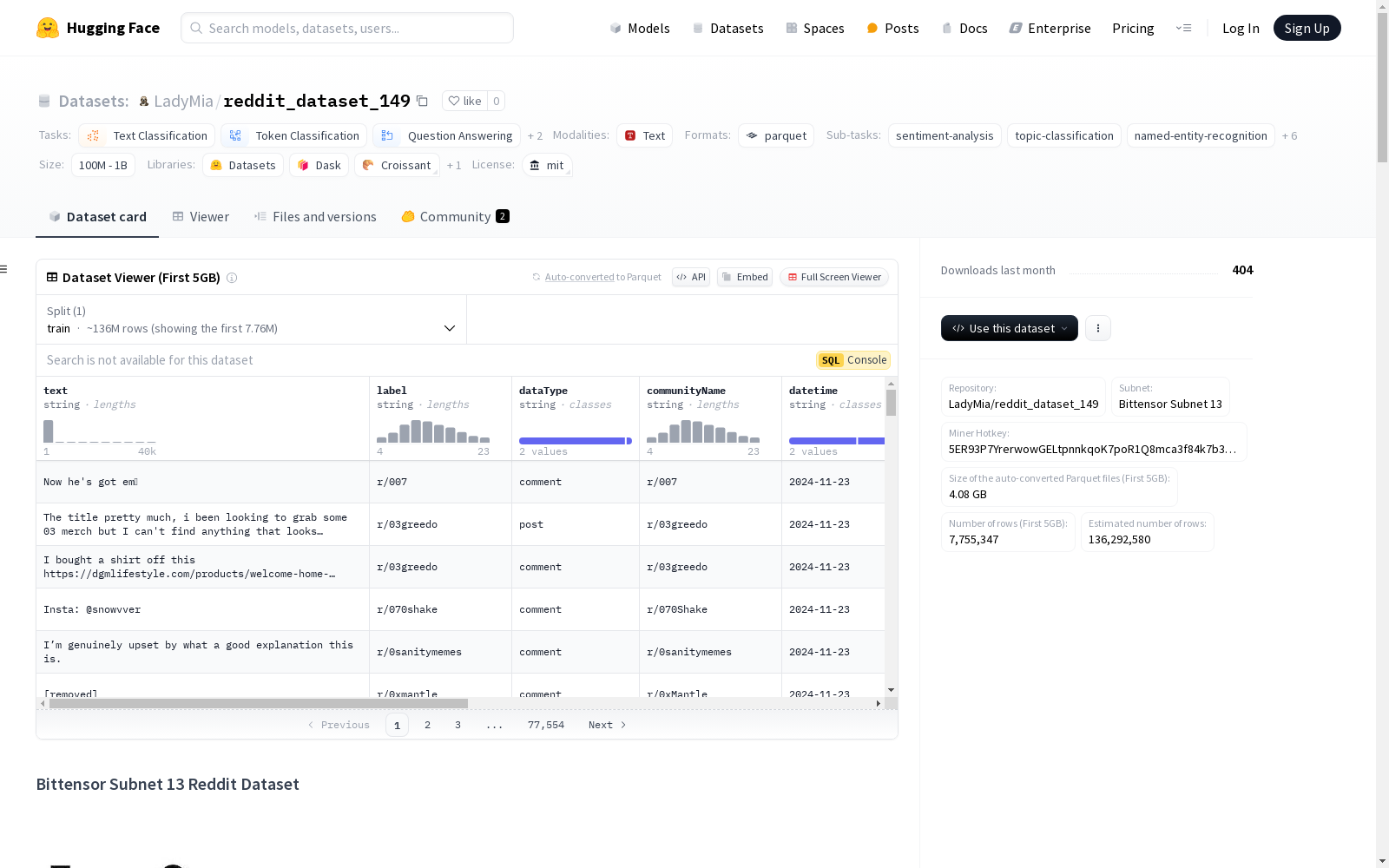
reddit_dataset_149
收藏Bittensor Subnet 13 Reddit Dataset
Dataset Description
- Repository: LadyMia/reddit_dataset_149
- Subnet: Bittensor Subnet 13
- Miner Hotkey: 5ER93P7YrerwowGELtpnnkqoK7poR1Q8mca3f84k7b3nig3D
Dataset Summary
This dataset is part of the Bittensor Subnet 13 decentralized network, containing preprocessed Reddit data. The data is continuously updated by network miners, providing a real-time stream of Reddit content for various analytical and machine learning tasks.
Supported Tasks
- Sentiment Analysis
- Topic Modeling
- Community Analysis
- Content Categorization
Languages
Primary language: Datasets are mostly English, but can be multilingual due to decentralized ways of creation.
Dataset Structure
Data Instances
Each instance represents a single Reddit post or comment with the following fields:
Data Fields
text(string): The main content of the Reddit post or comment.label(string): Sentiment or topic category of the content.dataType(string): Indicates whether the entry is a post or a comment.communityName(string): The name of the subreddit where the content was posted.datetime(string): The date when the content was posted or commented.username_encoded(string): An encoded version of the username to maintain user privacy.url_encoded(string): An encoded version of any URLs included in the content.
Data Splits
This dataset is continuously updated and does not have fixed splits. Users should create their own splits based on their requirements and the datas timestamp.
Dataset Creation
Source Data
Data is collected from public posts and comments on Reddit, adhering to the platforms terms of service and API usage guidelines.
Personal and Sensitive Information
All usernames and URLs are encoded to protect user privacy. The dataset does not intentionally include personal or sensitive information.
Considerations for Using the Data
Social Impact and Biases
Users should be aware of potential biases inherent in Reddit data, including demographic and content biases. This dataset reflects the content and opinions expressed on Reddit and should not be considered a representative sample of the general population.
Limitations
- Data quality may vary due to the nature of media sources.
- The dataset may contain noise, spam, or irrelevant content typical of social media platforms.
- Temporal biases may exist due to real-time collection methods.
- The dataset is limited to public subreddits and does not include private or restricted communities.
Additional Information
Licensing Information
The dataset is released under the MIT license. The use of this dataset is also subject to Reddit Terms of Use.
Citation Information
If you use this dataset in your research, please cite it as follows:
@misc{LadyMia2024datauniversereddit_dataset_149, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={LadyMia}, year={2024}, url={https://huggingface.co/datasets/LadyMia/reddit_dataset_149}, }
Contributions
To report issues or contribute to the dataset, please contact the miner or use the Bittensor Subnet 13 governance mechanisms.
Dataset Statistics
- Total Instances: 37221287
- Date Range: 2024-11-23T00:00:00Z to 2024-11-30T00:00:00Z
- Last Updated: 2024-11-30T08:35:12Z
Data Distribution
- Posts: 6.09%
- Comments: 93.91%
Top 10 Subreddits
| Rank | Topic | Total Count | Percentage |
|---|---|---|---|
| 1 | r/AskReddit | 327580 | 0.88% |
| 2 | r/CFB | 191250 | 0.51% |
| 3 | r/AITAH | 181540 | 0.49% |
| 4 | r/nfl | 167411 | 0.45% |
| 5 | r/politics | 119413 | 0.32% |
| 6 | r/Pixelary | 116224 | 0.31% |
| 7 | r/NoStupidQuestions | 102496 | 0.28% |
| 8 | r/teenagers | 99724 | 0.27% |
| 9 | r/repost | 88206 | 0.24% |
| 10 | r/mildlyinfuriating | 79357 | 0.21% |
Update History
| Date | New Instances | Total Instances |
|---|---|---|
| 2024-11-23T08:11:02Z | 763287 | 763287 |
| 2024-11-26T20:17:50Z | 18353497 | 19116784 |
| 2024-11-30T08:35:12Z | 18104503 | 37221287 |