DocLayNet-small
收藏魔搭社区2026-01-06 更新2025-01-25 收录
下载链接:
https://modelscope.cn/datasets/swift/DocLayNet-small
下载链接
链接失效反馈官方服务:
资源简介:
# Dataset Card for DocLayNet small
## About this card (01/27/2023)
### Property and license
All information from this page but the content of this paragraph "About this card (01/27/2023)" has been copied/pasted from [Dataset Card for DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet).
DocLayNet is a dataset created by Deep Search (IBM Research) published under [license CDLA-Permissive-1.0](https://huggingface.co/datasets/ds4sd/DocLayNet#licensing-information).
I do not claim any rights to the data taken from this dataset and published on this page.
### DocLayNet dataset
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB)
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet)
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022)
### Processing into a format facilitating its use by HF notebooks
These 2 options require the downloading of all the data (approximately 30GBi), which requires downloading time (about 45 mn in Google Colab) and a large space on the hard disk. These could limit experimentation for people with low resources.
Moreover, even when using the download via HF datasets library, it is necessary to download the EXTRA zip separately ([doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip), 7.5 GiB) to associate the annotated bounding boxes with the text extracted by OCR from the PDFs. This operation also requires additional code because the boundings boxes of the texts do not necessarily correspond to those annotated (a calculation of the percentage of area in common between the boundings boxes annotated and those of the texts makes it possible to make a comparison between them).
At last, in order to use Hugging Face notebooks on fine-tuning layout models like LayoutLMv3 or LiLT, DocLayNet data must be processed in a proper format.
For all these reasons, I decided to process the DocLayNet dataset:
- into 3 datasets of different sizes:
- [DocLayNet small](https://huggingface.co/datasets/pierreguillou/DocLayNet-small) (about 1% of DocLayNet) < 1.000k document images (691 train, 64 val, 49 test)
- [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) (about 10% of DocLayNet) < 10.000k document images (6910 train, 648 val, 499 test)
- [DocLayNet large](https://huggingface.co/datasets/pierreguillou/DocLayNet-large) (about 100% of DocLayNet) < 100.000k document images (69.103 train, 6.480 val, 4.994 test)
- with associated texts and PDFs (base64 format),
- and in a format facilitating their use by HF notebooks.
*Note: the layout HF notebooks will greatly help participants of the IBM [ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents](https://ds4sd.github.io/icdar23-doclaynet/)!*
### About PDFs languages
Citation of the page 3 of the [DocLayNet paper](https://arxiv.org/abs/2206.01062):
"We did not control the document selection with regard to language. **The vast majority of documents contained in DocLayNet (close to 95%) are published in English language.** However, **DocLayNet also contains a number of documents in other languages such as German (2.5%), French (1.0%) and Japanese (1.0%)**. While the document language has negligible impact on the performance of computer vision methods such as object detection and segmentation models, it might prove challenging for layout analysis methods which exploit textual features."
### About PDFs categories distribution
Citation of the page 3 of the [DocLayNet paper](https://arxiv.org/abs/2206.01062):
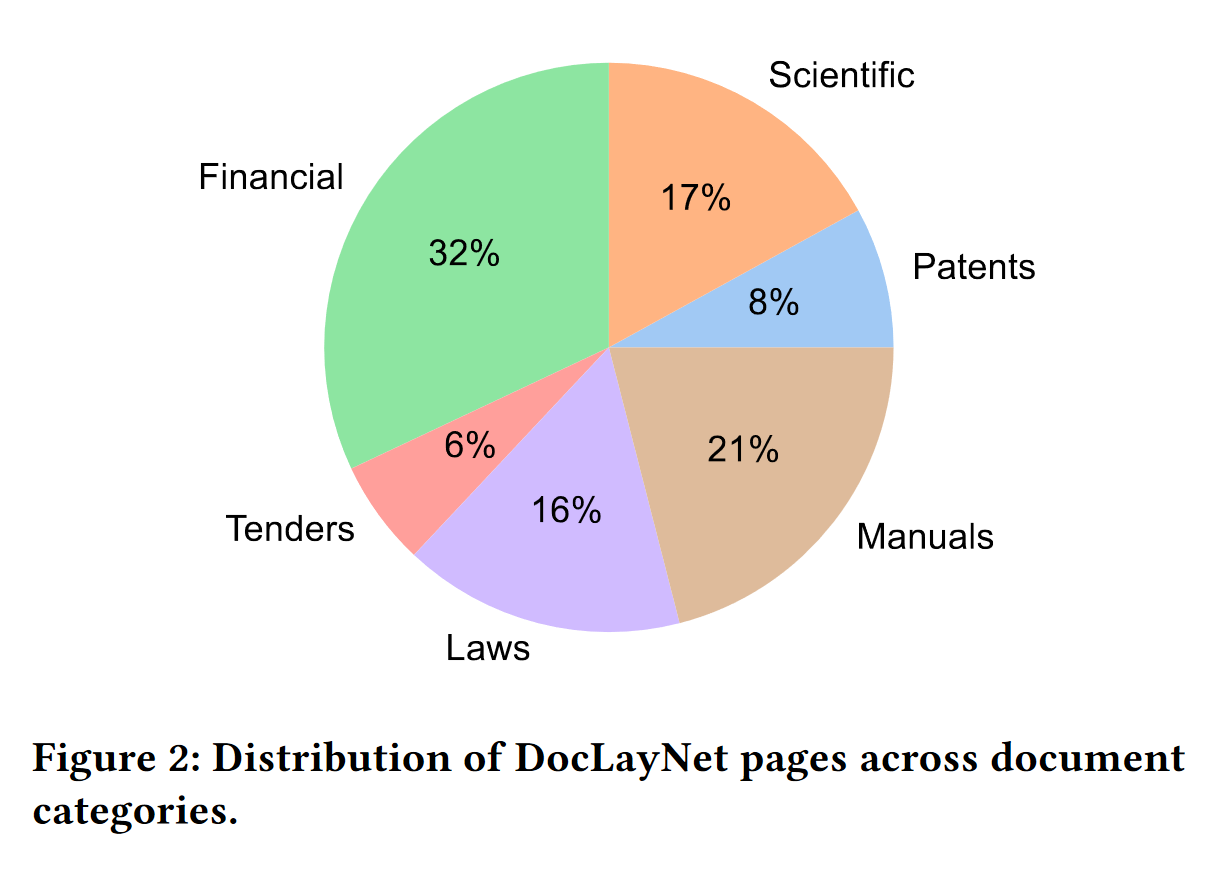
"The pages in DocLayNet can be grouped into **six distinct categories**, namely **Financial Reports, Manuals, Scientific Articles, Laws & Regulations, Patents and Government Tenders**. Each document category was sourced from various repositories. For example, Financial Reports contain both free-style format annual reports which expose company-specific, artistic layouts as well as the more formal SEC filings. The two largest categories (Financial Reports and Manuals) contain a large amount of free-style layouts in order to obtain maximum variability. In the other four categories, we boosted the variability by mixing documents from independent providers, such as different government websites or publishers. In Figure 2, we show the document categories contained in DocLayNet with their respective sizes."
### Download & overview
The size of the DocLayNet small is about 1% of the DocLayNet dataset (random selection respectively in the train, val and test files).
```
# !pip install -q datasets
from datasets import load_dataset
dataset_small = load_dataset("pierreguillou/DocLayNet-small")
# overview of dataset_small
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 691
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 64
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 49
})
})
```
### Annotated bounding boxes
The DocLayNet base makes easy to display document image with the annotaed bounding boxes of paragraphes or lines.
Check the notebook [processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb](https://github.com/piegu/language-models/blob/master/processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb) in order to get the code.
#### Paragraphes

#### Lines

### HF notebooks
- [notebooks LayoutLM](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLM) (Niels Rogge)
- [notebooks LayoutLMv2](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv2) (Niels Rogge)
- [notebooks LayoutLMv3](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3) (Niels Rogge)
- [notebooks LiLT](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT) (Niels Rogge)
- [Document AI: Fine-tuning LiLT for document-understanding using Hugging Face Transformers](https://github.com/philschmid/document-ai-transformers/blob/main/training/lilt_funsd.ipynb) ([post](https://www.philschmid.de/fine-tuning-lilt#3-fine-tune-and-evaluate-lilt) of Phil Schmid)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://developer.ibm.com/exchanges/data/all/doclaynet/
- **Repository:** https://github.com/DS4SD/DocLayNet
- **Paper:** https://doi.org/10.1145/3534678.3539043
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
DocLayNet provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories. It provides several unique features compared to related work such as PubLayNet or DocBank:
1. *Human Annotation*: DocLayNet is hand-annotated by well-trained experts, providing a gold-standard in layout segmentation through human recognition and interpretation of each page layout
2. *Large layout variability*: DocLayNet includes diverse and complex layouts from a large variety of public sources in Finance, Science, Patents, Tenders, Law texts and Manuals
3. *Detailed label set*: DocLayNet defines 11 class labels to distinguish layout features in high detail.
4. *Redundant annotations*: A fraction of the pages in DocLayNet are double- or triple-annotated, allowing to estimate annotation uncertainty and an upper-bound of achievable prediction accuracy with ML models
5. *Pre-defined train- test- and validation-sets*: DocLayNet provides fixed sets for each to ensure proportional representation of the class-labels and avoid leakage of unique layout styles across the sets.
### Supported Tasks and Leaderboards
We are hosting a competition in ICDAR 2023 based on the DocLayNet dataset. For more information see https://ds4sd.github.io/icdar23-doclaynet/.
## Dataset Structure
### Data Fields
DocLayNet provides four types of data assets:
1. PNG images of all pages, resized to square `1025 x 1025px`
2. Bounding-box annotations in COCO format for each PNG image
3. Extra: Single-page PDF files matching each PNG image
4. Extra: JSON file matching each PDF page, which provides the digital text cells with coordinates and content
The COCO image record are defined like this example
```js
...
{
"id": 1,
"width": 1025,
"height": 1025,
"file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png",
// Custom fields:
"doc_category": "financial_reports" // high-level document category
"collection": "ann_reports_00_04_fancy", // sub-collection name
"doc_name": "NASDAQ_FFIN_2002.pdf", // original document filename
"page_no": 9, // page number in original document
"precedence": 0, // Annotation order, non-zero in case of redundant double- or triple-annotation
},
...
```
The `doc_category` field uses one of the following constants:
```
financial_reports,
scientific_articles,
laws_and_regulations,
government_tenders,
manuals,
patents
```
### Data Splits
The dataset provides three splits
- `train`
- `val`
- `test`
## Dataset Creation
### Annotations
#### Annotation process
The labeling guideline used for training of the annotation experts are available at [DocLayNet_Labeling_Guide_Public.pdf](https://raw.githubusercontent.com/DS4SD/DocLayNet/main/assets/DocLayNet_Labeling_Guide_Public.pdf).
#### Who are the annotators?
Annotations are crowdsourced.
## Additional Information
### Dataset Curators
The dataset is curated by the [Deep Search team](https://ds4sd.github.io/) at IBM Research.
You can contact us at [deepsearch-core@zurich.ibm.com](mailto:deepsearch-core@zurich.ibm.com).
Curators:
- Christoph Auer, [@cau-git](https://github.com/cau-git)
- Michele Dolfi, [@dolfim-ibm](https://github.com/dolfim-ibm)
- Ahmed Nassar, [@nassarofficial](https://github.com/nassarofficial)
- Peter Staar, [@PeterStaar-IBM](https://github.com/PeterStaar-IBM)
### Licensing Information
License: [CDLA-Permissive-1.0](https://cdla.io/permissive-1-0/)
### Citation Information
```bib
@article{doclaynet2022,
title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation},
doi = {10.1145/3534678.353904},
url = {https://doi.org/10.1145/3534678.3539043},
author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J},
year = {2022},
isbn = {9781450393850},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages = {3743–3751},
numpages = {9},
location = {Washington DC, USA},
series = {KDD '22}
}
```
### Contributions
Thanks to [@dolfim-ibm](https://github.com/dolfim-ibm), [@cau-git](https://github.com/cau-git) for adding this dataset.
# DocLayNet small 数据集卡片
## 关于本卡片(2023年1月27日)
### 权属与许可
本页面除段落“关于本卡片(2023年1月27日)”外的所有信息均摘抄自[DocLayNet 数据集卡片](https://huggingface.co/datasets/ds4sd/DocLayNet)。
DocLayNet是由Deep Search(IBM研究院)创建的数据集,采用[CDLA-Permissive-1.0许可协议](https://huggingface.co/datasets/ds4sd/DocLayNet#licensing-information)发布。
本人不对本页面中转载的该数据集内容主张任何权利。
### DocLayNet 数据集
[DocLayNet 数据集](https://github.com/DS4SD/DocLayNet)(IBM出品)针对来自6类文档的80863张独立页面,提供了逐页的布局分割真值标注,包含11种不同类别标签的边界框(bounding-box)。
截至目前,该数据集可通过直接链接或Hugging Face数据集库下载:
- 直接链接:[doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip)(28 GiB)、[doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip)(7.5 GiB)
- Hugging Face数据集库:[DocLayNet 数据集](https://huggingface.co/datasets/ds4sd/DocLayNet)
相关论文:[DocLayNet:用于文档布局分析的大规模人工标注数据集](https://arxiv.org/abs/2206.01062)(2022年6月2日)
### 适配Hugging Face笔记本的格式处理
上述两种下载方式均需获取全部数据(总计约30 GiB),这会消耗下载时间(在Google Colab中约需45分钟)且占用大量硬盘空间,可能对资源有限的用户造成实验限制。
此外,即便通过Hugging Face数据集库下载,仍需单独下载EXTRA压缩包([doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip),7.5 GiB),才能将标注的边界框与通过光学字符识别(Optical Character Recognition)从PDF中提取的文本关联起来。该步骤还需额外代码,因为文本的边界框未必与标注的边界框完全匹配——可通过计算标注边界框与文本边界框的公共区域占比实现二者的匹配比对。
最后,若要在Hugging Face笔记本中微调布局模型(如LayoutLMv3或LiLT),需将DocLayNet数据处理为适配的格式。
基于上述原因,我对DocLayNet数据集进行了如下处理:
- 划分为三个不同规模的子数据集:
- [DocLayNet small](https://huggingface.co/datasets/pierreguillou/DocLayNet-small)(约占DocLayNet的1%):包含不足1000张文档图像(训练集691张、验证集64张、测试集49张)
- [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base)(约占DocLayNet的10%):包含不足10000张文档图像(训练集6910张、验证集648张、测试集499张)
- [DocLayNet large](https://huggingface.co/datasets/pierreguillou/DocLayNet-large)(约占DocLayNet的100%):包含不足100000张文档图像(训练集69103张、验证集6480张、测试集4994张)
- 附带关联的文本与PDF(base64格式)
- 采用适配Hugging Face笔记本的格式。
*注:该布局类Hugging Face笔记本将极大助力IBM举办的[ICDAR 2023企业文档鲁棒布局分割竞赛](https://ds4sd.github.io/icdar23-doclaynet/)的参与者!*
### 关于PDF的语言类型
引用[DocLayNet 论文](https://arxiv.org/abs/2206.01062)第3页内容:
> 我们未对文档的语言选择进行限制。**DocLayNet中绝大多数文档(接近95%)为英语发布**。不过,**DocLayNet也包含其他语言的文档,如德语(2.5%)、法语(1.0%)与日语(1.0%)**。尽管文档语言对目标检测与分割等计算机视觉方法的性能影响可忽略不计,但对于利用文本特征的布局分析方法而言,语言差异可能带来挑战。
### 关于PDF的类别分布
引用[DocLayNet 论文](https://arxiv.org/abs/2206.01062)第3页内容:
> DocLayNet中的页面可分为**6个不同类别**,分别为**财务报告、手册、学术论文、法律法规、专利与政府招标**。每个文档类别均来自多个不同的数据源。例如,财务报告既包含展现公司定制化、艺术化布局的自由格式年报,也包含更为正式的美国证券交易委员会(SEC,Securities and Exchange Commission)备案文件。规模最大的两个类别(财务报告与手册)包含大量自由格式布局,以实现最大的布局多样性。在其余四个类别中,我们通过混合来自不同独立提供商的文档(如不同政府网站或出版社的文档)来提升布局多样性。在图2中,我们展示了DocLayNet中各类文档的占比与规模。

### 下载与概览
DocLayNet small的规模约为DocLayNet数据集的1%(分别从训练、验证、测试文件中随机采样得到)。
# !pip install -q datasets
from datasets import load_dataset
dataset_small = load_dataset("pierreguillou/DocLayNet-small")
# 查看dataset_small的概览
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 691
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 64
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 49
})
})
### 标注边界框
DocLayNet base可便捷地展示带有段落或文本行标注边界框的文档图像。
可参考笔记本[processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb](https://github.com/piegu/language-models/blob/master/processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb)获取相关代码。
#### 段落级标注

#### 文本行级标注

### Hugging Face 笔记本
- [LayoutLM 相关笔记本](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLM)(Niels Rogge 制作)
- [LayoutLMv2 相关笔记本](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv2)(Niels Rogge 制作)
- [LayoutLMv3 相关笔记本](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3)(Niels Rogge 制作)
- [LiLT 相关笔记本](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT)(Niels Rogge 制作)
- [文档AI:使用Hugging Face Transformers微调LiLT实现文档理解](https://github.com/philschmid/document-ai-transformers/blob/main/training/lilt_funsd.ipynb)(Phil Schmid 相关[博文](https://www.philschmid.de/fine-tuning-lilt#3-fine-tune-and-evaluate-lilt))
## 目录
- [目录](#目录)
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与排行榜](#支持任务与排行榜)
- [数据集结构](#数据集结构)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [标注信息](#标注信息)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [许可信息](#许可信息)
- [引用信息](#引用信息)
- [贡献者](#贡献者)
## 数据集描述
- **主页**:https://developer.ibm.com/exchanges/data/all/doclaynet/
- **代码仓库**:https://github.com/DS4SD/DocLayNet
- **论文**:https://doi.org/10.1145/3534678.3539043
- **排行榜**:
- **联系方式**:
### 数据集概述
DocLayNet针对来自6类文档的80863张独立页面,提供了逐页的布局分割真值标注,包含11种不同类别标签的边界框。相较于PubLayNet、DocBank等同类数据集,DocLayNet具备多项独特优势:
1. **人工标注**:DocLayNet由经过专业训练的专家手工标注,通过人工识别与解读每个页面的布局,提供了布局分割任务的金标准标注
2. **丰富的布局多样性**:DocLayNet包含来自金融、学术、专利、招标、法律文本与手册等多种公开来源的多样化且复杂的布局
3. **精细的标签集**:DocLayNet定义了11种类别标签,可对布局特征进行高精度区分
4. **冗余标注**:DocLayNet中部分页面经过双标注或三标注,可用于估计标注不确定性,以及评估机器学习模型可达到的预测精度上限
5. **预定义划分集**:DocLayNet提供了固定的训练、验证与测试集,确保各类标签的比例均衡,避免不同划分集间出现布局样式泄露的问题。
### 支持任务与排行榜
我们基于DocLayNet数据集举办了ICDAR 2023竞赛,详细信息请见https://ds4sd.github.io/icdar23-doclaynet/。
## 数据集结构
### 数据字段
DocLayNet提供四类数据资源:
1. 所有页面的PNG图像,已调整为统一尺寸`1025 × 1025px`
2. 每张PNG图像对应的COCO格式边界框标注
3. 附加资源:与每张PNG图像对应的单页PDF文件
4. 附加资源:与每个PDF页面对应的JSON文件,包含带有坐标与内容的数字文本单元格
COCO图像记录的示例格式如下:
js
...
{
"id": 1,
"width": 1025,
"height": 1025,
"file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png",
// 自定义字段:
"doc_category": "financial_reports" // 高级文档类别
"collection": "ann_reports_00_04_fancy", // 子集合名称
"doc_name": "NASDAQ_FFIN_2002.pdf", // 原始文档文件名
"page_no": 9, // 原始文档中的页码
"precedence": 0, // 标注顺序,若为冗余双标注或三标注则该值非零
},
...
`doc_category`字段可使用以下固定取值:
financial_reports,
scientific_articles,
laws_and_regulations,
government_tenders,
manuals,
patents
### 数据划分
该数据集包含三个划分:
- `train`(训练集)
- `val`(验证集)
- `test`(测试集)
## 数据集构建
### 标注信息
#### 标注流程
用于培训标注专家的标注指南可在[DocLayNet_Labeling_Guide_Public.pdf](https://raw.githubusercontent.com/DS4SD/DocLayNet/main/assets/DocLayNet_Labeling_Guide_Public.pdf)获取。
#### 标注人员构成
标注工作由众包完成。
## 附加信息
### 数据集维护者
该数据集由IBM研究院的[Deep Search团队](https://ds4sd.github.io/)维护。
可通过邮箱[deepsearch-core@zurich.ibm.com](mailto:deepsearch-core@zurich.ibm.com)联系我们。
维护者:
- Christoph Auer, [@cau-git](https://github.com/cau-git)
- Michele Dolfi, [@dolfim-ibm](https://github.com/dolfim-ibm)
- Ahmed Nassar, [@nassarofficial](https://github.com/nassarofficial)
- Peter Staar, [@PeterStaar-IBM](https://github.com/PeterStaar-IBM)
### 许可信息
许可协议:[CDLA-Permissive-1.0](https://cdla.io/permissive-1.0/)
### 引用信息
bib
@article{doclaynet2022,
title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation},
doi = {10.1145/3534678.353904},
url = {https://doi.org/10.1145/3534678.3539043},
author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J},
year = {2022},
isbn = {9781450393850},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages = {3743–3751},
numpages = {9},
location = {Washington DC, USA},
series = {KDD '22}
}
### 贡献者
感谢[@dolfim-ibm](https://github.com/dolfim-ibm)、[@cau-git](https://github.com/cau-git)贡献本数据集。
提供机构:
maas
创建时间:
2025-01-20


