tblard/allocine
收藏Hugging Face2024-01-09 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/tblard/allocine
下载链接
链接失效反馈官方服务:
资源简介:
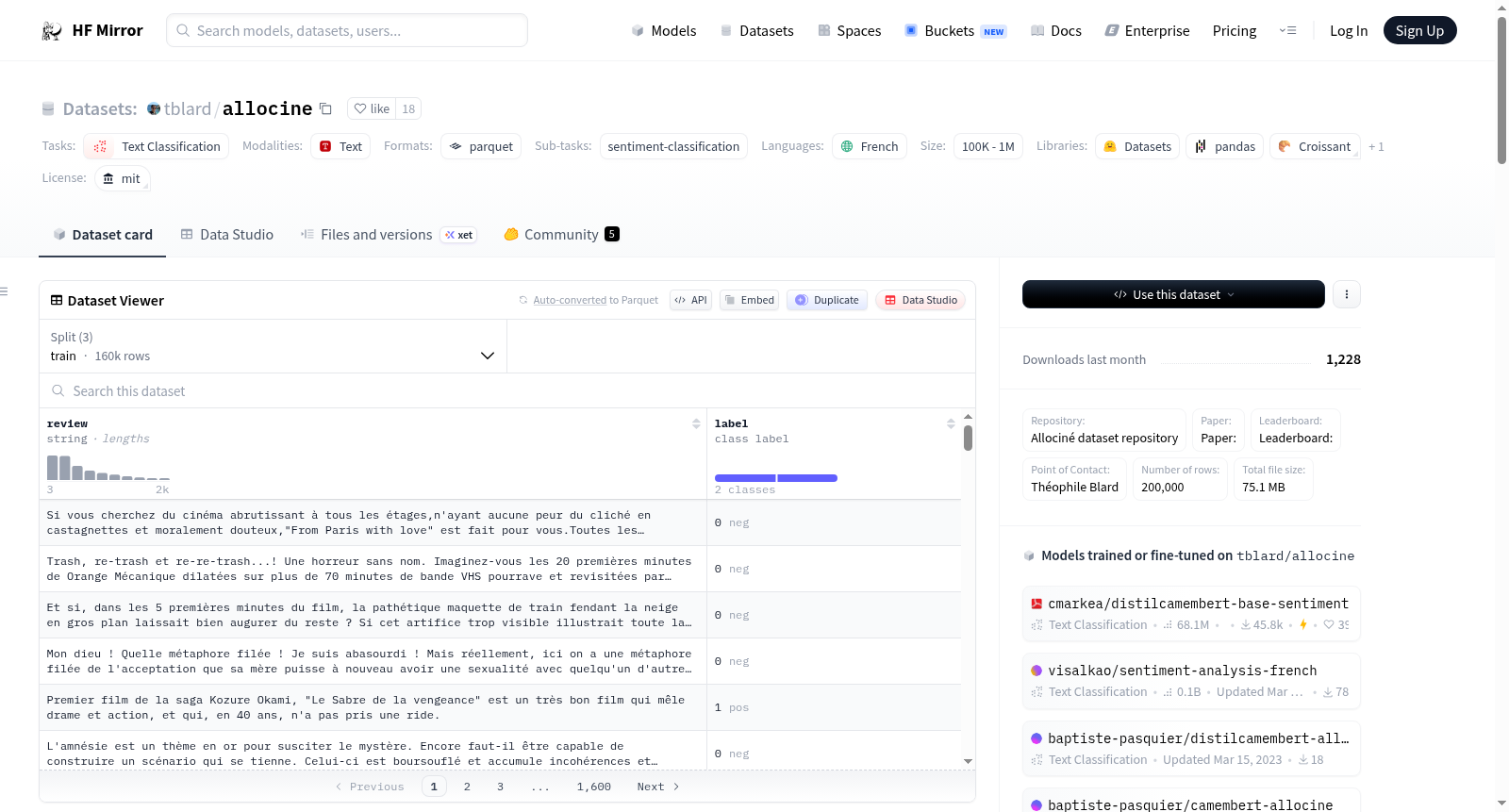
Allociné数据集是一个用于情感分析的法语数据集,包含2006年至2020年间由Allociné.fr社区成员撰写的电影评论。数据集包含100,000条正面评论和100,000条负面评论,分为训练集(160,000条)、验证集(20,000条)和测试集(20,000条)。数据集的主要任务是文本分类和情感分类,旨在训练模型进行情感分析。数据集的结构包括两个字段:review(评论文本)和label(标签,0表示负面,1表示正面)。数据集的创建是为了支持大规模的法语情感分析,并且与一个BERT模型一起发布。
提供机构:
tblard
原始信息汇总
数据集概述
名称: Allociné
语言: 法语 (fr)
许可证: MIT
多语言性: 单语种
大小: 100K<n<1M
源数据: 原始数据
任务类别: 文本分类
任务ID: 情感分类
数据集结构
-
特征:
- review: 字符串类型,包含评论文本。
- label: 分类标签,整数类型,0表示负面,1表示正面。
-
数据分割:
- 训练集: 160,000条记录,字节数91,330,632。
- 验证集: 20,000条记录,字节数11,546,242。
- 测试集: 20,000条记录,字节数11,547,689。
数据集创建
- 数据收集: 使用film page urls和allocine_scraper.py工具收集。
- 数据标注: 无额外标注。
- 数据来源: 来自Allociné.fr网站的在线社区。
使用数据注意事项
- 社会影响: 情感分类模型需具备高级语言理解能力,可能影响决策过程。
- 偏见讨论: 需进一步分析以确定内容审核的有效性。
- 其他限制: 未详细调查,但可能存在如否定、状语修饰和评论者语用等难以准确标记的语言现象。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,情感分析任务对于理解用户观点具有重要价值,尤其对于法语这类资源相对稀缺的语言而言。Allociné数据集正是为填补这一空白而构建的,它源自法国知名影评网站Allociné.fr,通过爬取2006年至2020年间社区用户撰写的电影评论而形成。数据收集过程中,研究者利用电影页面URL列表和专用爬虫工具,为每部电影最多采集30条评论。原始评论带有0.5至5.0的评分等级,其中评分≤2的评论被标记为负面,评分≥4的标记为正面,仅保留字符数少于2000的评论以确保文本质量。最终数据集包含10万条正面和10万条负面评论,被划分为训练集(16万条)、验证集(2万条)和测试集(2万条),且各分割中的电影互不重叠。
使用方法
研究人员可通过Hugging Face数据集库便捷地加载该数据集,使用`load_dataset('tblard/allocine')`命令即可获取包含训练、验证和测试三个分割的完整数据。每个分割中的`review`字段提供评论文本,`label`字段提供情感标签,可直接用于监督学习中的情感分类模型训练。数据集预定义了与文本分类任务对应的输入输出映射,将`review`映射为文本特征、`label`映射为目标变量,并支持准确率、F1分数、精确率和召回率等多种评估指标。用户可采用标准的机器学习流程,对评论文本进行预处理后输入分类模型,通过比较预测标签与真实标签来评估模型性能,从而推动法语情感分析技术的发展。
背景与挑战
背景概述
在自然语言处理领域,情感分析作为文本分类的核心任务之一,长期受到英语资源的显著倾斜,而法语等低资源语言的大规模标注数据集相对匮乏。为填补这一空白,Théophile Blard于2020年创建了Allociné数据集,该数据集源自法国知名影视评论平台Allociné.fr,汇聚了2006年至2020年间社区用户撰写的20万条电影评论,其中正面与负面样本各占10万条,并按照16万、2万、2万的规模划分为训练集、验证集和测试集。该数据集的核心研究问题在于推动法语情感分类模型的开发与评估,其发布后迅速成为法语NLP领域的重要基准,基于BERT的tf-allociné模型在其测试集上达到了97.44%的准确率,显著促进了法语情感分析技术的进步。
当前挑战
Allociné数据集所面临的挑战首先体现在领域问题的复杂性上:情感分类需应对法语中特有的否定结构、副词修饰语以及评论者语用学等语言现象,这些微妙表达极易导致模型误判。其次,数据构建过程中遭遇了多重困难:原始评论的评分体系为0.5至5.0的连续值,需通过阈值设定(≤2为负面,≥4为正面)进行二值化处理,这一规则可能丢失评分中间区域的细微情感差异;同时,为确保文本长度适宜,仅保留字符数少于2000的评论,导致部分长篇深度分析被排除;此外,数据爬取自公共网站,虽未收集用户名,但评论内容可能包含演员、剧组成员等敏感信息,且社区审核机制对违反服务条款内容的过滤效果尚待验证,这些因素共同构成了数据集在覆盖全面性与内容纯净性上的持续挑战。
常用场景
经典使用场景
Allociné数据集是法语情感分析领域的基石资源,其核心应用场景聚焦于电影评论的情感极性分类任务。该数据集包含20万条来自Allociné.fr社区的电影评论,每条评论均被标注为正面或负面情感,训练集、验证集和测试集的比例为8:1:1。研究者通常利用该数据集训练和评估基于深度学习的文本分类模型,如BERT、CamemBERT或FlauBERT等预训练语言模型,以捕捉法语语境下的情感表达模式。其平衡的类别分布和大规模样本量,使其成为法语情感分析基准测试的标准平台。
解决学术问题
该数据集有效解决了法语自然语言处理领域中大规模、高质量情感标注语料匮乏的学术困境。此前,情感分析研究多集中于英语资源,而法语因其形态复杂性和文化特异性,缺乏统一基准。Allociné通过标准化流程将评分映射为情感标签,为跨语言情感分析、迁移学习及多模态研究提供了关键参照。其衍生出的tf-allociné模型在测试集上达到97.44%的准确率,显著推动了法语情感分析技术的性能边界,并促进了低资源语言情感分析方法的理论探索。
实际应用
在实际应用中,Allociné数据集训练的情感分类模型可部署于电影推荐系统、用户反馈分析及社交媒体舆情监控等场景。例如,法国影视平台可借助该模型自动解析用户评论,量化观众对影片的喜好程度,从而优化内容推荐算法。此外,品牌方可通过分析产品评论的情感倾向,实时调整营销策略。该数据集还支持多领域迁移,如将电影评论的情感知识迁移至电子商务或新闻评论分析,展现了从娱乐产业到商业智能的广泛实用价值。
数据集最近研究
最新研究方向
在当前自然语言处理领域,法语情感分析的研究正随着多语言预训练模型的兴起而蓬勃发展。Allociné数据集作为法语影评情感分类的标杆资源,其20万条标注均衡的评论数据为跨语言模型迁移学习提供了关键验证平台。前沿研究聚焦于利用CamemBERT、FlauBERT等法语专用Transformer架构进行微调,探索电影评论中隐含的讽刺、对比等复杂情感表达。该数据集与BERT模型结合取得的97.44%准确率,不仅推动了法语情感分析技术的突破,更为影视行业用户反馈自动化分析、文化产品市场洞察等实际应用奠定了坚实基础,凸显了高质量非英语语料库在全球化NLP研究中的重要战略价值。
以上内容由遇见数据集搜集并总结生成


