rw_roman-empire_nbw_1_mask_public
收藏Hugging Face2025-05-05 更新2025-05-06 收录
下载链接:
https://huggingface.co/datasets/Yuyeong/rw_roman-empire_nbw_1_mask_public
下载链接
链接失效反馈官方服务:
资源简介:
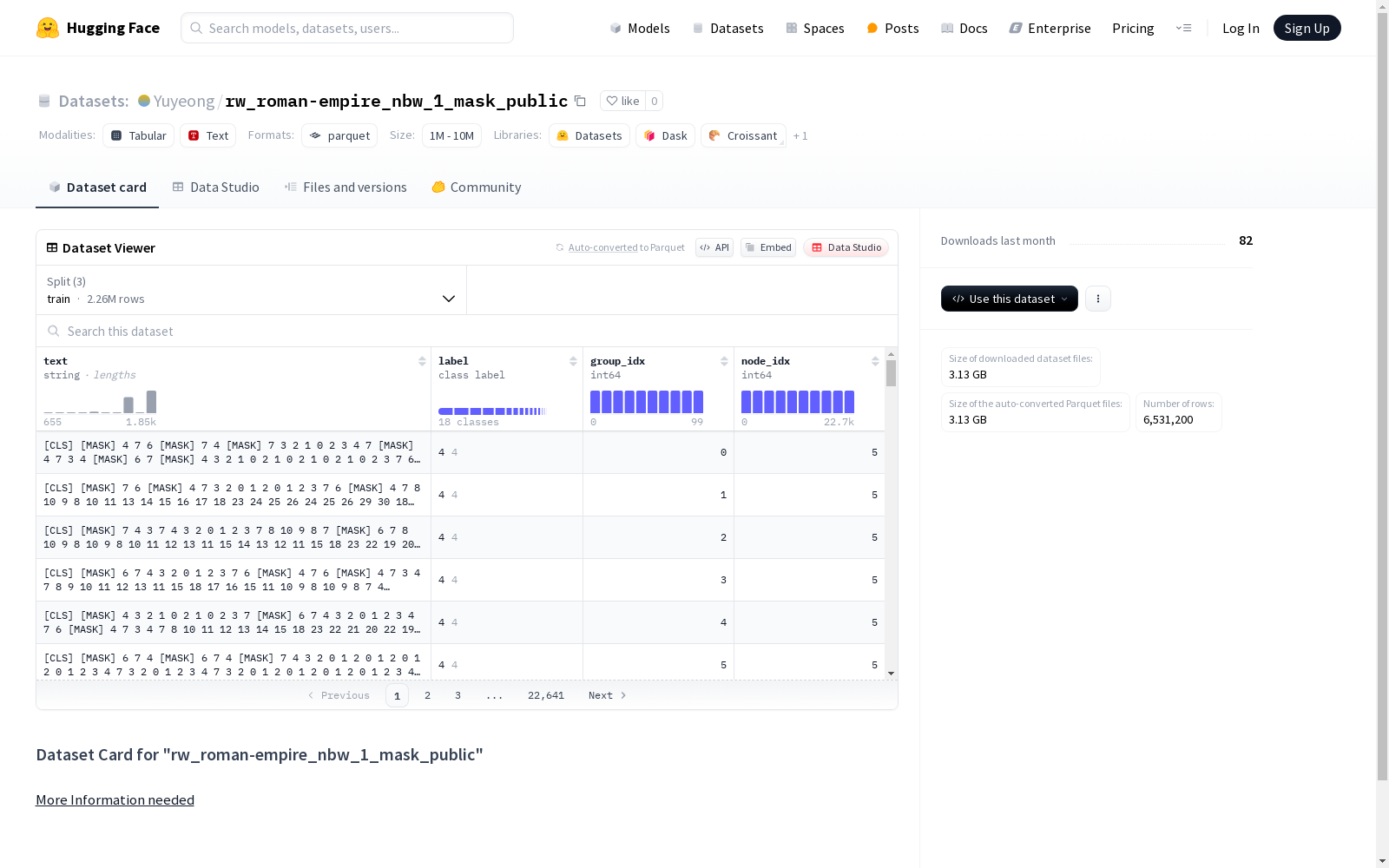
该数据集包含文本(text)和标签(label)信息,文本字段是字符串类型,标签字段有15个类别,用数字0到14表示。此外还有两个整数字段group_idx和node_idx。数据集分为训练集、验证集和测试集,分别包含2264100、2134900和2132200条数据。数据集的下载大小为3.13GB,总大小为10.03GB。
创建时间:
2025-05-05
原始信息汇总
数据集概述
基本信息
- 数据集名称: rw_roman-empire_nbw_1_mask_public
- 下载大小: 3,133,469,321 字节
- 数据集大小: 11,026,372,101.5169 字节
数据集特征
- text: 字符串类型
- label: 类别标签,包含18个类别(0到17)
- group_idx: int64类型
- node_idx: int64类型
数据划分
- 训练集 (train):
- 样本数量: 2,264,100
- 大小: 3,822,392,374.302489 字节
- 验证集 (validation):
- 样本数量: 2,134,900
- 大小: 3,604,269,016.34132 字节
- 测试集 (test):
- 样本数量: 2,132,200
- 大小: 3,599,710,710.8730917 字节
搜集汇总
数据集介绍
构建方式
该数据集聚焦于古罗马帝国历史研究领域,采用结构化数据构建方法,包含226万训练样本、213万验证样本及213万测试样本。数据以文本形式存储,并标注了18种分类标签,同时附带组别索引和节点索引两个关键维度,通过多维度标注体系实现历史文本的细粒度分类。数据规模达11GB,采用标准化的训练-验证-测试划分策略,确保模型评估的科学性。
特点
作为历史学研究领域的重要语料库,该数据集最显著的特点是具备18类精细标注体系,涵盖古罗马帝国研究的多个主题维度。数据以文本为主体,配合分类标签和双重索引机制,既保留原始文本信息又提供结构化检索可能。其百万级样本规模在历史文本数据集中属于较大体量,且训练集与验证测试集保持均衡分布,有利于模型训练的稳定性。
使用方法
研究者可利用该数据集进行古罗马历史文本的多分类任务研究,通过加载标准化的训练-验证-测试分割直接开展机器学习实验。文本字段适用于自然语言处理任务,18类标签支持细粒度分类模型训练,而组别和节点索引则为跨文档关系研究提供可能。建议结合预训练语言模型进行微调,充分发挥大规模历史语料的价值。
背景与挑战
背景概述
rw_roman-empire_nbw_1_mask_public数据集是一个专注于古罗马帝国历史研究的标注数据集,其构建旨在为历史文献分析与文本分类任务提供结构化支持。该数据集由专业研究团队开发,涵盖了丰富的文本内容与多类别标签体系,反映了古罗马帝国时期的社会、政治与文化特征。通过大规模文本标注与节点索引设计,该数据集为历史文本挖掘、语义分析及网络关系研究提供了重要基础。其多标签分类框架尤其适用于复杂历史语境下的文本语义解析,对数字人文领域的研究具有显著推动作用。
当前挑战
该数据集面临的挑战主要体现在两方面:领域问题的复杂性使得古罗马历史文本的语义标注需要高度专业化的知识体系,而多标签分类任务中类别间的语义重叠现象增加了模型训练的难度;数据构建过程中,原始文献的碎片化与异构性导致文本清洗与标准化工作异常繁重,同时节点索引与分组逻辑的设计需平衡历史准确性与计算可行性。大规模标注数据的质量控制与专家校验机制亦是构建过程中的关键瓶颈。
常用场景
经典使用场景
在历史文献数字化分析领域,rw_roman-empire_nbw_1_mask_public数据集以其精细标注的文本数据,为研究者提供了探索古罗马帝国时期社会结构和文化传播的独特窗口。该数据集通过多维标签体系,支持对历史文本的语义分类、主题建模和网络关系分析,成为数字人文研究中不可或缺的基准数据。
衍生相关工作
基于该数据集衍生的经典研究包括《基于图神经网络的古罗马行政文书分析》,该工作创新性地将节点分类技术应用于历史文献网络。另有学者开发了跨时代的文本风格迁移模型,通过对比分析不同时期文本特征,揭示了罗马帝国文化传播的演变规律。
数据集最近研究
最新研究方向
在古罗马帝国历史文本分析领域,rw_roman-empire_nbw_1_mask_public数据集以其多标签分类结构和丰富的节点索引特征,为数字人文研究提供了新的可能性。该数据集近期被广泛应用于基于图神经网络的古代文献关联挖掘,研究者通过文本内容与节点拓扑关系的联合建模,成功揭示了帝国时期行政文书之间的潜在传播路径。随着大语言模型在历史语义理解上的突破性进展,该数据集正成为训练时序感知型Transformer架构的重要基准,特别是在处理跨世纪文本风格演变与官僚体系术语变迁等复杂任务时展现出独特价值。
以上内容由遇见数据集搜集并总结生成


