xnli_eval_multirepr
收藏Hugging Face2026-04-05 更新2026-04-06 收录
下载链接:
https://huggingface.co/datasets/mugezhang/xnli_eval_multirepr
下载链接
链接失效反馈官方服务:
资源简介:
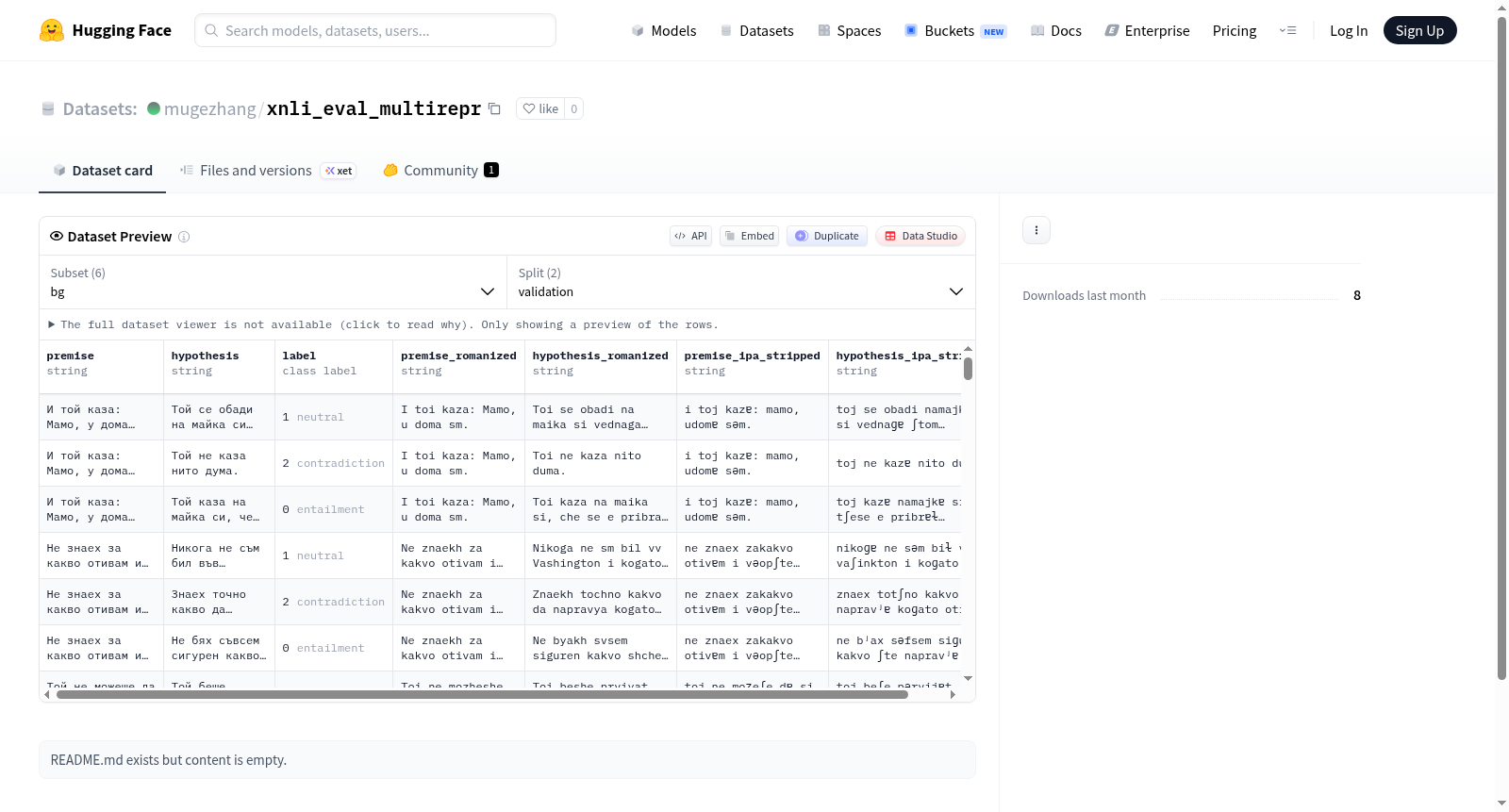
该数据集是一个多语言自然语言推理(NLI)数据集,包含保加利亚语(bg)、孟加拉语(bn)、英语(en)、西班牙语(es)、印地语(hi)和俄语(ru)六个语言的配置。每个语言配置包含验证集和测试集,样本数量分别为2490和5010。数据特征包括前提(premise)、假设(hypothesis)和标签(label),其中标签分为三类:蕴含(entailment)、中性(neutral)和矛盾(contradiction)。此外,还提供了前提和假设的罗马化版本(romanized)以及去除音标符号的IPA版本(ipa_stripped)。该数据集适用于多语言自然语言理解、文本蕴含识别等任务。
创建时间:
2026-04-05
原始信息汇总
数据集概述:xnli_eval_multirepr
数据集基本信息
- 数据集地址:https://huggingface.co/datasets/mugezhang/xnli_eval_multirepr
- 配置数量:6种语言配置
- 任务类型:自然语言推理(文本蕴含分类)
数据集配置与语言
数据集包含以下6种语言配置:
- bg:保加利亚语
- bn:孟加拉语
- en:英语
- es:西班牙语
- hi:印地语
- ru:俄语
数据特征
所有语言配置均包含以下7个特征字段:
- premise:前提文本(字符串类型)
- hypothesis:假设文本(字符串类型)
- label:标签(分类标签)
- 标签映射:
0对应 entailment(蕴含),1对应 neutral(中立),2对应 contradiction(矛盾)
- 标签映射:
- premise_romanized:前提文本的罗马化表示(字符串类型)
- hypothesis_romanized:假设文本的罗马化表示(字符串类型)
- premise_ipa_stripped:前提文本的IPA剥离表示(字符串类型)
- hypothesis_ipa_stripped:假设文本的IPA剥离表示(字符串类型)
数据划分
每个语言配置均包含两个数据划分:
- validation(验证集)
- test(测试集)
数据规模统计
保加利亚语 (bg)
- 验证集:2,490 个样本,1,713,161 字节
- 测试集:5,010 个样本,3,476,792 字节
- 下载大小:1,695,351 字节
- 数据集总大小:5,189,953 字节
孟加拉语 (bn)
- 验证集:2,490 个样本,2,116,077 字节
- 测试集:5,010 个样本,4,281,043 字节
- 下载大小:1,740,855 字节
- 数据集总大小:6,397,120 字节
英语 (en)
- 验证集:2,490 个样本,1,363,685 字节
- 测试集:5,010 个样本,2,755,930 字节
- 下载大小:1,408,825 字节
- 数据集总大小:4,119,615 字节
西班牙语 (es)
- 验证集:2,490 个样本,1,440,816 字节
- 测试集:5,010 个样本,2,924,044 字节
- 下载大小:1,515,313 字节
- 数据集总大小:4,364,860 字节
印地语 (hi)
- 验证集:2,490 个样本,2,086,995 字节
- 测试集:5,010 个样本,4,216,475 字节
- 下载大小:1,821,008 字节
- 数据集总大小:6,303,470 字节
俄语 (ru)
- 验证集:2,490 个样本,1,864,852 字节
- 测试集:5,010 个样本,3,803,982 字节
- 下载大小:1,883,914 字节
- 数据集总大小:5,668,834 字节
文件结构
每个语言配置的数据文件按以下路径组织:
{语言代码}/validation-*{语言代码}/test-*
搜集汇总
数据集介绍
构建方式
在跨语言自然语言推理领域,xnli_eval_multirepr数据集的构建体现了对多语言语义关系的深度探索。该数据集以XNLI框架为基础,通过专业翻译和语言处理技术,将英语前提与假设对精准转化为保加利亚语、孟加拉语、西班牙语、印地语及俄语等多种语言版本。每个语言配置均包含验证集与测试集,样本规模统一为2490与5010例,确保了跨语言评估的均衡性。数据构建过程中,不仅保留了原始文本,还额外生成了罗马化转写与去除特殊符号的国际音标表示,为语言表征研究提供了丰富的多模态数据层次。
特点
该数据集的核心特征在于其多层次的语言表征体系,为自然语言推理任务赋予了跨语言比较的独特维度。除了包含原始语言文本的前提与假设对外,每个样本还配备了罗马化转写版本与国际音标剥离形式,这种多表征结构能够支持从字形到语音的多角度语言分析。数据集覆盖六种语言,涵盖印欧、斯拉夫、南亚等语系,语言多样性显著。标签体系遵循经典的蕴含、中立与矛盾三类分类,确保了任务定义的一致性。数据分割清晰,验证集与测试集规模稳定,为模型评估提供了可靠基准。
使用方法
在跨语言自然语言理解研究中,xnli_eval_multirepr数据集可作为评估多语言模型语义推理能力的标准工具。研究者可通过HuggingFace数据集库直接加载特定语言配置,如'bg'或'hi',便捷访问对应的验证与测试分割。每个样本的多重表征允许实验设计灵活选择输入形式,既可基于原始文本进行语义匹配分析,也能利用罗马化或音标化数据探究拼写或语音特征对推理的影响。该数据集适用于零样本跨语言迁移、多语言联合训练等前沿课题,其结构化标注为准确计算分类指标提供了便利,助力推动语言通用人工智能的发展。
背景与挑战
背景概述
xnli_eval_multirepr数据集作为跨语言自然语言推理领域的重要评估资源,其构建源于对多语言语义理解模型泛化能力的迫切需求。该数据集由研究团队在跨语言表示学习框架下开发,旨在通过涵盖保加利亚语、孟加拉语、英语、西班牙语、印地语及俄语等多种语言,系统评估模型在不同语言间的推理一致性。其核心研究问题聚焦于探索语言无关的语义表示能否在多样语言环境中保持稳定的推理性能,从而推动多语言自然语言处理技术的发展,并为跨语言迁移学习提供标准化评估基准。
当前挑战
该数据集致力于解决跨语言自然语言推理任务中的核心挑战,即模型在低资源语言上的语义对齐与泛化能力不足问题。构建过程中,研究人员面临多语言数据对齐的复杂性,需确保不同语言版本的句子在语义上严格等价;同时,为每种语言提供罗马化及国际音标剥离表示,增加了数据标注的精度要求与处理难度。这些挑战共同凸显了在多语言环境下构建高质量评估数据的艰巨性。
常用场景
经典使用场景
在自然语言处理领域,跨语言自然语言推理任务对模型的多语言理解能力提出了严峻挑战。xnli_eval_multirepr数据集通过提供保加利亚语、孟加拉语、英语、西班牙语、印地语和俄语等多种语言的文本对,成为评估模型跨语言语义推理性能的经典基准。该数据集不仅包含原始文本,还提供了罗马化及国际音标剥离版本,使得研究者能够深入探究不同文本表示形式对推理任务的影响,从而系统检验模型在多样化语言环境下的泛化能力。
实际应用
在实际应用层面,xnli_eval_multirepr数据集为构建全球化智能系统提供了关键支持。多语言客户服务机器人需要准确理解不同语言用户的查询意图,该数据集的推理任务可直接用于训练对话系统的语义匹配模块。机器翻译质量评估中,通过检测原文与译文间的逻辑一致性,能够自动识别翻译错误。此外,在跨语言信息检索领域,该数据集有助于优化检索模型对多语言查询与文档的语义关联判断,提升搜索引擎的国际化服务水平。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在多语言预训练模型的创新与评估方面。研究者基于其构建了XLM-R、mBERT等模型的跨语言性能基准测试框架,推动了如InfoXLM、Unicoder等新一代跨语言表示学习方法的诞生。在数据增强领域,该数据集的多种文本表示形式启发了罗马化与音标转换的数据增强策略研究。同时,其任务形式也被拓展到零样本跨语言迁移学习场景,催生了如Cross-lingual Transfer Learning for NLI等一系列重要研究成果。
以上内容由遇见数据集搜集并总结生成


