synthetic-ocr-images-korean
收藏Hugging Face2025-11-05 更新2025-11-06 收录
下载链接:
https://huggingface.co/datasets/junyeong-nero/synthetic-ocr-images-korean
下载链接
链接失效反馈官方服务:
资源简介:
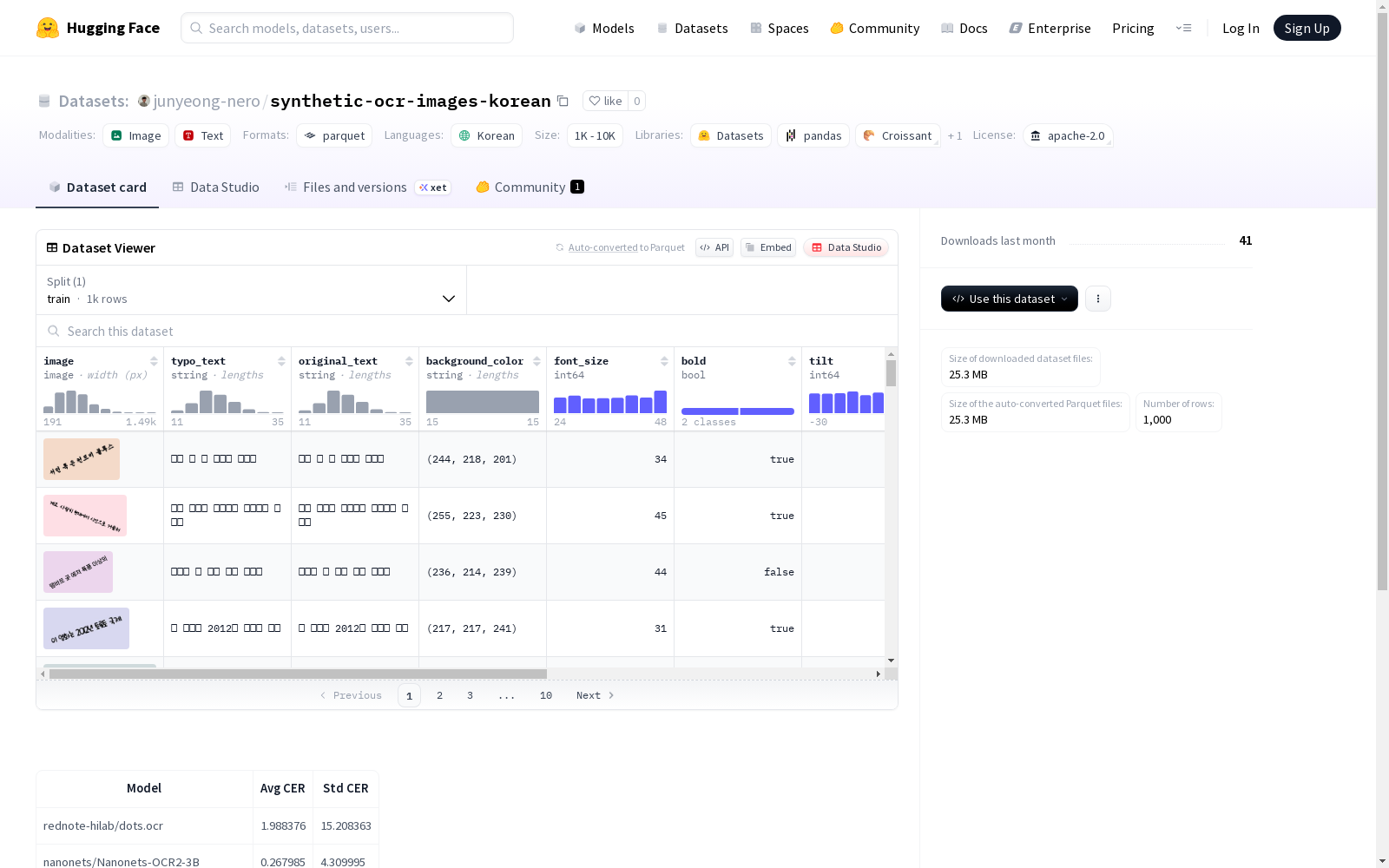
该数据集包含图片和文本信息,文本分为错误文本(typo_text)和原始文本(original_text)。图片可能具有不同的背景颜色、字体大小、是否加粗、倾斜角度、是否有阴影、是否扭曲、是否模糊和对比度等属性。数据集被划分为训练集,共有1000个示例。
创建时间:
2025-11-04
原始信息汇总
数据集概述
基本信息
- 数据集名称: synthetic-ocr-images-korean
- 存储位置: https://huggingface.co/datasets/junyeong-nero/synthetic-ocr-images-korean
- 数据量: 1,000个样本
- 数据集大小: 25,342,173字节
- 下载大小: 25,290,435字节
数据结构
特征字段
- image: 图像数据
- typo_text: 字符串类型,包含拼写错误的文本
- original_text: 字符串类型,原始正确文本
- background_color: 字符串类型,背景颜色信息
- font_size: 整型,字体大小
- bold: 布尔型,是否加粗
- tilt: 整型,倾斜角度
- shadow: 布尔型,是否包含阴影效果
- distortion: 布尔型,是否包含扭曲效果
- blur: 布尔型,是否包含模糊效果
- contrast: 布尔型,是否包含对比度调整
数据划分
- 训练集: 1,000个样本,占用25,342,173字节
配置信息
- 默认配置: default
- 数据文件路径: data/train-*
搜集汇总
数据集介绍
构建方式
在光学字符识别技术蓬勃发展的背景下,synthetic-ocr-images-korean数据集通过程序化生成方法构建。该过程基于原始韩语文本,系统性地引入拼写变异生成typo_text字段,同时采用参数化渲染引擎合成图像样本。生成过程中精确控制了字体尺寸、倾斜角度、阴影效果等视觉参数,并模拟了模糊、畸变等真实场景干扰因素,最终形成包含千个样本的标准化训练集。
特点
该数据集最显著的特点是具备双重文本标注体系,同时提供原始文本与带有拼写错误的变体文本,为OCR错误修正研究提供直接对照。图像特征维度丰富,涵盖字体样式、色彩空间、几何变换等十余种结构化属性,且每个样本均附带完整的渲染参数元数据。其价值在于通过可控的合成环境构建了具有明确误差标注的韩语OCR基准,不同模型的性能对比表格进一步凸显了数据集的评估有效性。
使用方法
研究人员可将其作为韩语OCR模型训练的优质数据源,特别适用于字符识别鲁棒性研究和拼写纠错算法开发。使用时应充分利用其结构化元数据,通过背景色、字体大小等字段构建数据子集进行针对性训练。评估阶段可参照提供的基准模型对比表,采用字符错误率作为核心指标,同时注意结合标准差分析模型稳定性,最终推动韩语OCR技术向更高精度发展。
背景与挑战
背景概述
韩文合成OCR图像数据集诞生于光学字符识别技术对多语言文本处理需求日益增长的背景下,由研究团队基于Apache 2.0协议构建并于近期发布。该数据集聚焦韩文场景文本识别领域,通过合成算法生成包含原始文本与人为引入拼写变体的图像样本,同时标注字体样式、背景色彩及多种图像扰动参数。其核心价值在于为韩文OCR模型开发提供标准化测试基准,推动多语言文档数字化技术在东亚文字处理领域的应用深化。
当前挑战
该数据集需应对韩文字符结构复杂性与合成图像真实性的双重挑战:韩文字母组合形成的方块字形存在大量形近字符,导致传统OCR模型易产生字符分割错误;合成过程中需平衡字体渲染、倾斜阴影等视觉干扰因素与自然文本分布的契合度。构建阶段面临标注一致性难题,包括拼写变体的语言学合理性验证,以及图像扭曲、模糊等退化效果与真实扫描文档的视觉对齐,这些因素共同影响着模型在现实场景中的泛化能力。
常用场景
经典使用场景
在光学字符识别技术领域,synthetic-ocr-images-korean数据集为韩文文本识别模型的训练与评估提供了标准化基准。该数据集通过合成图像模拟真实场景中的字体变形、倾斜和背景干扰等因素,使研究者能够系统性地测试模型在复杂条件下的字符识别准确率。其包含的原始文本与错误文本对照结构,为误差分析和模型优化提供了关键数据支撑。
衍生相关工作
基于该数据集衍生的经典工作包括NCSOFT开发的VARCO-VISION模型系列,其在保持较低标准差的同时实现了优异的字符识别精度。AllenAI团队的olmOCR模型通过该数据集的训练,在韩文复杂字体识别领域取得突破性进展。这些衍生模型共同推动了多语言OCR技术体系的完善,为后续研究奠定了重要基础。
数据集最近研究
最新研究方向
在韩文光学字符识别领域,synthetic-ocr-images-korean数据集正推动着对抗性文本生成与鲁棒性模型的前沿探索。该数据集通过模拟真实场景中的字体变形、倾斜和模糊等干扰因素,为多语言OCR系统的泛化能力提供了关键训练资源。当前研究热点集中于利用生成式人工智能技术,如基于Transformer的视觉语言模型,来提升对复杂背景和噪声干扰下韩文字符的识别精度。业界领先的模型如allenai/olmOCR-2-7B-1025和Qwen/Qwen3-VL-2B-Instruct已在该数据集上展现出卓越性能,其低字符错误率指标预示着跨语言OCR技术正迈向新的发展阶段。这些进展不仅促进了智能文档处理系统的革新,更为数字人文研究中的古籍数字化工程提供了技术支撑。
以上内容由遇见数据集搜集并总结生成


