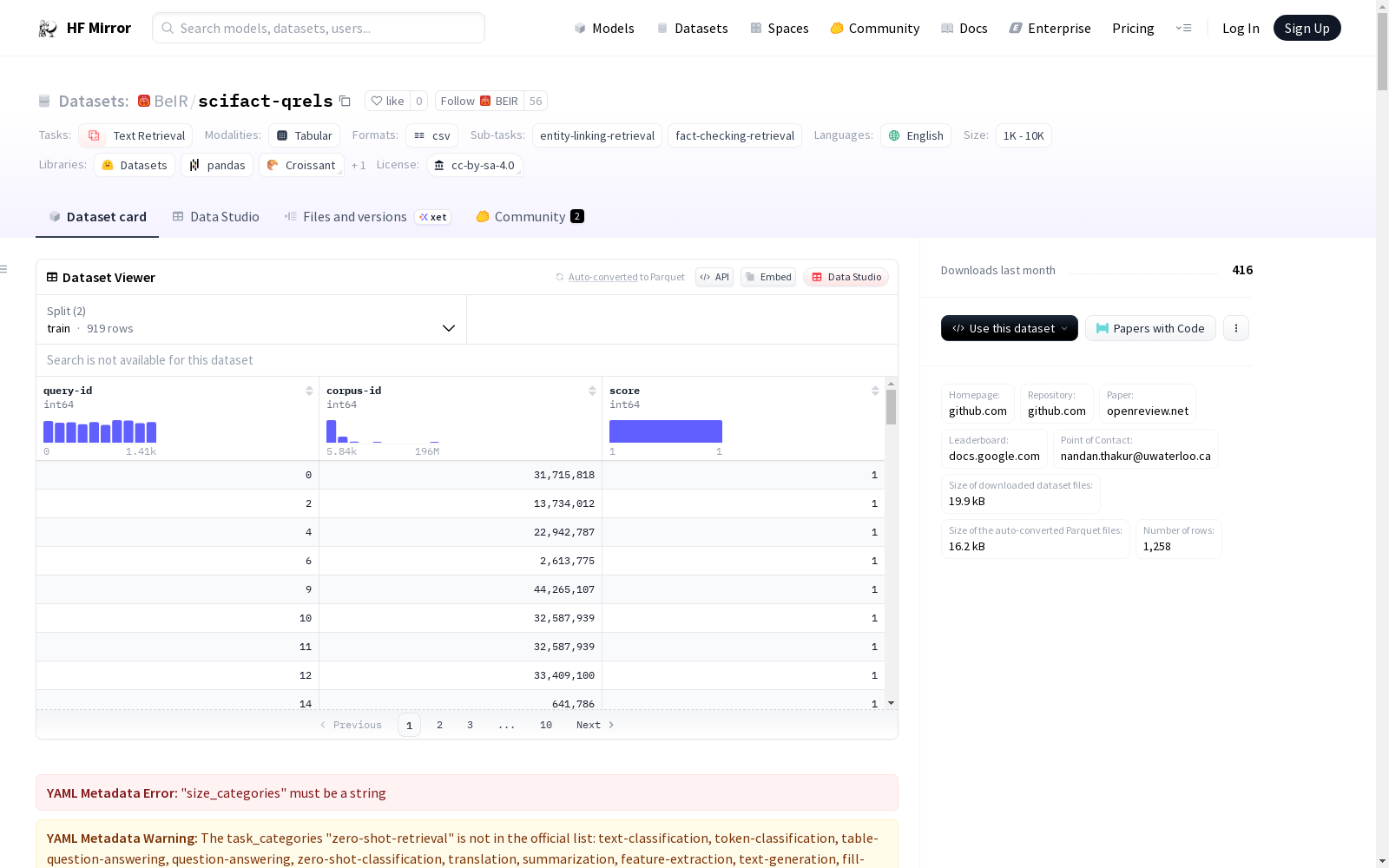
BeIR/scifact-qrels
收藏Hugging Face2022-10-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/BeIR/scifact-qrels
下载链接
链接失效反馈官方服务:
资源简介:
BEIR Benchmark是一个异构的基准测试,由18个不同的数据集组成,涵盖了9种信息检索任务,包括事实核查、问答、生物医学信息检索、新闻检索、论点检索、重复问题检索、引用预测、推文检索和实体检索。所有数据集均为英文,并已预处理,可用于实验。数据集的结构包括corpus、queries和qrels文件,分别用于存储文档、查询和查询与文档的相关性判断。
The BEIR Benchmark is a heterogeneous benchmark consisting of 18 distinct datasets, covering 9 information retrieval tasks including fact checking, question answering, biomedical information retrieval, news retrieval, argument retrieval, duplicate question retrieval, citation prediction, tweet retrieval, and entity retrieval. All datasets are in English and have been preprocessed for experimental use. The datasets are structured with corpus, queries, and qrels files, which are respectively used to store documents, queries, and relevance judgments between queries and documents.
提供机构:
BeIR
原始信息汇总
数据集概述
数据集名称: BEIR Benchmark
数据集简介: BEIR是一个异构基准,由18个不同数据集组成,代表9种信息检索任务。这些数据集包括事实检查、问答、生物医学信息检索、新闻检索等多个领域。
语言: 英语 (en)
许可证: CC-BY-SA-4.0
多语言性: 单语
数据集结构
数据集组成部分:
- corpus: 包含文档标题和文本的
.jsonl文件。 - queries: 包含查询文本的
.jsonl文件。 - qrels: 包含查询与文档相关性评分的
.tsv文件。
数据实例格式:
- corpus: 每个文档包含唯一标识符
_id、标题title和文本text。 - queries: 每个查询包含唯一标识符
_id和文本text。 - qrels: 包含查询ID、文档ID和评分。
数据集大小
各数据集大小范围:
- msmarco, nq, hotpotqa, dbpedia, fever, climate-fever: 1M<n<10M
- trec-covid, touche-2020, cqadupstack, scidocs, scifact: 100k<n<1M
- nfcorpus, arguana: 1K<n<10K
- fiqa: 10K<n<100K
支持的任务
任务类别:
- 文本检索
- 零样本检索
- 信息检索
- 零样本信息检索
具体任务:
- 段落检索
- 实体链接检索
- 事实检查检索
- 推文检索
- 引用预测检索
- 重复问题检索
- 论点检索
- 新闻检索
- 生物医学信息检索
- 问答检索
数据集创建
许可证信息: CC-BY-SA-4.0
引用信息:
@inproceedings{ thakur2021beir, title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models}, author={Nandan Thakur and Nils Reimers and Andreas R{"u}ckl{e} and Abhishek Srivastava and Iryna Gurevych}, booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)}, year={2021}, url={https://openreview.net/forum?id=wCu6T5xFjeJ} }
搜集汇总
数据集介绍
构建方式
BEIR Benchmark 数据集的构建旨在为信息检索领域提供一个异构的基准测试平台,涵盖了18个不同的数据集,这些数据集分别代表了9个信息检索任务。数据集的构建过程包括对原始数据集的预处理,以确保数据的一致性和可使用性。所有数据集都被转换为统一的格式,包括文档集、查询集和相关性判断文件,以便于研究人员进行实验和模型评估。
特点
BEIR Benchmark 数据集的特点在于其多样性。它涵盖了广泛的信息检索任务,如事实核查、问答、生物医学信息检索、新闻检索、论证检索、重复问题检索、引文预测、推文检索和实体检索。数据集包含了大量的英文文档和查询,以及由专家标注的相关性判断。此外,数据集还支持排行榜功能,可以评估模型在特定任务上的性能,如F1分数或EM分数,以及从维基百科中检索支持信息的能力。
使用方法
使用 BEIR Benchmark 数据集的方法包括以下几个步骤:首先,从官方网站下载所需的数据集。然后,根据数据集的格式要求,将数据集转换为统一的格式,包括文档集、查询集和相关性判断文件。接下来,可以使用数据集进行模型训练和评估。在模型训练过程中,可以使用相关性判断文件作为监督信号。在模型评估过程中,可以使用排行榜功能来评估模型在不同任务上的性能。最后,可以将模型的性能与其他研究人员的模型进行比较,以便于进一步改进模型。
背景与挑战
背景概述
在信息检索领域,模型的评估和比较一直是一个挑战,尤其是在跨任务和跨领域的场景下。BEIR(Benchmark for Evaluating Information Retrieval)数据集旨在解决这个问题,它是一个异构的基准数据集,由18个不同的数据集组成,代表了9个信息检索任务,包括事实核查、问答、生物医学信息检索、新闻检索、论点检索、重复问题检索、引文预测、推文检索和实体检索。BEIR数据集由英国伦敦大学学院的UKP实验室创建,旨在提供一个统一的评估平台,用于评估信息检索模型在不同任务和领域上的表现。BEIR数据集的创建对于信息检索领域的研究具有重要意义,它不仅为研究人员提供了一个标准的数据集,而且也为模型的开发和应用提供了一个参考标准。
当前挑战
BEIR数据集在创建过程中面临着一些挑战。首先,数据集的多样性导致了数据格式和结构的差异,这给数据集的整合和标准化带来了困难。其次,由于数据集的规模庞大,数据的预处理和清洗工作也是一个挑战。此外,数据集的标注质量也是一个重要的问题,它直接影响到模型评估的准确性。为了解决这些问题,BEIR数据集的创建者采用了多种技术手段,包括数据清洗、数据标注和模型评估等。然而,这些方法仍然存在一些局限性,例如数据清洗可能会去除一些有用的信息,数据标注可能会引入主观性,模型评估可能会忽略一些重要的因素。因此,BEIR数据集的创建和应用仍然面临着一些挑战,需要进一步的研究和探索。
常用场景
经典使用场景
在信息检索领域,BEIR数据集被广泛应用于评估和比较不同模型的性能。该数据集包含了来自18个不同来源的多样化数据集,涵盖了9个信息检索任务,包括事实核查、问答系统、生物医学信息检索、新闻检索、论点检索、重复问题检索、引文预测、推文检索和实体检索。这使得BEIR成为一个全面的信息检索基准,能够有效地评估模型在处理各种文本检索任务时的性能。
实际应用
BEIR数据集的实际应用场景非常广泛,包括但不限于搜索引擎、问答系统、推荐系统、文本摘要等。例如,搜索引擎可以利用BEIR数据集来评估和改进其检索算法,问答系统可以利用BEIR数据集来训练和评估其问答模型,推荐系统可以利用BEIR数据集来评估和改进其推荐算法,文本摘要可以利用BEIR数据集来评估和改进其摘要算法。此外,BEIR数据集还可以用于开发新的信息检索技术和方法,推动信息检索领域的发展。
衍生相关工作
BEIR数据集的发布,引发了信息检索领域的一系列相关工作。例如,一些研究者利用BEIR数据集来评估和比较不同模型的性能,发现了一些有趣的规律和现象。另外,一些研究者利用BEIR数据集来开发新的信息检索技术和方法,例如基于深度学习的检索模型、基于知识图谱的检索模型等。此外,还有一些研究者利用BEIR数据集来研究信息检索领域的其他问题,例如数据集的偏差问题、模型的可解释性问题等。这些相关工作不仅推动了信息检索领域的发展,也为其他领域的研究提供了重要的参考和借鉴。
以上内容由遇见数据集搜集并总结生成


