khaledmahmoud/spanish_simplification_20k
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/khaledmahmoud/spanish_simplification_20k
下载链接
链接失效反馈官方服务:
资源简介:
该数据集提供了20K个西班牙语简化样本,涵盖多个主题,专为有认知挑战的人群设计。样本长度不一,从短到长均有涵盖。该数据集可用于补充更大的训练语料库,以微调小型语言模型(如Gemma 4B),将复杂的西班牙语简化为更简单的西班牙语,或将英语直接翻译为简化的西班牙语。数据集来源于MarcOrfilaCarreras西班牙新闻数据集,通过OpenAI GPT-5.4进行样本提取、清理、简化、翻译和评估。
This dataset provides 20K samples for Spanish simplification across a diverse range of topics, designed for people with cognitive challenges. The samples vary in length, from short to long. This dataset can supplement a larger training corpus for fine-tuning small language models, such as Gemma 4B, to simplify complex Spanish into simpler Spanish or translate English directly into simplified Spanish. The dataset was synthesized from the MarcOrfilaCarreras Spanish News dataset, using OpenAI GPT-5.4 for sample extraction, cleaning, simplification, translation, and evaluation.
提供机构:
khaledmahmoud
搜集汇总
数据集介绍
构建方式
该数据集结合了自动提取与人工评估的双重机制,以构建高质量西班牙语简化文本。研究者从MarcOrfilaCarreras西班牙语新闻数据集中选取10,200篇新闻文章,每篇抽取两个样本,共计生成20,000条数据。采用OpenAI GPT-5.4模型对原始样本进行抽取、清洗、简化、翻译及质量评分。简化过程严格遵循认知障碍友好原则,涵盖主题前置、单句单意、主动语态、常用词汇替换等策略,并对每条简化文本与原始文本分别进行可读性评分,通过计算可读性差异衡量简化效果。同时,将西班牙语原文翻译为英语,并评估翻译对原文语义的保真度,确保数据集的准确性与实用性。
特点
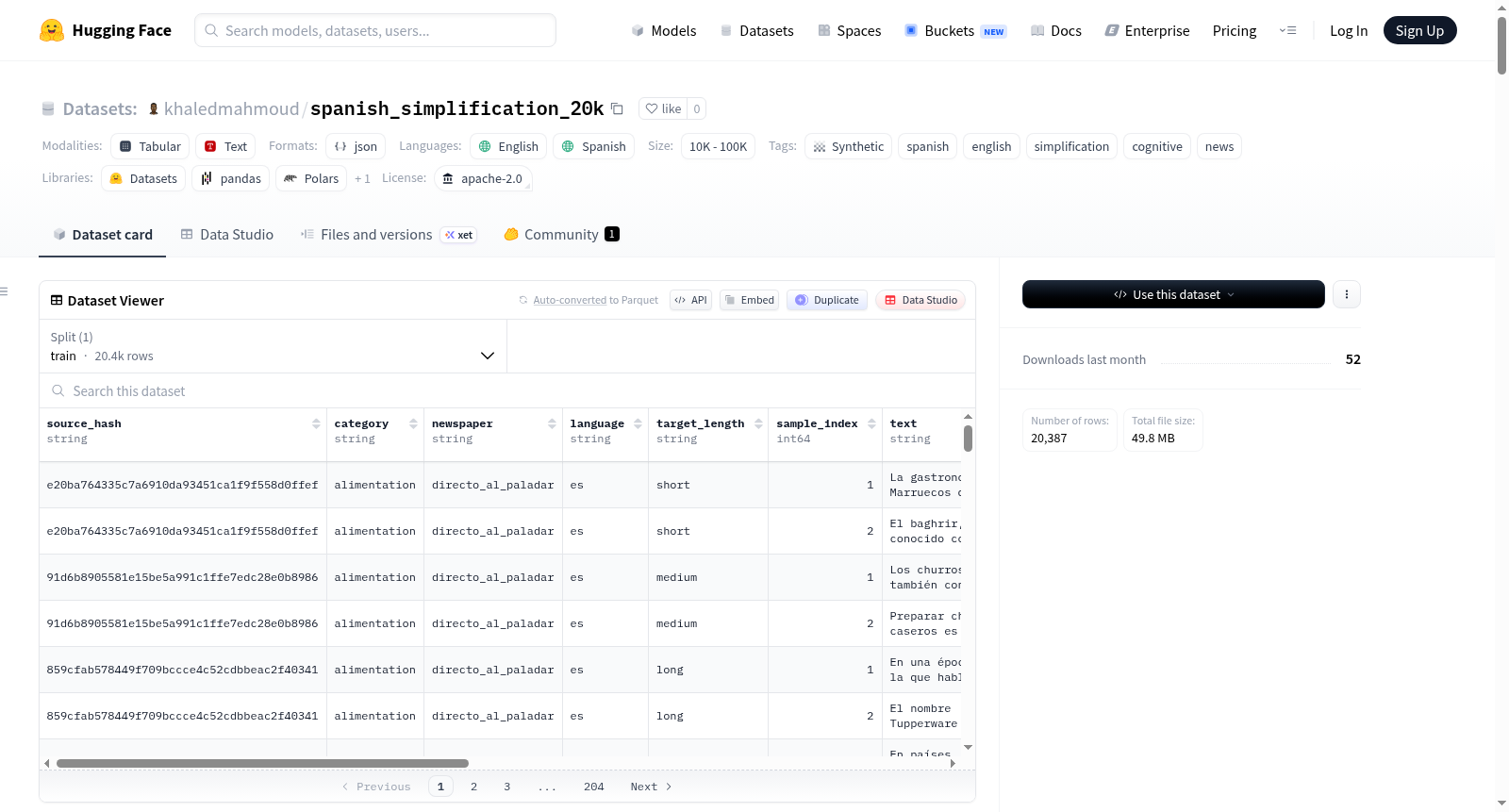
本数据集具备显著的结构化多样性与认知适配特性。样本按长度分为短(35-80词)、中(81-150词)、长(151-260词)三类,各约6,800条,覆盖从精炼到详尽的文本层级。主题涵盖饮食、天文、经济、时尚、医学、军事、汽车、娱乐、政治、宗教、体育、科技等12个领域,每类主题均含约1,700条样本,保证主题分布的平衡性与广泛性。每条数据包含原始文本、简化文本、英文翻译、可读性评分及语义保真度评分等15个字段,为研究者提供多维度评估指标。尤其值得注意的是,可读性评分采用加权维度体系,从理解难度、结构组织、句子可处理性、用词清晰度、逻辑连贯性及自然度六个层面综合评估,充分体现对认知障碍人群的深度人文关怀。
使用方法
该数据集适用于微调小型语言模型(如Gemma 4B)以执行西班牙语文本简化任务。研究者可将数据集作为基础训练语料,直接用于西班牙语到简化西班牙语的转换任务;亦可利用其中的英文翻译字段,训练模型将英文文本直接生成为简化西班牙语。数据集的多样化主题与文本长度使其成为扩增更大规模训练集的理想补充资源。使用时,研究者可依据可读性差异分数筛选简化效果显著的样本,或按主题、长度进行子集划分以进行针对性训练。该数据集还提供了完整的简化策略指南,涵盖句法简化、词汇替换、指代清晰化等操作细则,可作为模型训练时的提示工程参考,提升生成文本的认知友好性。
背景与挑战
背景概述
在自然语言处理领域,文本简化旨在降低语言复杂度以提升可读性,尤其对认知障碍人群具有重要社会价值。然而,现有简化资源多集中于英语,西班牙语的多样化简化语料库长期匮乏。为此,Khaled Mahmoud、Al Alwadi及Salem Al-Qahtani等研究者于2024年基于MarcOrfilaCarreras西班牙新闻数据集,通过GPT-5.4构建了包含20,000条样本的Alma数据集。该数据集横跨天文、经济、医学等12个主题,样本长度覆盖短、中、长三类,并同步提供西班牙语简化版本及英语翻译,辅以语义保留与可读性双重评分。作为首个面向认知障碍群体的多样化西班牙语简化资源,其不仅弥补了小语种模型的训练缺口,更通过透明化的合成流程为低资源语言的可及性研究树立了新范式。
当前挑战
该数据集的核心挑战在于双维度领域问题:一方面,现有西班牙语简化研究长期受限于单一主题(如新闻或医患沟通),难以支撑面向认知障碍人群的通用模型训练,而Alma需在涵盖12个主题的新闻语料中实现跨领域语义简化,确保简化文本既保留事实细节又降低认知负荷;另一方面,构建过程中面临合成质量的精确平衡——依赖GPT-5.4自动执行提取、简化、翻译与评估全流程,需设计复杂的评分机制(如源文本与简化文本的accessibility_delta)来过滤模型产生的简化过度或信息扭曲,同时通过可复现的提示工程(包括宾语前置转换、代词消歧等)弥补自动化流水线在尊重原义与降低复杂度之间的细微偏差。
常用场景
经典使用场景
在自然语言处理与认知辅助技术的交汇领域,spanish_simplification_20k数据集为面向认知障碍人群的西班牙语文本简化研究提供了宝贵资源。研究者可借此微调轻量级语言模型,如Gemma 4B,从而将复杂西班牙语文本转化为易于理解的简化版本,或直接将英语文本翻译为简化西班牙语。该数据集涵盖12个主题领域,样本长度从短至长分布均匀,使其成为训练和评估文本简化模型理想的基础语料库。
衍生相关工作
该数据集的构建方法论衍生出一系列创新工作,包括启发式抽取管道、多维度可访问性评估框架以及跨语言简化翻译协同策略。后续研究者受其启发,进一步探索了基于对比学习的简化质量自动评估模型,并开发了融合领域知识的个性化简化系统。这些工作共同推动了认知可及性自然语言处理领域的范式演进,使文本简化技术从通用模型走向精细化、场景化的应用路径。
数据集最近研究
最新研究方向
该数据集聚焦于面向认知障碍人群的西班牙语文本简化前沿研究,结合大型语言模型(如GPT-5.4)进行合成数据生成,涵盖12个主题领域(如政治、经济、科技)并控制文本长度多样性。研究工作重点关注通过主动语态转换、主谓贴近、因果关系显化等技术降低认知负荷,并引入可及性评分(0-100分)量化简化效果。这一方向与当前大模型驱动的无障碍信息处理热点紧密关联,为小型模型(如Gemma 4B)的微调提供了高质量训练基座,对推动跨语言(英语-西班牙语)的认知包容性文本改造具有重要实践意义。
以上内容由遇见数据集搜集并总结生成


