Health Insurance Coverage Rule Interpretation Corpus
收藏arXiv2025-07-28 更新2025-08-08 收录
下载链接:
https://huggingface.co/datasets/Persius/hicric
下载链接
链接失效反馈官方服务:
资源简介:
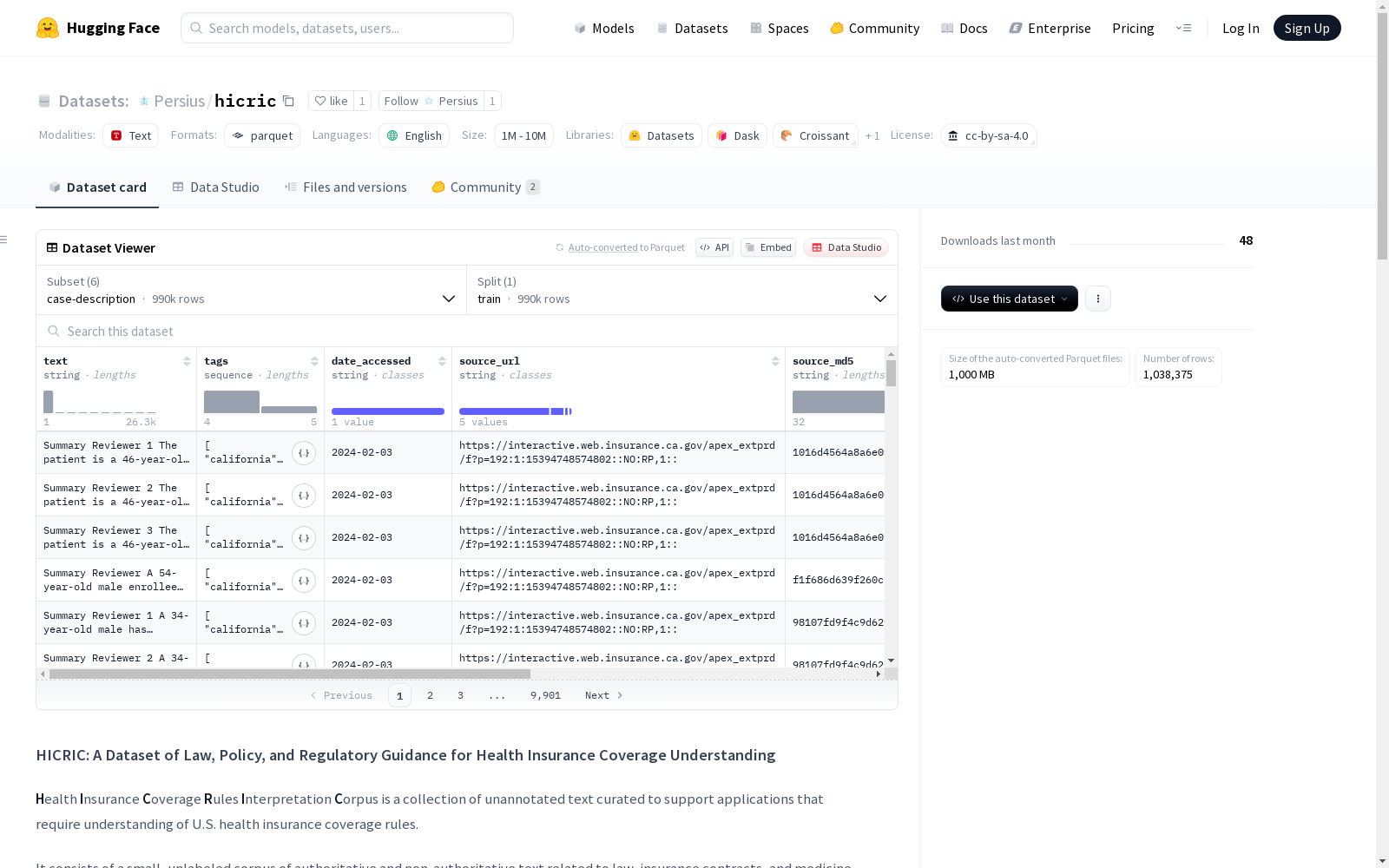
该数据集由8,311篇文档组成,包含美国联邦和州法律、保险合同、官方监管指南、机构意见和政策简报、医疗保险和医疗补助的官方覆盖规则以及上诉裁决摘要。数据集旨在支持预训练和下游任务,例如文档分类、实体和条款选择、多项选择题回答等。该数据集对于研究和开发支持医疗保健和司法获取的自然语言处理工具具有重要意义。
This dataset consists of 8,311 documents, encompassing U.S. federal and state laws, insurance contracts, official regulatory guidelines, agency opinions and policy briefs, official coverage rules for Medicare and Medicaid, and summaries of appeal rulings. It is designed to support pre-training and downstream tasks such as document classification, entity and clause selection, multiple-choice question answering, and more. This dataset holds significant importance for research and development of natural language processing tools that support access to healthcare and justice.
提供机构:
美国相关研究机构
创建时间:
2025-07-28
搜集汇总
数据集介绍
构建方式
Health Insurance Coverage Rule Interpretation Corpus的构建基于对美国医疗保险相关法律、政策和医学指南的系统性收集与整理。研究团队从权威的法律和医学文本中筛选了8,311份文档,涵盖联邦与州法律、保险合约、监管指南、医疗政策等六大类别。通过人工标注与自动化模型相结合的方式,对案例描述进行背景提取和充分性标注,最终形成包含4.19亿单词的语料库。数据集特别设计了文档级标签系统,包括法律类型、监管权限等元数据,以支持精准的信息检索和知识推理。
特点
该数据集的核心价值在于其跨领域的权威性整合,首次系统性地融合了法律条文(如美国法典)、行政规范(如CMS监管指南)和临床医学文献(如FDA指南)。其特色包括:1) 严格的来源质量控制,所有文档均来自政府机构或权威医学期刊;2) 创新的三级分类体系,将案例结果预测任务划分为'推翻'、'维持'和'信息不足'三类;3) 动态知识标签系统,通过'kb'标签标识具有法律约束力的文本,为检索增强生成(RAG)提供可靠知识源。数据集还包含73,987个保险申诉案例,涵盖商业保险、医疗补助等主要保险类型。
使用方法
该数据集支持三类主要应用场景:1) 作为领域自适应预训练语料,可提升法律-医疗交叉领域的语言模型性能,研究显示基于本语料微调的DistilBERT模型在申诉结果预测任务上达到73.3%准确率;2) 作为监管分析工具,通过案例结果预测模型可识别系统性拒保问题,辅助政策制定;3) 患者自助应用开发,模型可提供申诉成功率评估(需配合风险提示机制)。使用时建议结合文档标签进行分层检索,如通过'legal+medicaid+new-york'标签组合精准定位相关法律条文。对于预测任务,应注意输入文本需符合'申诉前已知信息'的约束条件,避免使用包含裁决结果的文本段落。
背景与挑战
背景概述
Health Insurance Coverage Rule Interpretation Corpus是由Mike Gartner于2025年创建的一个专注于美国医疗保险规则理解的数据集。该数据集汇集了来自法律、政策和医学领域的权威文本,旨在支持自然语言处理技术在医疗保险领域的应用,特别是在保险申诉结果预测方面。数据集的构建基于对复杂医疗保险规则的理解需求,这些规则涉及法律条文、保险合同和医学文献的交叉引用,为研究者和从业者提供了一个宝贵的资源。
当前挑战
该数据集面临的挑战主要包括:1) 领域问题的复杂性,即如何准确预测保险申诉结果,这需要考虑多变的法规、合同条款和医学指南;2) 数据构建过程中的挑战,包括从历史案例中提取不泄露结果的有效背景信息,以及确保数据来源的权威性和非冗余性。此外,数据集的应用还面临着如何在实际部署中避免传播历史偏见和确保预测工具的负责任使用的挑战。
常用场景
经典使用场景
Health Insurance Coverage Rule Interpretation Corpus 数据集在自然语言处理领域中被广泛用于健康保险覆盖规则的理解和解释任务。该数据集整合了美国联邦和州法律、保险合同、官方监管指南以及医疗文献等多源文本,为研究者提供了一个全面的语料库。其经典使用场景包括训练和评估模型在健康保险上诉结果预测任务中的表现,支持法律和医疗领域的专业人员进行高效的案例分析和决策。
实际应用
在实际应用中,Health Insurance Coverage Rule Interpretation Corpus 数据集被用于开发支持患者和案例工作者的工具,帮助他们理解保险覆盖规则并预测上诉结果。例如,医疗机构和法律顾问可以利用基于该数据集训练的模型,快速评估保险拒赔案例的胜诉可能性,从而优化资源分配并提高服务效率。此外,监管机构也可借助这些工具监测保险公司的合规性,确保患者权益得到保障。
衍生相关工作
该数据集衍生了一系列经典研究工作,特别是在法律和医疗交叉领域的自然语言处理任务中。例如,研究者利用该数据集开发了基于BERT和DistilBERT的上诉结果预测模型,并在临床和法律文本分类任务中取得了显著成果。此外,数据集还被用于检索增强生成(RAG)管道的开发,支持生成具有权威依据的法律和医疗建议,进一步拓展了其在多模态和知识密集型任务中的应用。
以上内容由遇见数据集搜集并总结生成


