emily49/hateful-memes
收藏Hugging Face2023-06-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/emily49/hateful-memes
下载链接
链接失效反馈官方服务:
资源简介:
Hateful Memes Challenge是由Facebook AI创建的一个数据集和基准,旨在推动和衡量多模态推理和理解的进展。该任务专注于检测多模态模因中的仇恨言论。数据集包含PNG图像和JSONL格式的训练集、开发集和测试集。每个JSONL文件中的每一行都包含一个JSON编码的示例,其中包括模因中的文本、图像路径和标签(0=非仇恨,1=仇恨)。使用AUROC作为评估指标,也可以报告准确率。数据集标签可能存在误分类,但开发集和测试集中的误分类应非常罕见。数据集许可证信息在`LICENSE.txt`文件中。
Hateful Memes Challenge是由Facebook AI创建的一个数据集和基准,旨在推动和衡量多模态推理和理解的进展。该任务专注于检测多模态模因中的仇恨言论。数据集包含PNG图像和JSONL格式的训练集、开发集和测试集。每个JSONL文件中的每一行都包含一个JSON编码的示例,其中包括模因中的文本、图像路径和标签(0=非仇恨,1=仇恨)。使用AUROC作为评估指标,也可以报告准确率。数据集标签可能存在误分类,但开发集和测试集中的误分类应非常罕见。数据集许可证信息在`LICENSE.txt`文件中。
提供机构:
emily49
原始信息汇总
数据集概述
数据集名称
The Hateful Memes Challenge
创建机构
Facebook AI
数据集目的
用于推动和衡量多模态推理和理解方面的进展,特别是检测多模态表情包中的仇恨言论。
数据集结构
- img/: 包含PNG格式的图像文件。
- train.jsonl: 训练集。
- dev.jsonl: 开发集。
- test.jsonl: “已见”测试集。
- 未来将发布:“未见”测试集,将在NeurIPS 2020竞赛中发布。
数据格式
- .jsonl 文件格式,每行包含一个JSON编码的示例,包含以下字段:
text: 表情包中的文本。img: 图像文件的路径。label: 表情包的标签(0=非仇恨,1=仇恨),仅在训练集和开发集中提供。
评估指标
- AUROC(曲线下面积)为主要评估指标。
- 准确率 也可作为辅助报告指标。
注释准确性
- 训练集中可能存在少量误分类。
- 开发集和“已见”测试集中的误分类应非常罕见。
许可证
数据集遵循LICENSE.txt文件中规定的条款。
图像归属
- 如需在论文中展示示例表情包,请提供归属声明:Image is a compilation of assets, including ©Getty Image.
引用信息
@inproceedings{Kiela2020TheHM, title={The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes}, author={Douwe Kiela and Hamed Firooz and Aravind Mohan and Vedanuj Goswami and Amanpreet Singh and Pratik Ringshia and Davide Testuggine}, year={2020} }
联系方式
- 如有疑问或评论,请联系hatefulmemeschallenge@fb.com。
搜集汇总
数据集介绍
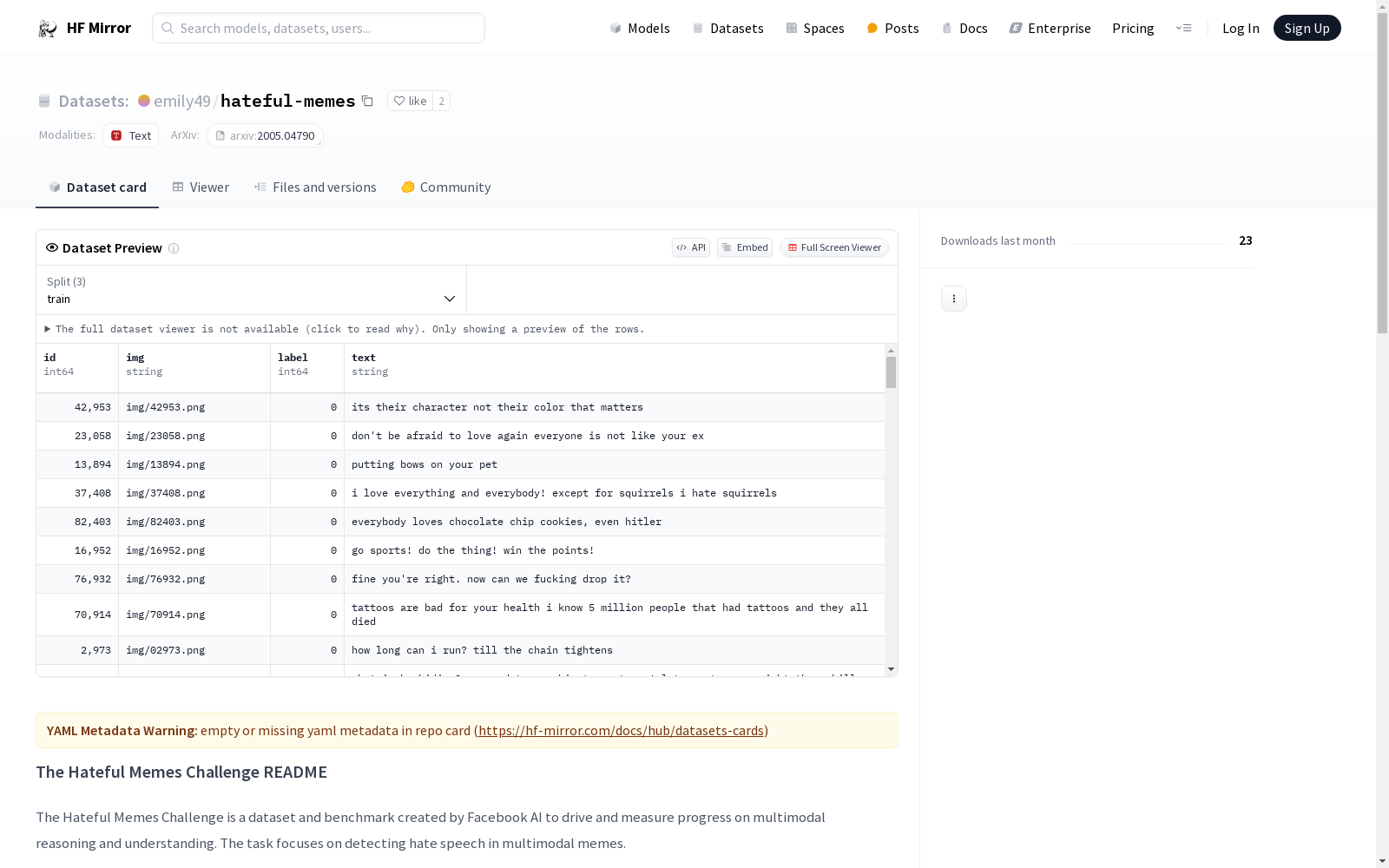
构建方式
该数据集由Facebook AI精心构建,旨在推动多模态推理与理解的研究进展。其核心任务是检测多模态模因中的仇恨言论。数据集包括一系列PNG格式的图像文件,以及分别用于训练、开发和测试的JSONL格式文件。每个JSONL文件包含一个JSON编码的示例,其中包括模因中的文本、图像路径以及标签(0表示非仇恨,1表示仇恨)。此外,数据集还计划在NeurIPS 2020竞赛中发布一个额外的‘未见’测试集。
特点
该数据集的显著特点在于其多模态性质,结合了图像和文本信息,为研究者提供了一个复杂且现实的挑战。此外,数据集的标签并非完全无误,反映了真实世界中注释的不确定性。这种设计使得数据集不仅适用于算法开发,还为研究注释一致性和模型鲁棒性提供了宝贵资源。
使用方法
使用该数据集时,研究者应首先加载图像和对应的JSONL文件,提取文本和图像路径,并根据标签进行分类任务。推荐使用AUROC作为主要评估指标,同时也可报告准确率以增强结果的可解释性。建议使用sklearn.metrics中的roc_auc_score和accuracy_score方法进行评估。此外,若在论文中展示示例模因,需遵循提供的图像归属信息。
背景与挑战
背景概述
在多模态理解和推理领域,Facebook AI于2020年推出了Hateful Memes Challenge数据集,旨在推动和衡量在多模态内容中检测仇恨言论的进展。该数据集由Douwe Kiela、Hamed Firooz等研究人员主导,核心研究问题聚焦于识别和分类包含仇恨言论的多模态表情包。这一数据集的创建不仅为学术界提供了一个标准化的评估平台,还对社交媒体内容监管和人工智能伦理研究产生了深远影响。
当前挑战
Hateful Memes Challenge数据集在构建过程中面临多重挑战。首先,多模态内容的复杂性要求模型能够同时处理图像和文本信息,这增加了模型的设计和训练难度。其次,数据集的标注准确性问题,尽管在开发和已见测试集中错误分类较为罕见,但在大规模数据集的标注过程中,仍可能存在误分类现象。此外,数据集的发布和使用需遵循严格的伦理和法律规范,确保不侵犯用户隐私和版权。
常用场景
经典使用场景
在多模态推理与理解领域,emily49/hateful-memes数据集的经典使用场景主要集中在检测多模态模因中的仇恨言论。通过结合图像和文本信息,研究人员能够开发和评估模型,以识别和分类含有仇恨内容的模因。这种多模态分析不仅提升了模型的准确性,还为跨模态情感分析提供了新的视角。
衍生相关工作
基于emily49/hateful-memes数据集,衍生了一系列相关的经典工作,包括多模态学习模型的改进和跨模态情感分析的新方法。例如,一些研究通过结合深度学习和自然语言处理技术,提升了仇恨言论检测的准确性。此外,该数据集还激发了对多模态数据标注和注释方法的研究,推动了数据集构建和评估标准的进一步发展。
数据集最近研究
最新研究方向
在多模态内容分析领域,emily49/hateful-memes数据集的最新研究方向主要集中在提升多模态推理和理解能力,以更准确地检测和识别网络中的仇恨言论。该数据集由Facebook AI创建,旨在通过结合图像和文本信息,推动机器学习模型在处理复杂社交媒体内容方面的进步。研究者们正致力于开发更高效的算法,以应对多模态数据中的挑战,如模态间的信息融合和上下文理解。此外,随着社交媒体中仇恨言论的日益增多,该数据集的研究成果对于维护网络环境的和谐与安全具有重要意义。
以上内容由遇见数据集搜集并总结生成


