czech-politician-statements
收藏Hugging Face2025-05-17 更新2025-05-18 收录
下载链接:
https://huggingface.co/datasets/tomn24/czech-politician-statements
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集包含来自Demagog项目的经过事实核实的捷克语声明及其元数据和从网络上抓取的证据文章。数据集分为多个子集,包括带有元数据的声明、手动和自动事实核查的精选子集以及用于事实核查的证据文章链接。数据集的主要目的是为了研究、开发和评估捷克语自动事实核查系统。
创建时间:
2025-05-16
原始信息汇总
Czech Politician Statements Dataset 概述
基本信息
- 语言: 捷克语 (cs)
- 许可证: MIT
- 数据规模: 10K<n<100K
- 任务类别: 文本分类
- 标签: 事实核查、证据检索
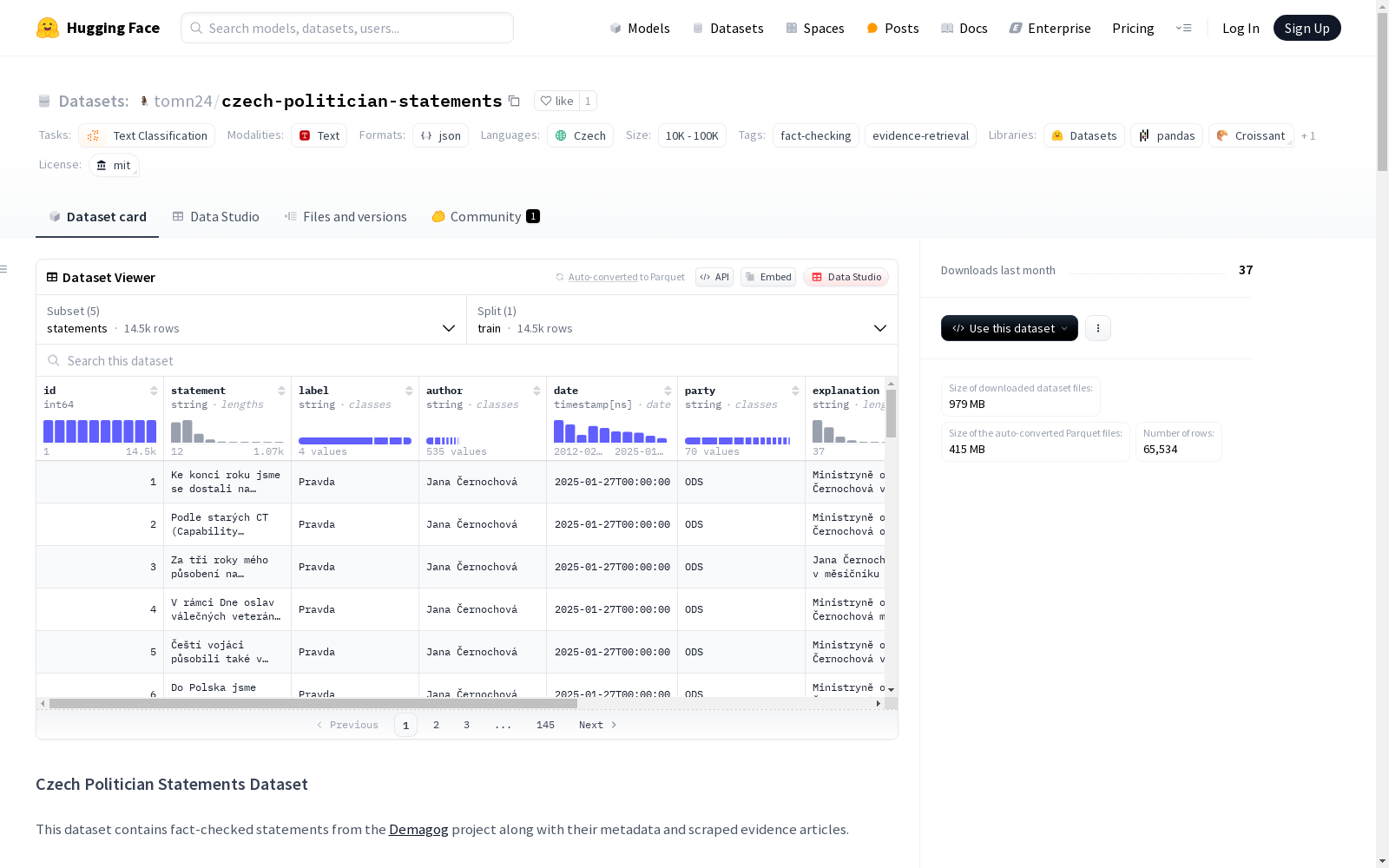
数据集结构
包含5个子集配置:
statements: 基础声明数据 (默认配置)articles: 证据文章数据article_links: 声明关联的文章链接curated_statements: 人工精选声明子集auto_curated_statements: 自动精选声明子集
数据内容
声明数据 (statements)
包含政治声明的完整元数据:
- ID
- 声明文本
- 真实性标签 (如"Pravda"/"Nepravda")
- 作者
- 日期
- 所属党派
- 详细解释
- 简要解释
- 来源
- 关联文章ID列表
精选子集
- 人工精选子集:
- 包含手工选取的证据段落
- 标签类型:真实/虚假/不可验证
- 自动精选子集:
- 使用LLM多跳证据检索+COT预测生成
- 标签类型:真实/虚假
文章数据 (articles)
包含抓取的证据文章:
- ID
- URL
- 标题
- 描述
- 内容(原始和处理后版本)
- 类型
- 作者
- 来源网站
- 发布时间
- 访问时间
文章链接 (article_links)
记录每个声明关联的证据链接:
- 声明ID
- 证据链接列表(可能包含失效链接)
数据来源
- 主要来源:Demagog项目
- 数据处理:
- 移除声明中所有"demagog"词汇
- 使用extractus/article-extractor处理证据文章
创建目的
支持捷克语自动事实核查系统的研究、开发和评估
局限性与风险
- 数据标注完全依赖Demagog的方法论
- 精选子集可能存在实验性偏差
- 部分文章链接可能失效
- 抓取的文章内容可能不完整
引用信息
bibtex @online{nguyen2025factual, author = {Nguyen, Hai Phong}, title = {Factual checking and reliability of sources from open media}, year = {2025}, note = {Bachelors thesis. Supervised by Petr Motlíček, with primary guidance from Sergio Burdisso (Idiap Research Institute). }, institution = {Brno University of Technology, Faculty of Information Technology}, howpublished = {url{https://www.vut.cz/en/students/final-thesis/detail/165312}}, type = {Online}, accessdate = {2025-05-16} }
作者信息
- 开发人员:Hai Phong Nguyen
- 机构:布尔诺理工大学信息学院
- 联系方式:tomas.nguyen138@gmail.com
搜集汇总
数据集介绍
构建方式
该数据集源自捷克Demagog项目,通过系统化爬取政客公开声明及其元数据构建而成。研究人员采用自动化工具从Demagog官网提取声明文本,并移除了所有'demagog'字样的干扰信息。证据文章链接通过网络爬虫获取,并运用extractus/article-extractor库进行内容解析处理。数据集包含原始声明、人工精选和自动精选三个子集,其中人工精选子集由专家标注相关证据段落,自动精选子集则采用大语言模型驱动的多跳证据检索与思维链预测技术构建。
使用方法
该数据集主要服务于自动事实核查系统的研发与评估。研究者可通过statements子集进行基础真实性分类实验,利用curated_statements子集开展基于证据的细粒度分析。对于证据检索任务,article_links和articles子集提供了完整的证据链参照。使用自动精选子集时需注意其可能存在的模型偏差,建议与人工标注子集进行对比验证。所有数据以JSON格式组织,通过article_ids字段可实现声明与证据文章的高效关联查询。
背景与挑战
背景概述
捷克政治家言论数据集(Czech Politician Statements Dataset)由捷克布尔诺理工大学信息学院的研究人员Hai Phong Nguyen等人于2025年创建,旨在为捷克语自动事实核查系统的研究与开发提供数据支持。该数据集基于非营利组织Demagog的事实核查项目,收录了经过专业验证的政治家公开声明及其元数据,同时整合了相关的证据文章。作为中东欧地区首个专注于政治言论真实性判定的语料库,该数据集填补了斯拉夫语系在 computational fact-checking 领域的空白,为政治传播学、自然语言处理等跨学科研究提供了重要资源。
当前挑战
该数据集面临多重挑战:在领域问题层面,政治言论的真实性判定涉及复杂的语境理解和多源证据交叉验证,要求模型具备细粒度的语义推理能力;在数据构建层面,捷克语的形态复杂性导致文本预处理困难,证据文章的爬取存在链接失效和内容残缺问题。此外,手动标注子集虽能提供高质量监督信号,但标注成本高昂且难以扩展;而基于大语言模型的自动标注子集虽提升了规模效率,却可能引入模型固有偏见。如何平衡标注质量与数据规模,以及如何处理证据文章中的多模态信息,仍是待解决的关键问题。
常用场景
经典使用场景
在政治话语分析领域,Czech Politician Statements数据集为研究者提供了丰富的捷克政治人物言论及其事实核查结果。该数据集最经典的使用场景在于训练和评估自动事实核查系统,特别是在多跳证据检索和文本分类任务中。通过分析政治人物的公开声明与核查证据之间的关联,研究人员能够深入探究言论真实性判定的内在机制。
解决学术问题
该数据集有效解决了政治话语真实性验证这一重要学术问题。其标注的真实性标签(如Pravda/Nepravda)与详尽的解释说明,为自然语言处理领域提供了宝贵的监督信号。特别值得注意的是,数据集包含手工精选和自动生成的证据段落,这为研究证据充分性判定、多文档推理等NLP核心问题提供了独特的研究素材,推动了自动事实核查技术的发展。
实际应用
在实际应用层面,该数据集支撑了多个面向公众的政治事实核查平台开发。媒体机构可利用其构建自动化的政治言论监测系统,实时追踪政治人物声明的真实性。政府部门也能基于该数据集开发决策辅助工具,在政策辩论中快速验证相关事实依据。数据集特有的捷克语特性,更为中东欧地区的政治话语分析提供了重要基础。
数据集最近研究
最新研究方向
在政治言论真实性验证领域,捷克政治人物言论数据集为研究者提供了丰富的标注资源,推动了自动事实核查技术的发展。当前研究聚焦于多模态证据检索与大型语言模型在事实核查中的协同应用,通过结合人工精选证据段落与自动化检索技术,提升系统对复杂政治言论的验证能力。该数据集独特的双语种特性为跨语言事实核查研究提供了实验平台,尤其在处理东欧语言文本理解任务上展现出重要价值。随着虚假信息检测成为全球性议题,该数据集在政治传播学与计算语言学交叉领域的研究中扮演着关键角色,为开发鲁棒性更强的自动化事实核查系统奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


