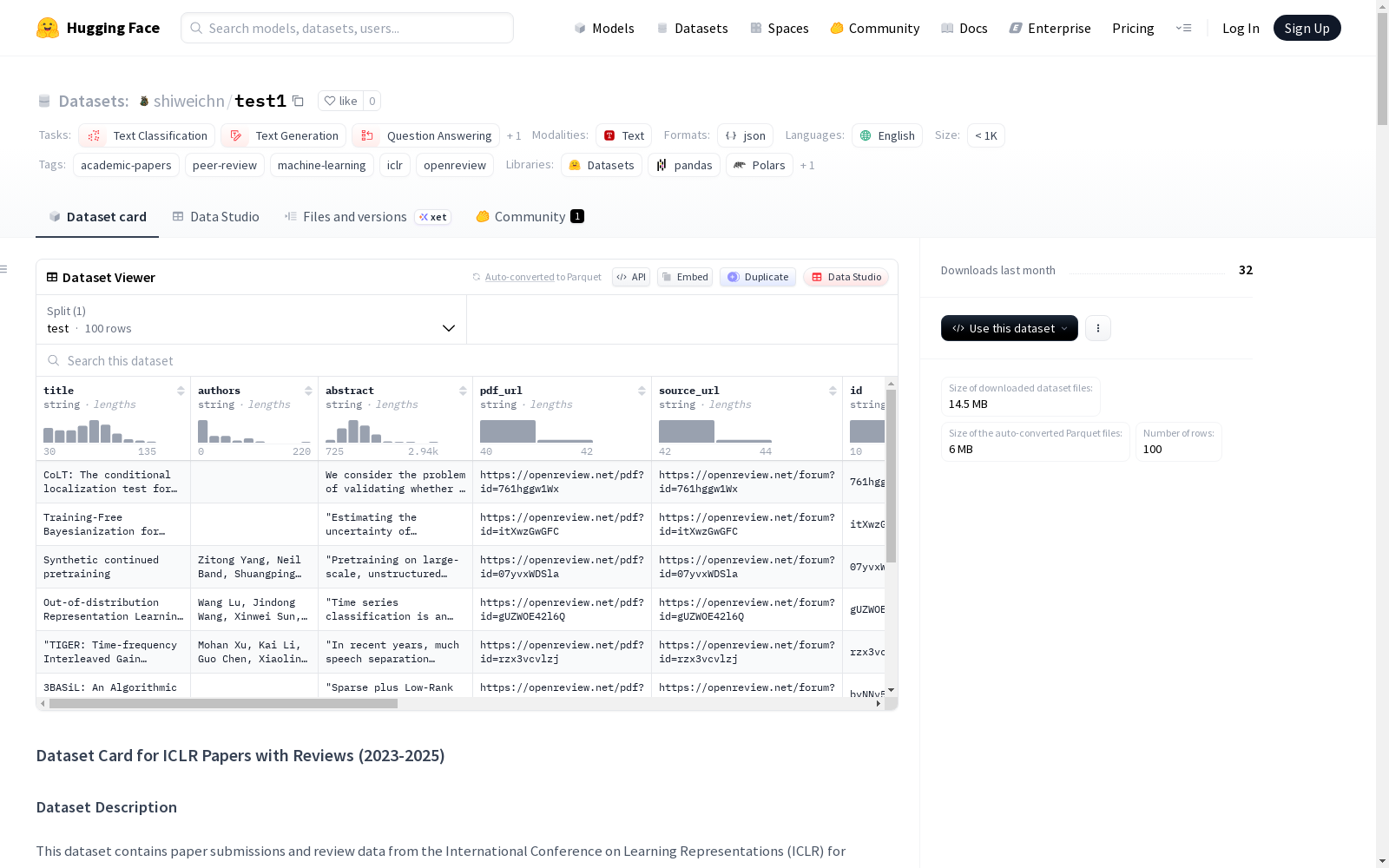
test1
收藏ICLR Papers with Reviews (2023-2025) 数据集概述
数据集基本信息
- 数据集名称:ICLR Papers with Reviews (2023-2025)
- 创建者:机器生成
- 语言:英语
- 语言来源:发现
- 多语言性:单语
- 大小类别:10K<n<100K
- 来源数据集:原始
- 任务类别:文本分类、文本生成、问答、摘要
- 标签:学术论文、同行评审、机器学习、iclr、openreview
数据集描述
该数据集包含2023、2024和2025年国际学习表征会议(ICLR)的论文投稿和评审数据。数据来源于开放同行评审平台OpenReview。
数据重点
数据集强调围绕学术论文的同行评审生态系统。每条记录包含全面的评审相关信息:
- 相关笔记:包含来自OpenReview平台的评审讨论、元评审、作者回复和社区反馈。
- 完整论文内容:Markdown格式的完整论文文本。
- 评审元数据:包括页面统计、目录和文档结构分析的结构化元数据。
评审数据捕获了完整的同行评审工作流程:
- 来自多位评审人的初始投稿评审。
- 作者反驳和回复轮次。
- 领域主席的元评审。
- 最终决定通知(接受/拒绝)。
- 发表后的讨论和社区评论。
数据集统计
- 论文总数:8,310
- 覆盖年份:2023-2025
- 数据来源:OpenReview平台
- 会议:国际学习表征会议(ICLR)
- 内容:完整论文文本 + 完整的评审讨论
数据集结构
数据实例
每个实例代表一篇论文及其相关的评审数据。 json { "id": "RUzSobdYy0V", "title": "Quantifying and Mitigating the Impact of Label Errors on Model Disparity Metrics", "authors": "Julius Adebayo, Melissa Hall, Bowen Yu, Bobbie Chern", "abstract": "Errors in labels obtained via human annotation adversely affect...", "year": "2023", "conference": "ICLR", "related_notes": "[Review discussions, meta-reviews, and author responses]", "pdf_url": "https://openreview.net/pdf?id=RUzSobdYy0V", "source_url": "https://openreview.net/forum?id=RUzSobdYy0V", "content": "[Full paper text in Markdown format]", "content_meta": "[JSON metadata with TOC and page statistics]" }
数据字段
| 字段 | 类型 | 描述 |
|---|---|---|
id |
字符串 | 唯一的OpenReview论文ID |
title |
字符串 | 论文标题 |
authors |
字符串 | 作者姓名(逗号分隔) |
abstract |
字符串 | 论文摘要 |
year |
字符串 | 发表年份(2023-2025) |
conference |
字符串 | 会议名称(ICLR) |
related_notes |
字符串 | 评审数据 - 包含评审、元评审、讨论 |
pdf_url |
字符串 | OpenReview上PDF的链接 |
source_url |
字符串 | OpenReview上论文论坛的链接 |
content |
字符串 | Markdown格式的完整论文内容 |
content_meta |
字符串 | JSON元数据(目录、页面统计、结构) |
评审数据结构
related_notes字段包含来自OpenReview的完整评审历史,包括:
- 主要评审:每篇论文来自3-4位评审人的详细评审。
- 评审人评分:数值分数和置信度。
- 作者回复:作者的反驳和澄清。
- 元评审:领域主席的总结和建议。
- 最终决定:接受/拒绝决定及理由。
- 决定后讨论:社区评论和反馈。
数据划分
数据集没有预定义的划分。用户应根据其特定用例创建自己的训练/验证/测试划分。
数据集创建
策划理由
创建此数据集是为了促进对机器学习会议同行评审过程的理解和改进研究。通过将完整论文内容与完整的评审讨论相结合,研究人员可以:
- 分析论文特征与评审结果之间的关系。
- 研究建设性评审中的语言和模式。
- 构建协助评审人或作者的系统。
- 调查同行评审的公平性和偏见。
源数据
数据收集自OpenReview平台,该平台以开放格式托管ICLR评审过程。所有评审、讨论和决定均在OpenReview网站上公开可用。
数据处理
- 论文内容提取:从PDF源将完整论文转换为Markdown格式。
- 评审聚合:从OpenReview论坛提取评审讨论。
- 质量过滤:删除缺少基本字段(ID、内容或相关笔记)的记录。
- 元数据提取:从论文中提取结构元数据(目录、页面统计)。
使用注意事项
数据集的社会影响
该数据集提供了对通常不透明的同行评审过程的透明度。通过公开评审和讨论,它能够:
- 分析评审质量和一致性。
- 识别评估中的潜在偏见。
- 开发辅助评审过程的工具。
- 提供理解同行评审的教育资源。
偏见讨论
数据集可能包含多种偏见:
- 评审人偏见:不同的评审人可能有不同的标准和倾向。
- 会议特定规范:ICLR评审规范可能与其他场所不同。
- 时间变化:评审标准可能在2023-2025年间发生变化。
- 选择偏见:此数据集中的论文代表ICLR投稿,可能无法推广到所有机器学习研究。
其他已知限制
- 评审人身份被匿名化以保护隐私。
- 部分论文可能具有不完整的评审历史(例如,撤回的投稿)。
related_notes字段包含非结构化文本,可能需要进行解析以进行特定分析。
附加信息
数据集策划者
该数据集从公开可用的OpenReview数据编译而成。
许可信息
数据集中的论文和评审受OpenReview平台及各自作者的版权和使用条款约束。
引用信息
bibtex @dataset{iclr_papers_with_reviews, title = {ICLR Papers with Reviews (2023-2025)}, author = {Dataset Curator}, year = {2025}, note = {Compiled from OpenReview platform data} }
贡献
该数据集是通过从OpenReview平台提取和聚合公开可用数据而创建的,用于研究目的。