TheFinAI/corpus-shard-00
收藏Hugging Face2026-05-05 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/TheFinAI/corpus-shard-00
下载链接
链接失效反馈官方服务:
资源简介:
文本语料库分片。文件位于`parts/`目录下。
Text corpus shard. Files are under `parts/`.
提供机构:
TheFinAI
搜集汇总
数据集介绍
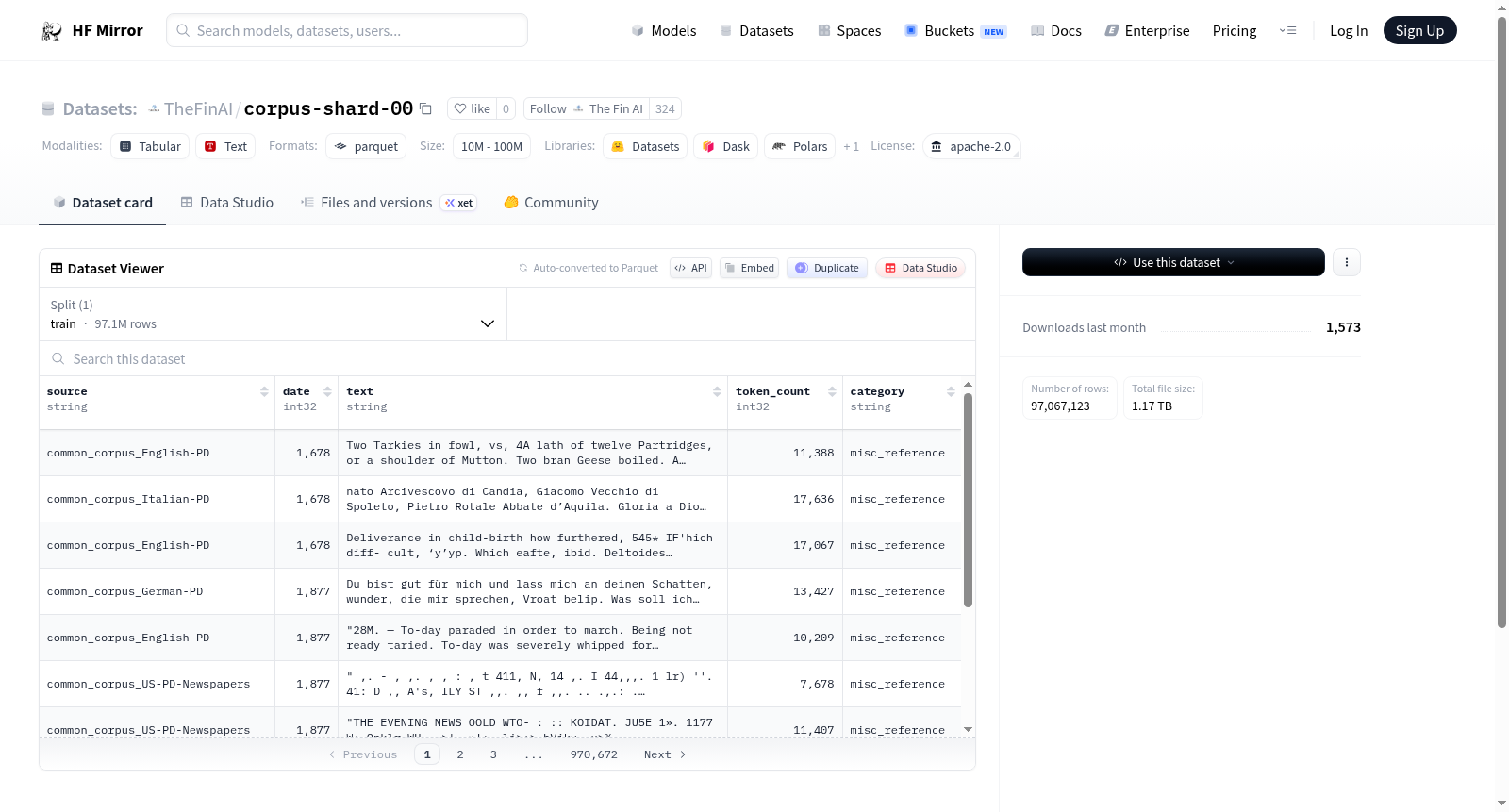
构建方式
在自然语言处理领域,大规模文本语料库是预训练语言模型的基础资源。corpus-shard-00作为corpus-shard数据集的一个分片,由众多文本文件组成,这些文件被统一存放于`parts/`目录下。该数据集采用分片存储策略,将庞大的原始文本数据切分为多个独立且易于管理的部分,便于分布式处理与高效加载。每个分片均遵循Apache-2.0开源许可协议发布,保障了学术与商业场景下的合法使用。
特点
corpus-shard-00的核心特点在于其模块化的分片结构,使得研究者能够仅加载所需的部分数据,从而降低内存消耗与预处理时间。数据集采用统一的目录组织方式,所有文本文件均置于`parts/`内,命名规范清晰,便于程序化遍历与索引。此外,基于Apache-2.0许可证的开源性,确保了该语料库在各类研究项目中的广泛适用性与可复现性,尤其适合用于语言模型的预训练或领域适配微调。
使用方法
使用时,可直接通过读取`parts/`目录下的所有文本文件来获取完整数据集。对于Python环境,推荐使用`os.listdir`或`glob`模块递归扫描该目录,随后利用标准文件读取接口逐文件加载文本内容。由于数据以纯文本格式存储,无需额外解码步骤,可直接进行分词、清洗等预处理操作。若训练任务涉及多节点分布式计算,可将不同分片分配给不同计算单元,实现并行数据加载与模型训练,显著提升效率。
背景与挑战
背景概述
随着自然语言处理领域对大规模无监督文本数据需求的日益增长,如何高效收集与组织海量语料成为推动模型性能提升的关键。corpus-shard-00数据集由相关研究团队创建,采用分片(shard)形式存储文本数据,旨在为大规模语言模型预训练提供标准化的语料片段。该数据集以Apache-2.0许可证开源,便于学术与工业界在可复现的基础上进行模型训练与评测,其分片结构的设计理念对提升数据加载效率与分布式处理能力具有重要意义。
当前挑战
corpus-shard-00面临的挑战主要体现在两个方面。首先,在领域问题上,尽管大规模文本语料支撑了语言模型的泛化能力,但数据来源的多样性与噪声控制仍是瓶颈,单一分片可能无法覆盖充分的语义多样性,导致模型对特定领域知识的捕获不足。其次,在构建过程中,分片策略的粒度选择、数据清洗的一致性维护以及跨分片间的统计均衡性均构成技术难点,此外,如何在不破坏语料连贯性的前提下实现高效分片,并保证后续迭代的扩展性,也是亟待解决的工程挑战。
常用场景
经典使用场景
作为大规模文本语料的分布式存储片段,该数据集被广泛用于构建预训练语言模型的原始训练数据池,尤其适用于需要海量通用文本的领域,如自然语言处理中的无监督学习任务。研究者常将其作为语料库的组成部分,用于训练词向量、语言模型或进行文本表示学习,为下游任务提供基础语义支撑。
解决学术问题
该数据集解决了大规模文本数据分散存储与统一调用的核心矛盾,使得学术研究能够便捷地获取、组织和处理海量语料,支撑了模型泛化能力的提升。它有效缓解了数据碎片化带来的训练效率瓶颈,推动了非监督学习与迁移学习在机器翻译、情感分析等任务中的理论突破,为评估模型在不同领域文本上的鲁棒性提供了标准化数据基础。
衍生相关工作
基于该数据集的分片特性,衍生了一系列分布式训练框架与数据调度算法,如分片式预训练策略和动态采样机制。相关经典工作包括探究数据分片对模型训练稳定性的影响,以及设计自适应语料权重分配方案以优化长尾分布下的学习效果。这些研究进一步拓展了大规模语料库在高吞吐计算场景中的方法论体系。
以上内容由遇见数据集搜集并总结生成


