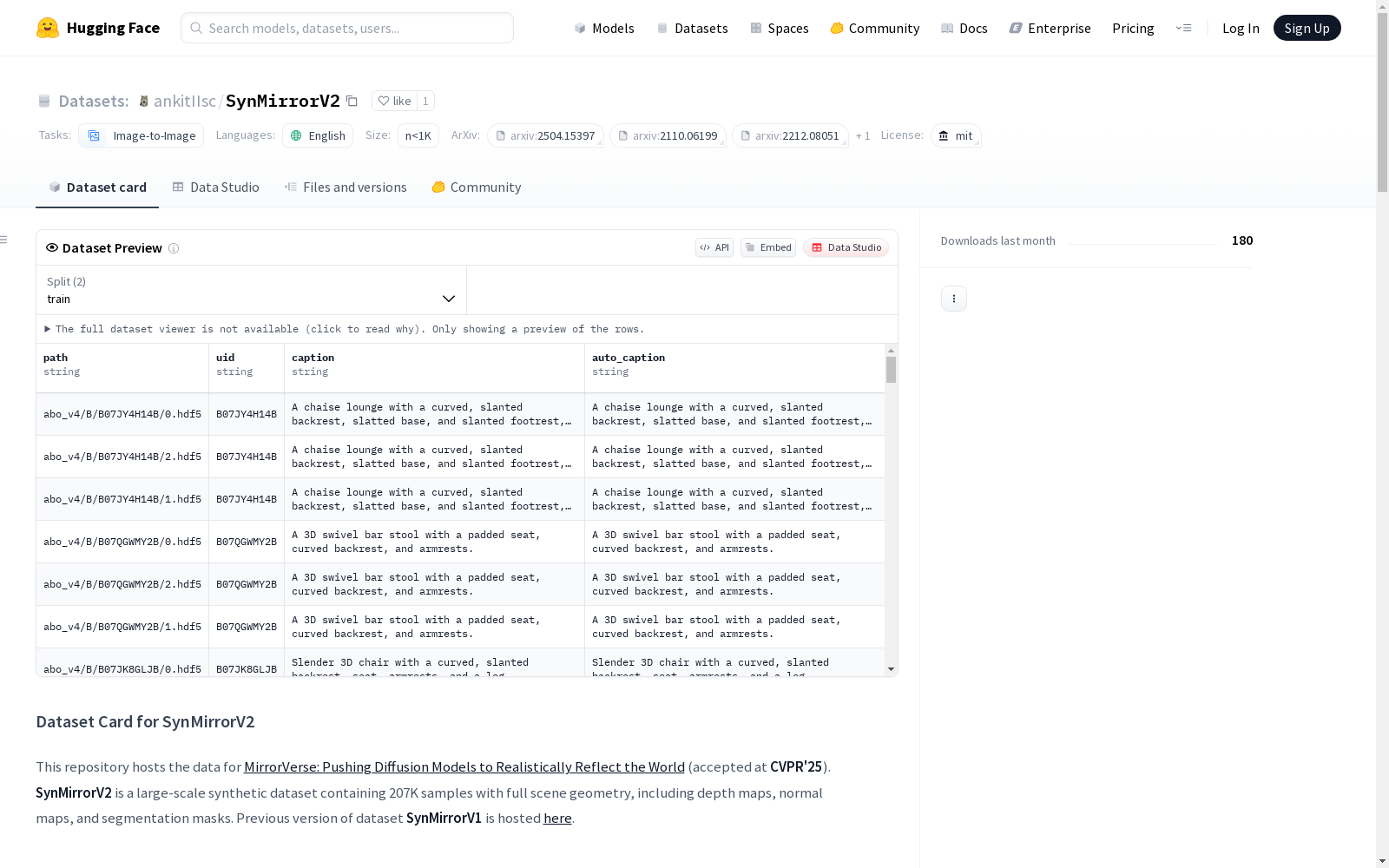
SynMirrorV2
收藏SynMirrorV2 数据集概述
数据集基本信息
- 许可证: MIT
- 任务类别: 图像到图像
- 语言: 英语
- 规模: 小于1K
数据集描述
SynMirrorV2 是一个大规模合成数据集,包含207K样本,具有完整的场景几何信息,包括深度图、法线图和分割掩码。该数据集是论文《MirrorVerse: Pushing Diffusion Models to Realistically Reflect the World》(CVPR25)的数据支持。
数据集特点
- 增强特性: 包括对象接地、旋转和场景中多对象支持。
- 数据来源: 使用来自Objaverse和Amazon Berkeley Objects (ABO)的3D资产。
- 渲染工具: 使用BlenderProc渲染每个3D对象及其对应的深度图、法线图和分割掩码。
- 视图生成: 每个对象生成三个随机视图,并应用不同的增强。
数据集来源
- GitHub仓库: https://github.com/val-iisc/MirrorVerse
- 论文: https://openaccess.thecvf.com/content/CVPR2025/papers/Dhiman_MirrorVerse_Pushing_Diffusion_Models_to_Realistically_Reflect_the_World_CVPR_2025_paper.pdf
- arXiv论文: https://arxiv.org/abs/2504.15397
- 项目页面: https://mirror-verse.github.io/
数据集结构
数据集以tar文件形式存储,每个文件包含约2000个对象的3个渲染。解压后的目录结构如下:
hf-objaverse-v4/ 000-010/ 8014aa16057a495795f7bf8a02a3ebe0/ 0.hdf5 1.hdf5 2.hdf5 ... abo_v4/ 4/ B0727Q5F94/ 0.hdf5 1.hdf5 2.hdf5 ... abo_v4_multiple/ 0/ B00BBDF500_B07BMTN6GF/ 0.hdf5 1.hdf5 2.hdf5 ...
主要文件说明
| 文件名/文件夹 | 描述 |
|---|---|
| abo_v4/ | 包含来自ABO数据集的渲染。 |
| abo_v4_multiple/ | 包含来自ABO数据集的多对象渲染。 |
| hf-objaverse-v4/ | 包含来自Objaverse数据集的渲染。 |
| abo_split_all.csv | 包含ABO数据集的UID、hdf5文件路径和自动生成的标题。 |
| objaverse_split_all.csv | 包含Objaverse数据集的UID、hdf5文件路径和自动生成的标题。 |
| train_abo.csv | 包含用于训练的ABO数据集UID。 |
| test_abo.csv | 包含用于测试的ABO数据集UID。 |
| train_objaverse.csv | 包含用于训练的Objaverse数据集UID。 |
| test_objaverse.csv | 包含用于测试的Objaverse数据集UID。 |
| train.csv/test.csv | 包含训练和测试的UID组合,测试集包含is_novel列。 |
| 0.hdf5 | 包含单个对象的渲染数据,包括颜色、深度、法线图等。 |
数据提取代码示例
python import h5py import json import numpy as np
def extract_data_from_hdf5(hdf5_path: str): hdf5_data = h5py.File(hdf5_path, "r") data = { "image": np.array(hdf5_data["colors"], dtype=np.uint8), "mask": (np.array(hdf5_data["category_id_segmaps"], dtype=np.uint8) == 1).astype(np.uint8) * 255, "object_mask": (np.array(hdf5_data["category_id_segmaps"], dtype=np.uint8) == 2).astype(np.uint8) * 255, "depth": np.array(hdf5_data["depth"]), "normals": np.array(hdf5_data["normals"]), "cam_states": np.array(hdf5_data["cam_states"]), } return data
def decode_cam_states(cam_states): array = np.array(cam_states) json_str = array.tobytes().decode("utf-8") data = json.loads(json_str) cam2world = data["cam2world"] cam_K = data["cam_K"] return cam2world, cam_K
引用
bibtex @inproceedings{dhiman2025mirrorverse, title={MirrorVerse: Pushing Diffusion Models to Realistically Reflect the World}, author={Dhiman, Ankit and Shah, Manan and Babu, R Venkatesh}, booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference}, pages={11239--11249}, year={2025} }
数据集联系人