pamela
收藏Hugging Face2026-05-11 更新2026-05-12 收录
下载链接:
https://huggingface.co/datasets/pamela-dataset/pamela
下载链接
链接失效反馈官方服务:
资源简介:
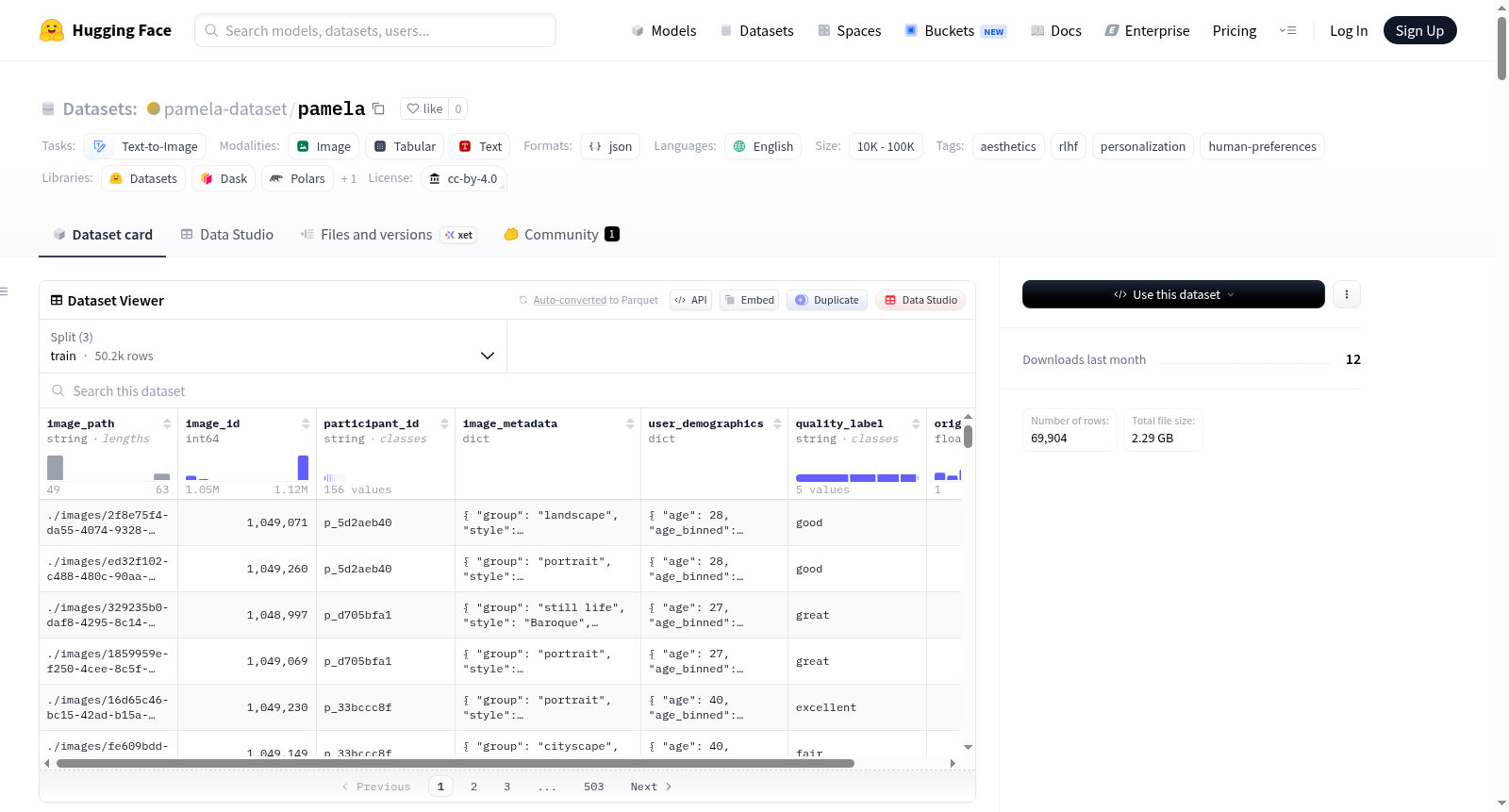
PAMELA(Personalizing Text-to-Image Generation to Individual Taste)是一个专门为个性化研究构建的数据集,其核心内容是AI生成图像及其对应的人类美学质量评级。该数据集旨在支持个性化美学预测、视觉偏好的人口统计差异研究以及生成内容的奖励建模。数据集包含总计69,904个美学评级,覆盖5,077张独特的AI生成图像。这些图像分为‘艺术’和‘超写实’两种主要类型,并进一步细分为21个视觉主题组(如抽象、动物、建筑等),其中‘艺术’类图像应用了26种不同的艺术史风格(如印象派、立体主义等)。数据来自199名参与者,他们提供了年龄(19-60岁)、性别(男、女、不愿透露)和国籍(23个国家)等人口统计信息。每个数据条目都结构化为JSON格式,包含图像路径与ID、详细的图像元数据(组、风格、类型、生成提示)、匿名的参与者ID及其人口统计信息,以及美学评级(分为‘差’到‘优秀’五个等级的质量标签和1.0-5.0的连续原始分数)。数据集被精心划分为训练集(pamela_train,50,222个评级)、验证集(包含未见用户pamela_val_unseen和已知用户pamela_val_seen)和测试集(包含未见用户pamela_test_unseen和已知用户pamela_test_seen),以分别评估模型对已知用户新图像的预测能力以及对全新用户的泛化能力。数据集通过Krippendorffs α和组内相关系数等指标评估了评级者间的一致性。需要注意的是,参与者样本并非全球人口的代表,且某些人口统计子群体样本量较小。数据集在CC-BY-4.0许可下发布,图像由Nano Banana和FLUX.2模型生成。其预期用途明确为个性化美学研究,不适用于建立普适的美学标准或进行技术性的图像质量评估。
PAMELA (Personalizing Text-to-Image Generation to Individual Taste) is a dataset specifically constructed for personalized research, with its core content being AI-generated images and their corresponding human aesthetic quality ratings. The dataset aims to support personalized aesthetic prediction, study demographic differences in visual preferences, and reward modeling for generated content. It contains a total of 69,904 aesthetic ratings covering 5,077 unique AI-generated images. These images are divided into two main types: art and hyperrealistic, and further subdivided into 21 visual thematic groups (such as abstract, animals, architecture, etc.), with art type images applying 26 different art history styles (e.g., Impressionism, Cubism, etc.). Data comes from 199 participants who provided demographic information including age (19-60), gender (male, female, prefer not to say), and nationality (23 countries). Each data entry is structured in JSON format, containing image path and ID, detailed image metadata (group, style, type, generation prompt), anonymous participant ID and their demographic information, as well as aesthetic ratings (quality labels from poor to excellent and continuous raw scores from 1.0 to 5.0). The dataset is carefully divided into a training set (pamela_train, 50,222 ratings), validation set (including unseen users pamela_val_unseen and known users pamela_val_seen), and test set (including unseen users pamela_test_unseen and known users pamela_test_seen) to respectively evaluate the models ability to predict new images for known users and generalize to entirely new users. The dataset assesses inter-rater consistency using metrics such as Krippendorffs α and intraclass correlation coefficients. It is important to note that the participant sample is not representative of the global population, and some demographic subgroups have small sample sizes. The dataset is released under the CC-BY-4.0 license, with images generated by the Nano Banana and FLUX.2 models. Its intended use is explicitly for personalized aesthetic research and is not suitable for establishing universal aesthetic standards or conducting technical image quality assessments.
创建时间:
2026-05-11
搜集汇总
数据集介绍
构建方式
PAMELA数据集的构建根植于对个性化审美建模的探索,旨在捕捉人类对AI生成图像的主观偏好差异。研究团队招募了199名来自23个国家的参与者,年龄横跨19至60岁,涵盖多元性别与国籍背景。每位参与者对5077张由文本到图像模型生成的图像进行美学评分,评分采用从“差”到“优秀”的五级标签,并同时映射为1.0至5.0的连续分值。每张图像平均获得约14次独立评分,最终汇聚成69004条评级记录。数据集按用户是否在训练集中出现划分为“seen”与“unseen”子集,以分别评估模型对已知用户推荐新图像及泛化至全新用户的能力。图像内容覆盖21个视觉分组与26种艺术史风格,分为艺术与写实两大类型,确保视觉刺激的丰富性与领域覆盖度。
特点
PAMELA的核心特色在于其将个体化审美偏好与丰富的人口统计学元数据深度融合。每条评级不仅记录了图像本身的内容特征,如视觉分组、艺术风格及生成提示,还关联了评级的用户画像,包括年龄、性别与国籍。这种细粒度的配对结构使得研究者能够剖析不同人口学群体在审美判断上的异质性,并构建可泛化至新用户的个性化评分模型。数据集展现了较低的单评分者信度,但通过多评分者平均,信度显著提升至0.82以上,这反映了审美评价的主观本质与群体判定的稳定性。此外,数据集中所有图像均为AI生成,为研究生成模型的美学偏差与风格偏好提供了独特的实验平台。
使用方法
PAMELA数据集专为个性化审美预测与奖励建模设计,在文本到图像生成领域具有广泛的应用潜力。研究者可基于训练子集构建用户嵌入或协同过滤模型,以学习个体偏好表示;在“unseen”分割上进行评估,可检验模型对新用户的零样本泛化能力。结合图像元数据,可开展条件审美分析,探索不同风格或视觉主题下的偏好分布。数据集提供的连续评分与离散标签均支持回归与分类任务,而人口统计学特征则可作为辅助特征或控制变量。在使用时,需注意其样本非全球代表性,避免将聚合得分视为普适性审美标准,且应尊重图像生成模型的服务条款。
背景与挑战
背景概述
在文本到图像生成领域,如何将生成结果从通用美学标准迁移至个体用户偏好,始终是制约个性化人机交互发展的核心命题。PAM∃LA数据集诞生于2026年,由匿名研究团队在盲审阶段发布,其核心研究问题聚焦于建模个体审美偏好对AI生成图像质量评价的差异性影响。该数据集包含199名参与者对5077张AI生成图像的近7万条标注,每个评分均关联详细的人口统计信息与图像元数据,覆盖21个视觉类别与26种艺术风格。通过提供已知用户与新用户的划分评估协议,PAM∃LA为个性化审美预测、奖励模型构建以及偏好驱动的生成优化提供了标准化基准,有力推动了文本到图像个性化生成技术的实证研究。
当前挑战
该数据集的核心挑战在于解构个体审美偏好的高度异质性,使模型能够摆脱聚合评分的均值化陷阱,适应不同用户在视觉内容上的差异化价值判断。构建过程中面临三重困难:首先,参与人群虽涵盖23个国籍,但样本分布高度集中——英国与美国占比超过42%,欧裔群体占据主导,导致对非西方审美观念的代表性显著不足;其次,所有图像由Nano Banana与FLUX.2两款模型生成,其美学特征内嵌了源模型的风格偏差与生成瑕疵,限制了结论向其他生成系统或自然图像的泛化能力;最后,单张图像的平均评分者数量仅为13.77,且评分分布偏好相异度(Krippendorff's α仅0.206)表明评分者间存在显著分歧,如何在有限标注密度下提取稳健的个体偏好信号,成为模型设计与评估的关键瓶颈。
常用场景
经典使用场景
PAM∃LA数据集专为个性化文本到图像生成中的审美偏好建模而设计,其经典使用场景在于基于人类反馈的奖励模型训练。研究者可利用该数据集丰富的参与者画像(涵盖199位来自23个国家的评分者,年龄跨度19至60岁)与图像元数据(21个视觉组别与26种艺术风格),构建能够捕捉个体审美差异的预测模型。数据集精心划分了seen与unseen用户/图像子集,后者模拟了真实世界中面对全新用户时的冷启动挑战,成为评估个性化模型泛化能力的黄金基准。
实际应用
在产业实践中,PAM∃LA可直接赋能个性化内容推荐与定制化视觉生成系统。例如,广告平台可依据目标用户群体的人口统计特征,利用该数据集训练的偏好模型自动筛选最具吸引力的产品图像;数字艺术工具可学习个体用户对不同风格(如印象派与立体主义)的审美倾向,实时调整生成参数以匹配其独特品味。电影海报设计、虚拟家居装饰乃至社交媒体滤镜等场景,均可借助此类模型实现从“千人一面”到“因材施图”的体验升级,显著提升用户满意度和参与度。
衍生相关工作
PAM∃LA的发布催生了一系列探索审美个性化与人口统计偏差的经典工作。例如,研究者基于其数据开发了人口统计感知的奖励模型,能够显式校正不同性别或年龄段用户的偏好偏差;另有工作利用该数据集的组别标签,系统分析了AI图像在不同艺术风格(如写实主义与摄影写实)上是否存在与国籍相关的审美差异。此外,该数据集还启发了针对冷启动用户的高效偏好推断方法,通过迁移学习从有限评分中快速建模新用户品味,这些衍生研究共同推动了文本到图像生成领域向更具个性、更少偏见的未来迈进。
以上内容由遇见数据集搜集并总结生成


