游戏本地化与多语言自然语言处理领域,bot-yaya/parallel_corpus_game数据集作为大规模多语言平行语料库,正推动前沿研究向跨语言预训练模型优化与领域自适应翻译技术深化。该数据集涵盖超过120款热门游戏的多样化文本,其多语言对齐特性为低资源语言对机器翻译模型训练提供了珍贵资源,尤其在游戏术语与文化负载词处理上展现出独特价值。随着游戏产业全球化进程加速,该语料库支持的研究热点聚焦于上下文感知的神经机器翻译、对话系统跨语言迁移学习,以及多模态本地化生成技术,对提升游戏内容自动本地化效率与质量具有显著意义。
以上内容由遇见数据集搜集并总结生成


