shiv213/Automatic-Sarcasm-Detection-Twitter
收藏Hugging Face2024-05-06 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/shiv213/Automatic-Sarcasm-Detection-Twitter
下载链接
链接失效反馈官方服务:
资源简介:
该数据集用于自动讽刺检测任务,包含来自Twitter和Reddit的训练和测试数据,格式为jsonlines。每个数据项包括标签(讽刺或非讽刺)、样本ID(仅在测试数据中)、讽刺响应及其对话上下文。上下文是一个有序的对话列表,帮助理解讽刺响应的背景。数据集的大小统计显示,Reddit的训练和测试样本分别为4400和1800,Twitter的训练和测试样本分别为5000和1800。数据集主要来源于社交媒体平台,可能包含争议性和非正式语言。
This dataset is intended for the automatic sarcasm detection task. It comprises training and test datasets sourced from Twitter and Reddit, formatted as jsonlines. Each data entry includes a label (sarcastic or non-sarcastic), a sample ID (only present in the test datasets), the sarcastic response, and its conversational context. The context is an ordered list of dialogues that helps clarify the background of the sarcastic response. Statistical data of the dataset shows that Reddit has 4400 training samples and 1800 test samples, while Twitter has 5000 training samples and 1800 test samples. The dataset is primarily sourced from social media platforms and may contain controversial and informal language.
提供机构:
shiv213
原始信息汇总
数据集概述
数据集名称
Automatic Sarcasm Detection
数据集内容
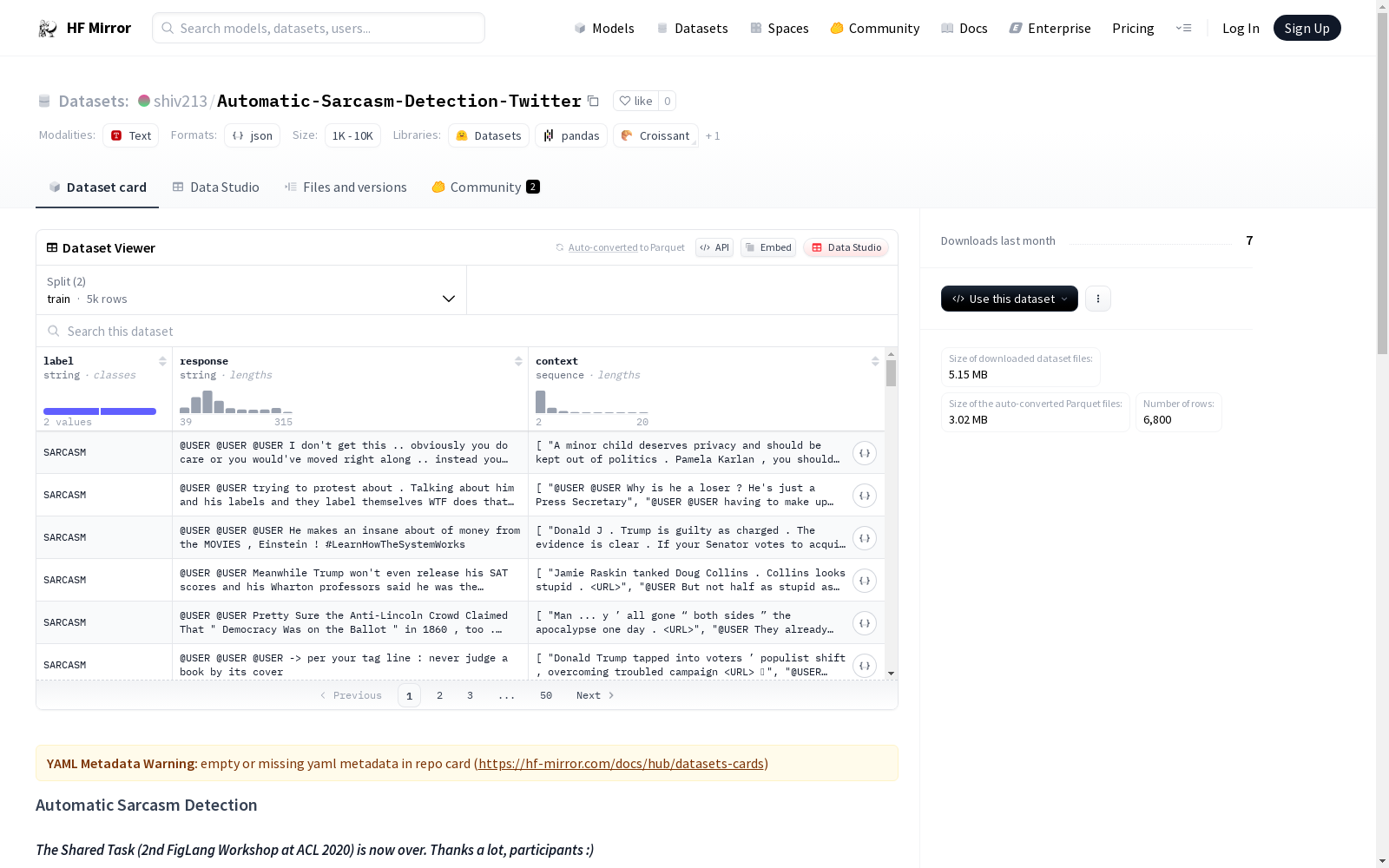
- 数据格式:JSON Lines
- 数据结构:
- label:标签,值为
SARCASM或NOT_SARCASM - id:样本的唯一标识符,仅在测试数据中提供
- response:讽刺性回复,可能为Twitter推文或Reddit帖子
- context:回复的对话上下文,为一个有序的对话列表
- label:标签,值为
数据集统计
| Train | Test | |
|---|---|---|
| 4400 | 1800 | |
| 5000 | 1800 |
数据集用途
用于讽刺检测任务,训练和测试数据分别提供。
数据集特点
- 训练数据来源于流行的社交媒体平台,包含大量关于争议性、政治和社会话题的内容。
- 数据经过预处理和轻度编辑,但仍包含用户的争议性观点和非正式语言。
搜集汇总
数据集介绍
构建方式
shiv213/Automatic-Sarcasm-Detection-Twitter数据集的构建采用了社交媒体平台Twitter和Reddit上的对话作为来源。数据集通过采集用户间的互动对话,包括一条回应和其对应的上下文对话,构建了用于训练和测试的样本集。每个样本为一个JSON对象,包含标签、样本标识、回应内容和上下文对话,以便于模型在理解对话上下文的基础上进行讽刺话语的识别。
使用方法
使用该数据集时,用户需根据提供的训练集和测试集进行模型训练和评估。数据集中的每个样本都包含必要的标签和上下文信息,用户可以基于这些信息设计模型以预测回应是否为讽刺。在提交测试结果时,用户需要按照指定的格式和链接提供预测标签,并确保使用样本标识符进行结果的对应。数据集的使用需遵循相应的提交指南,以保证评估的一致性和公正性。
背景与挑战
背景概述
在自然语言处理领域中,讽刺检测是一项具有挑战性的任务,旨在识别文本中的讽刺或嘲讽意味。shiv213/Automatic-Sarcasm-Detection-Twitter数据集是在2020年ACL会议的FigLang研讨会上的共享任务中创建的,由Debanjan Ghosh、Avijit Vajpyee和Smaranda Muresan等研究人员负责。该数据集的核心研究问题是自动检测Twitter平台上的讽刺言论,对于理解社交媒体中的隐含情感和语境具有重大意义,对情感分析、语境理解和语言模型等领域产生了深远影响。
当前挑战
数据集在构建过程中遇到的挑战包括讽刺语言的多样性和复杂性,以及语境信息的处理。具体而言,数据集解决的领域问题是讽刺检测,面临的挑战包括:1)讽刺表达的多样性使得模型难以捕捉其细微差别;2)语境信息的理解和利用对模型性能至关重要,但语境的动态性和多变性增加了检测的难度;3)构建过程中还需处理来自社交媒体的敏感和争议性内容,确保数据的多样性和代表性的同时,还需避免偏见和不当的语境解读。
常用场景
经典使用场景
在自然语言处理领域, Shiv213 的 Automatic Sarcasm Detection 数据集被广泛应用于讽刺话语的检测研究。其经典的使用场景在于训练机器学习模型以识别社交媒体平台如Twitter和Reddit上的讽刺性言论,通过对上下文和响应的深度分析,模型能够准确预测发言是否带有讽刺意味。
解决学术问题
该数据集解决了讽刺检测中的语境理解和情感分析两大难题,为学术研究提供了丰富的标注数据和基准,有助于推动自然语言处理技术的进步,特别是在情感分析和文本挖掘方面。
实际应用
在现实应用中,此数据集可用于社交媒体平台的内容审核,帮助识别和过滤带有讽刺性质的不当言论,从而维护网络环境的健康,同时也可用于公共舆论分析和市场情绪研究。
数据集最近研究
最新研究方向
在自然语言处理领域中,讽刺检测是近年来备受关注的课题。shiv213/Automatic-Sarcasm-Detection-Twitter数据集为此领域的研究提供了宝贵的资源。该数据集最新研究方向聚焦于利用深度学习模型对Twitter上的讽刺言论进行识别。近期研究探索了结合语境信息来提高检测准确率的方法,尤其是如何在保留对话上下文语义的同时,准确判别讽刺标签。此外,随着社交媒体上争议性话题的增多,如何处理带有政治和社会争议性的言论,确保模型公正无偏,也成为研究的热点。这些研究不仅推动了讽刺检测技术的发展,对于理解网络舆论生态也具有重要的社会意义。
以上内容由遇见数据集搜集并总结生成


