lytang/MeetingBank-transcript
收藏Hugging Face2023-07-17 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/lytang/MeetingBank-transcript
下载链接
链接失效反馈官方服务:
资源简介:
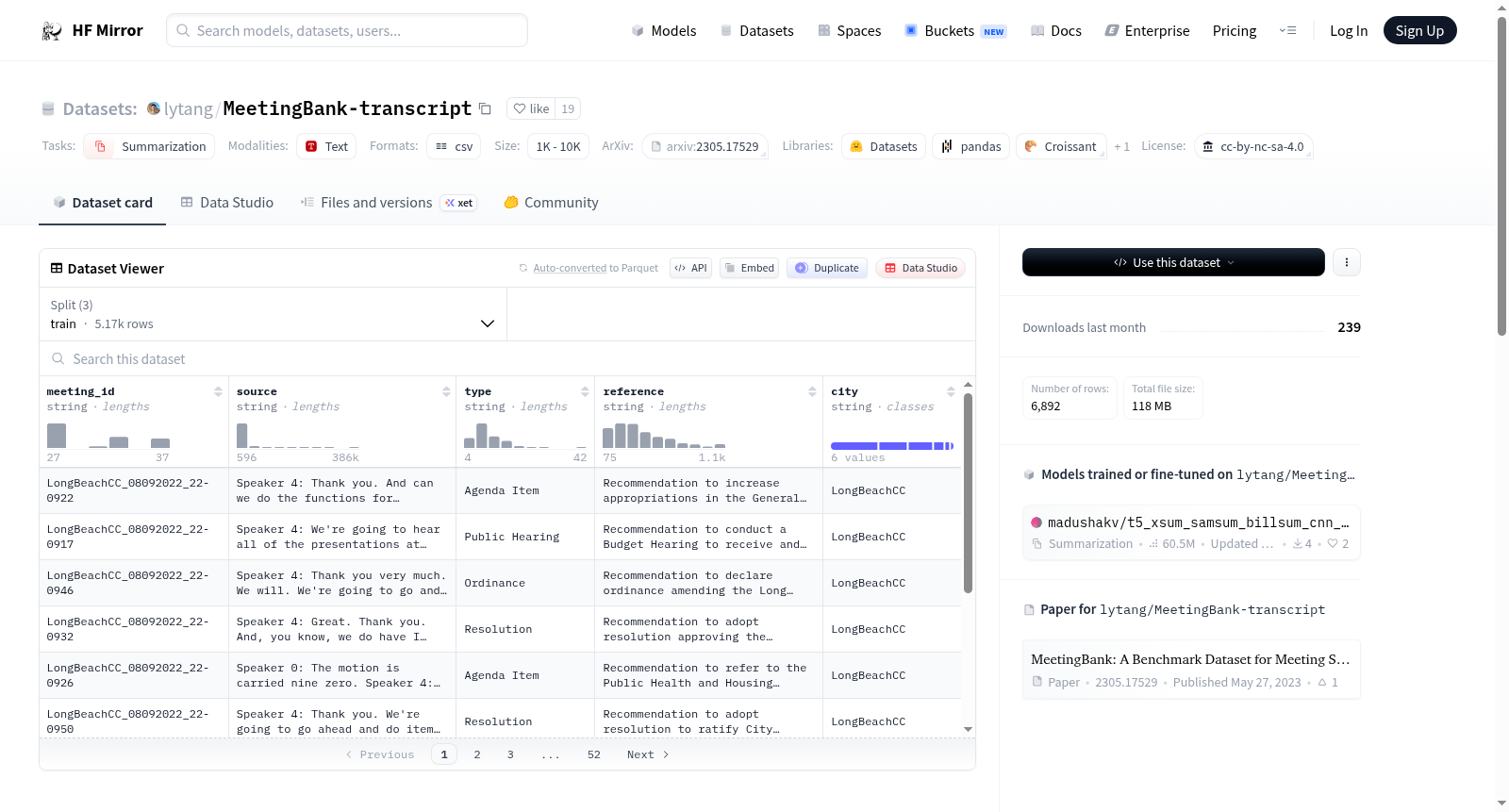
该数据集包含来自MeetingBank数据集的转录文本,MeetingBank是一个来自美国6个主要城市市议会的基准数据集,用于补充现有数据集。它包含1,366次会议,超过3,579小时的视频,以及会议记录、议程和其他元数据的PDF文档。平均每次议会会议时长为2.6小时,转录文本包含超过28,000个标记,为会议摘要和从会议视频中提取结构提供了有价值的测试平台。数据集还包含6,892个分段级别的摘要实例,用于训练和评估性能。
This dataset includes transcripts sourced from the MeetingBank benchmark dataset, which comprises city council meetings from six major U.S. cities and is developed to complement existing datasets. It contains 1,366 meetings, over 3,579 hours of video, as well as PDF documents of meeting minutes, agendas and other metadata. The average duration of each city council meeting is 2.6 hours, and the transcripts contain more than 28,000 tokens, serving as a valuable testbed for meeting summarization and structural extraction from meeting videos. Additionally, the dataset includes 6,892 segment-level summary instances for training and performance evaluation.
提供机构:
lytang
原始信息汇总
数据集概述
- 来源: 该数据集由MeetingBank提供,包含来自美国6个主要城市市议会的会议记录。
- 内容: 数据集包含1,366次会议的视频和音频记录,总时长超过3,579小时。此外,还包括会议的文字记录、PDF格式的会议纪要和议程,以及其他元数据。
- 规模: 平均每次会议时长2.6小时,文字记录包含超过28,000个词。
- 用途: 数据集特别适用于会议摘要生成和从会议视频中提取结构信息的研究。
- 训练实例: 包含6,892个段落级别的摘要实例,用于训练和评估性能。
数据集资源
- 音频文件: 每个会议的音频文件单独托管在HuggingFace。
- 文字记录: 会议文字记录托管在HuggingFace。
- 其他资源: 包括会议音频、文字记录、MeetingBank主JSON文件、6个系统的摘要和人工标注,均托管在Zenodo。
引用信息
- 论文: 使用此数据集的研究应引用论文MeetingBank: A Benchmark Dataset for Meeting Summarization。
- 作者: Yebowen Hu, Tim Ganter, Hanieh Deilamsalehy, Franck Dernoncourt, Hassan Foroosh, Fei Liu。
- 会议: 第61届计算语言学协会年会(ACL’23),多伦多,加拿大。
许可证
- 许可证: 数据集遵循CC-BY-NC-SA-4.0许可证。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,会议摘要任务对高质量数据集的需求日益增长。MeetingBank-transcript数据集源自美国六大主要城市的市政会议记录,其构建过程体现了严谨的学术规范。研究团队从公开的市政会议视频中提取了长达3,579小时的原始素材,通过专业转录技术将其转化为文本数据。这些转录文本与会议纪要、议程等PDF文档进行对齐和标注,形成了包含6,892个片段级摘要实例的结构化语料库,每个会议平均包含2.6小时内容及超过2.8万词元的转录文本,为会议摘要研究提供了坚实的实证基础。
特点
作为会议摘要领域的重要资源,该数据集展现出多维度特征。其核心价值在于大规模真实场景覆盖,1,366场市政会议构成了丰富的语言现象样本库。数据呈现多层次结构特性,既包含完整的会议转录文本,又提供片段级摘要标注,支持不同粒度的研究需求。跨模态关联设计尤为突出,文本转录与原始视频、音频及会议文档形成立体化数据网络,为多模态分析创造了条件。长达数千小时的时序对话数据,更对模型的长文本理解和信息整合能力提出了独特挑战。
使用方法
针对会议摘要研究的具体实践,该数据集提供了清晰的使用路径。研究者可通过HuggingFace平台直接获取文本转录数据,配合Zenodo存储的摘要标注和元数据文件进行联合分析。官方提供的MeetingBank_Utils工具包包含数据处理脚本,支持从原始转录到摘要生成的完整流程。典型应用场景包括训练端到端摘要模型、评估不同摘要系统的性能差异,以及探索会议对话的结构化特征。多模态研究者还可结合音频数据集进行跨模态对齐实验,深入挖掘语音与文本的互补信息。
背景与挑战
背景概述
在自然语言处理领域,会议摘要作为一项复杂的任务,长期面临数据稀缺与质量参差的困境。为应对这一挑战,MeetingBank数据集应运而生,由Yebowen Hu等研究人员于2023年构建,并发表于计算语言学协会年会。该数据集源自美国六大主要城市的市政会议记录,涵盖了1366场会议、超过3579小时的视频及相应文本转录,平均每场会议时长达2.6小时,转录文本包含逾2.8万词元。其核心研究问题聚焦于为会议摘要系统提供大规模、结构化的评测基准,通过提供6892个片段级摘要实例,显著推动了自动摘要技术在长文档、多模态场景下的发展,对提升会议信息提取效率具有深远影响。
当前挑战
会议摘要领域固有的挑战在于处理冗长、多轮对话的复杂语义结构,以及从嘈杂的语音转录中提取关键信息。MeetingBank数据集构建过程中,研究人员需克服多模态数据对齐的困难,包括将音频、视频、文本转录及会议文件进行精确同步。此外,市政会议涉及专业术语与多样化的发言风格,标注高质量摘要需要大量人工参与,确保语义连贯性与事实准确性。这些挑战使得该数据集成为检验摘要模型鲁棒性与泛化能力的重要试金石。
常用场景
经典使用场景
在自然语言处理领域,会议摘要生成是提升信息处理效率的关键任务。MeetingBank-transcript数据集以其源自美国六大城市市政会议的真实转录文本,为研究者提供了大规模、长序列的对话数据。该数据集最经典的使用场景在于训练和评估自动会议摘要模型,其平均每场会议转录包含超过28,000个标记,能够有效模拟现实世界中冗长、多话题交织的会议环境,推动摘要系统在长文档理解和信息压缩方面的性能突破。
衍生相关工作
围绕MeetingBank-transcript数据集,已衍生出多项经典研究工作。例如,原始论文中提出的基准评估框架为后续摘要模型比较提供了标准。此外,研究者利用其长对话特性开发了分层注意力机制和话题分割算法,以更好地处理会议中的多轮交互。这些工作不仅拓展了数据集的应用维度,也为会议摘要领域的模型创新奠定了数据基础。
数据集最近研究
最新研究方向
在自然语言处理领域,会议摘要作为一项关键任务,旨在从冗长的对话中提取核心信息。基于lytang/MeetingBank-transcript数据集,当前研究聚焦于开发能够处理长文档和多模态输入的摘要模型。前沿探索涉及利用大型语言模型进行零样本或小样本学习,以提升摘要的连贯性和信息密度。同时,结合音频和文本的多模态方法成为热点,通过融合语音特征与转录文本,增强对会议语境和发言人情感的理解。该数据集的大规模、高复杂性特性,为评估模型在真实场景中的鲁棒性提供了重要基准,推动了会议自动化处理技术的发展,对智能办公和决策支持系统具有深远影响。
以上内容由遇见数据集搜集并总结生成


