personal-information-prompts
收藏资源简介:
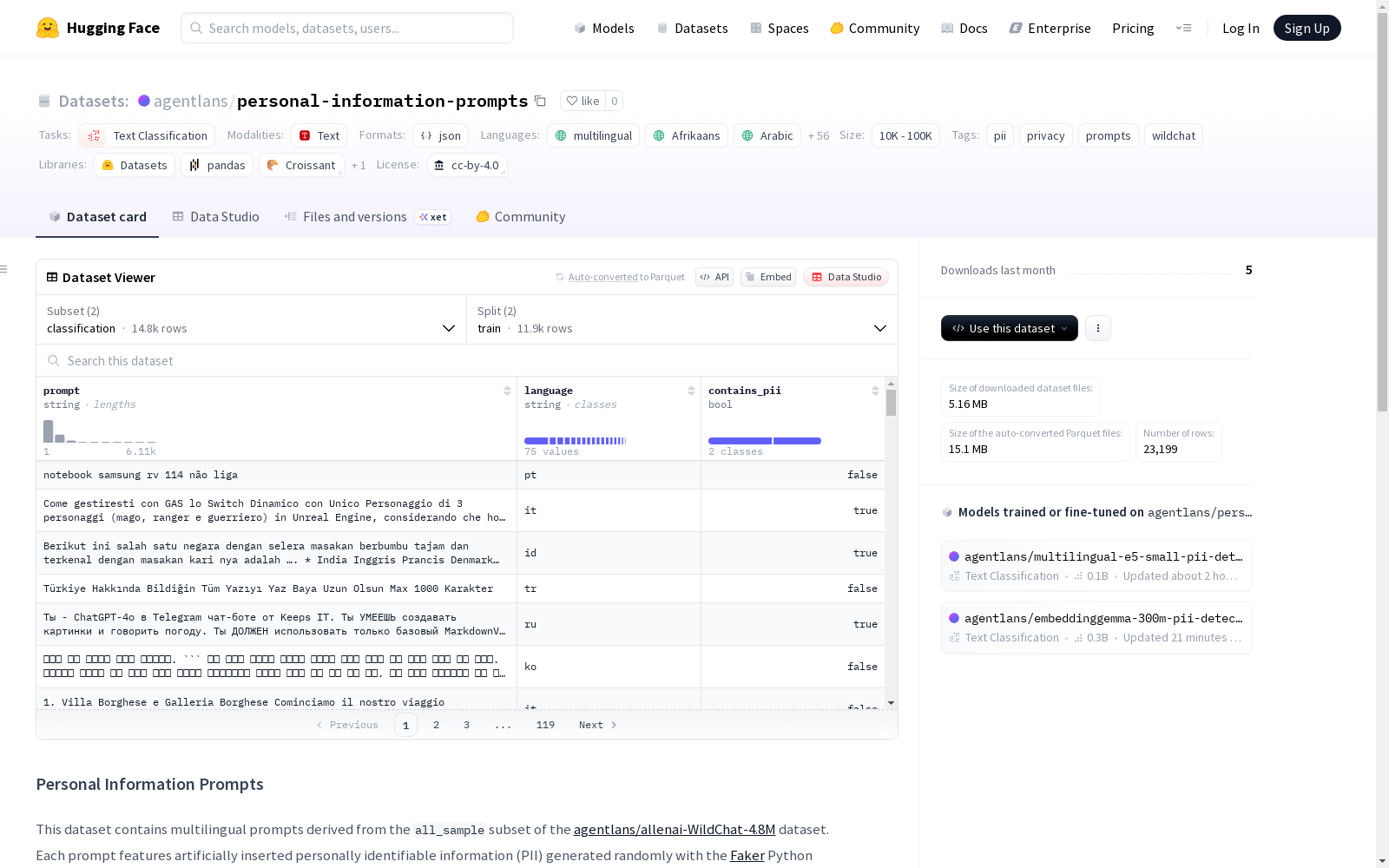
这个数据集包含了从 WildChat 数据集的 all_sample 子集中提取并重写为包含人工插入的个人识别信息(PII)的多语言提示。每个提示都使用 Faker Python 包随机生成不同区域的 PII,并使用 google/gemma-3-12b-it 模型进行重写。数据集分为两个配置:classification 和 customized_prompts,前者是从后者派生并分为训练和测试数据。
This dataset comprises multilingual prompts extracted and rewritten from the all_sample subset of the WildChat dataset, which incorporate manually inserted Personally Identifiable Information (PII). For each prompt, regionally diverse PII is randomly generated using the Faker Python package, and the prompts are rewritten via the google/gemma-3-12b-it model. The dataset is divided into two configurations: classification and customized_prompts. The former is derived from the latter and split into training and test subsets.
Personal Information Prompts 数据集概述
数据集基本信息
- 许可证: Creative Commons Attribution 4.0
- 任务类别: 文本分类
- 标签: PII、隐私、提示词、WildChat
- 语言: 多语言(支持65种语言)
数据来源
基于agentlans/allenai-WildChat-4.8M数据集的all_sample子集构建
数据生成方法
- 使用Faker Python包为不同地区随机生成人工可识别信息(PII)
- 使用google/gemma-3-12b-it模型将合成个人数据整合到重写的提示词中
配置说明
classification配置
- 数据文件: train.jsonl.zst, test.jsonl.zst
- 数据划分: 80%训练集,20%测试集
- 字段说明:
prompt: 可能包含PII的提示词language: 检测到的提示词语言private: 提示词构建是否使用了PII
customized_prompts配置
- 数据文件: customized_prompts.jsonl.zst
- 字段说明:
prompt: 包含人工个人数据的提示词文本pii: 用于生成的PII字典base_prompt: WildChat数据集中的原始提示词pii_locale: 生成PII使用的地区设置prompt_language: 重写提示词的语言(使用FastText确定)
局限性
- 除基础提示词外,所有信息均为随机生成
- 不适合用于提取PII,部分PII以异常方式嵌入到外语文本中
- 并非所有PII都被整合到提示词中