有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
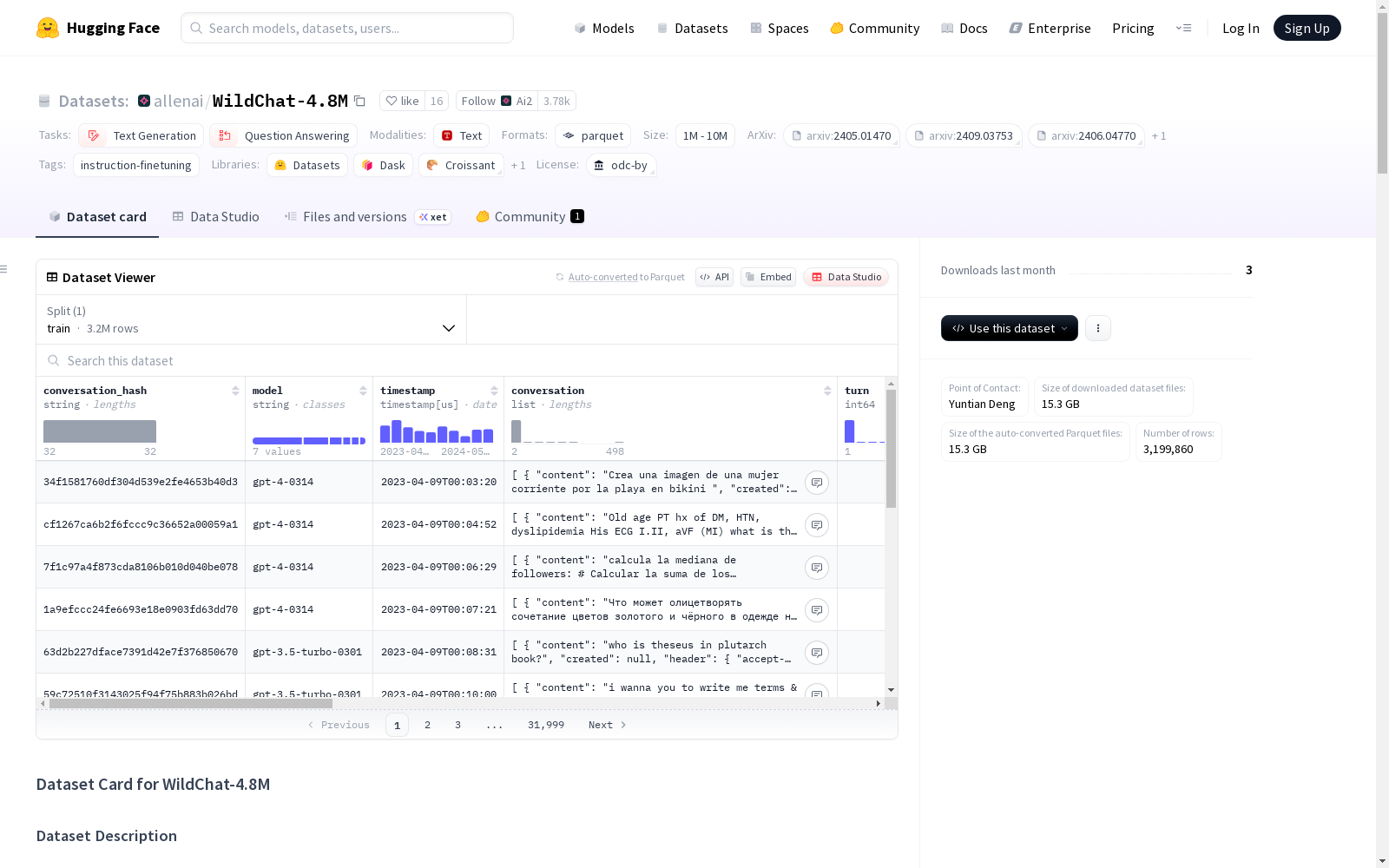
| 模型家族 | 数量 |
|---|---|
| gpt-4o | 1,539,780 |
| gpt-3.5-turbo | 688,900 |
| gpt-4.1-mini | 634,037 |
| gpt-4 | 202,915 |
| o1-mini | 58,529 |
| o1-preview | 53,307 |
| gpt-4-turbo | 22,392 |
| 总计 | 3,199,860 |
conversation_hash: 对话内容的哈希值model: 使用的OpenAI模型timestamp: 对话最后轮次的时间戳conversation: 对话轮次列表
content: 对话内容created: 创建时间header: 请求头信息hashed_ip: 哈希IP地址country: 国家toxic: 是否毒性内容redacted: 是否匿名化state: 状态language: 语言openai_id: OpenAI IDrole: 角色temperature: 温度参数timestamp: 时间戳token_counter: 令牌计数top_p: top_p参数turn_identifier: 轮次标识符system_fingerprint: 系统指纹usage: 使用情况turn: 对话轮次数language: 对话语言openai_moderation: OpenAI审核结果detoxify_moderation: Detoxify审核结果toxic: 是否包含毒性内容redacted: 是否匿名化state: 状态country: 国家hashed_ip: 哈希IP地址header: 请求头信息bibtex @inproceedings{ zhao2024wildchat, title={WildChat: 1M Chat{GPT} Interaction Logs in the Wild}, author={Wenting Zhao and Xiang Ren and Jack Hessel and Claire Cardie and Yejin Choi and Yuntian Deng}, booktitle={The Twelfth International Conference on Learning Representations}, year={2024}, url={https://openreview.net/forum?id=Bl8u7ZRlbM} }
bibtex @inproceedings{deng2024wildvis, title = "{W}ild{V}is: Open Source Visualizer for Million-Scale Chat Logs in the Wild", author = "Deng, Yuntian and Zhao, Wenting and Hessel, Jack and Ren, Xiang and Cardie, Claire and Choi, Yejin", booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations", year = "2024", url = "https://aclanthology.org/2024.emnlp-demo.50/" }
中国劳动力动态调查
“中国劳动力动态调查” (China Labor-force Dynamics Survey,简称 CLDS)是“985”三期“中山大学社会科学特色数据库建设”专项内容,CLDS的目的是通过对中国城乡以村/居为追踪范围的家庭、劳动力个体开展每两年一次的动态追踪调查,系统地监测村/居社区的社会结构和家庭、劳动力个体的变化与相互影响,建立劳动力、家庭和社区三个层次上的追踪数据库,从而为进行实证导向的高质量的理论研究和政策研究提供基础数据。
中国学术调查数据资料库 收录
钻孔成像测井解译数据(2021-2022年)
利用测井设备实时获取的雄安新区D19,D21,D22,冀中坳陷地区JZ01,JZ04钻孔的测井数据,并由Techlog软件 WBI井眼成像解释模块解译的裂缝原始数据
国家地球系统科学数据中心 收录
CHARLS
中国健康与养老追踪调查(CHARLS)数据集,旨在收集反映中国45岁及以上中老年人家庭和个人的高质量微观数据,用以分析人口老龄化问题,内容包括健康状况、经济状况、家庭结构和社会支持等。
charls.pku.edu.cn 收录
UIEB, U45, LSUI
本仓库提供了水下图像增强方法和数据集的实现,包括UIEB、U45和LSUI等数据集,用于支持水下图像增强的研究和开发。
github 收录
广东省标准地图
该数据类主要为广东省标准地图信息。标准地图依据中国和世界各国国界线画法标准编制而成。该数据包括广东省全图、区域地图、地级市地图、县(市、区)地图、专题地图、红色印迹地图等分类。
开放广东 收录