Personalized Driving Dataset (PDD)
收藏arXiv2026-03-27 更新2026-03-28 收录
下载链接:
https://dmw-cvpr.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
PDD是由加州大学河滨分校和密歇根大学研究团队构建的首个多模态个性化驾驶数据集,采集自30位真实驾驶员在CARLA仿真环境中的驾驶行为。该数据集包含驾驶员档案信息、车辆运动状态、场景感知数据以及专家参考速度等丰富内容,覆盖超车、汇流、交叉路口等20种典型驾驶场景。数据通过标准化问卷和Logitech方向盘设备采集,重点捕捉不同驾驶员在相似情境下的个性化决策差异。该数据集为开发人本导向的自动驾驶模型提供了重要基础,可用于研究驾驶风格建模、个性化策略学习等方向。
PDD is the first multimodal personalized driving dataset constructed by research teams from the University of California, Riverside and the University of Michigan, which is collected from the driving behaviors of 30 real drivers in the CARLA simulation environment. This dataset contains rich contents including driver profile information, vehicle motion states, scene perception data, expert reference speeds and more, covering 20 typical driving scenarios such as overtaking, merging, and intersections. The data is collected via standardized questionnaires and Logitech steering wheel devices, focusing on capturing the personalized decision-making differences among different drivers in similar scenarios. This dataset provides an important foundation for developing human-centric autonomous driving models, and can be used for research directions such as driving style modeling and personalized strategy learning.
提供机构:
加州大学河滨分校; 密歇根大学
创建时间:
2026-03-27
原始信息汇总
Drive My Way: Preference Alignment of Vision-Language-Action Model for Personalized Driving
数据集基本信息
- 数据集名称:Personalized Driving Dataset (PDD)
- 论文标题:Drive My Way: Preference Alignment of Vision-Language-Action Model for Personalized Driving
- 会议/年份:CVPR 2026
- 作者机构:University of California, Riverside; University of Michigan
- 对应作者:Jiachen Li
- 实验室:Trustworthy Autonomous Systems Laboratory (TASL)
- 资源链接:
- 论文:https://arxiv.org/abs/2603.25740
- 代码:页面中标注有“Code”链接(未提供具体URL)
- 数据集下载:页面中标注为“Download PDD (Coming Soon)”
数据集概述与目标
- 核心问题:解决现有端到端自动驾驶系统要么优化通用目标,要么依赖固定的驾驶模式,缺乏适应个体偏好或理解自然语言意图的能力。
- 核心思想:Drive My Way (DMW) 是一个个性化的视觉-语言-动作驾驶框架,旨在与用户的长期驾驶习惯保持一致,并适应实时用户指令。
- 主要目标:学习反映个体和独特驾驶行为的模型,使其能够根据长期偏好和实时指令生成个性化、可识别的驾驶行为。
数据集内容与特点
- 数据内容:在CARLA模拟器中,使用方向盘设置收集的真实人类驾驶演示,涵盖多样化场景。
- 数据关联:每位驾驶员都与结构化的档案信息相关联。
- 数据用途:用于学习用户嵌入,该嵌入从驾驶员档案和历史驾驶行为中提取,以在规划过程中调节策略。
方法框架
- 长期偏好编码器:从驾驶员档案中学习用户嵌入,使用对比目标将结构化驾驶员档案与历史驾驶行为对齐,确保学习到的嵌入反映行为模式并保持驾驶员间的多样性。
- 基于GRPO的偏好对齐:采用具有风格感知奖励的组相对策略优化来对齐策略。残差解码器鼓励策略采样多样且合理的驾驶行为。奖励适应弥合了语言中细微偏好与动态风格奖励之间的差距。
评估与验证
- 评估基准:在Bench2Drive基准上进行闭环评估。
- 评估结果:
- DMW在风格指令适应方面有所改进。
- 用户研究表明,其生成的驾驶行为可被识别为每位驾驶员自身的风格。
- 用户研究:
- 五位评估者评估生成轨迹与预期指令的一致性。DMW在激进指令下表现出更高的速度、更短的车头时距和更果断的加速,而在保守指令下则产生更平滑的控制行为和更大的安全边际。
- 十位评估者评估模型生成行为与每位驾驶员驾驶模式的相似性。评估者一致认可反映了相应驾驶员习惯的驾驶行为,表明用户嵌入从档案中捕获了语义上下文。
关键结论
- DMW能够适应不同场景下各种风格的实时指令。
- 当以学习到的用户嵌入为条件时,DMW在不同场景和指令风格下表现出一致的运动模式。风格指令进一步提供短期适应,将驾驶行为转向预期偏好。
- 个性化是以人为中心的自动驾驶的关键能力。
搜集汇总
数据集介绍
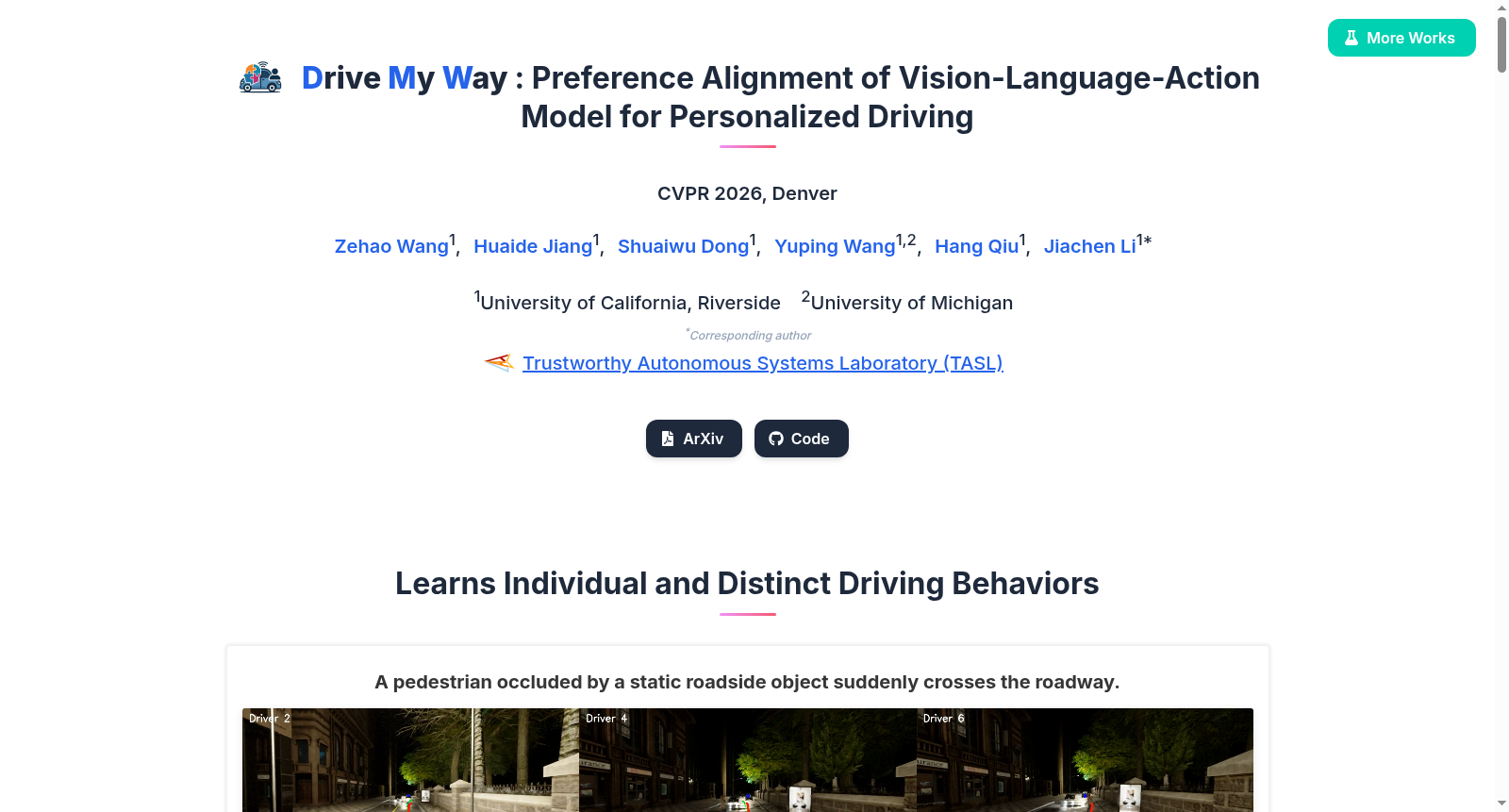
构建方式
在自动驾驶领域,个性化驾驶行为建模面临数据稀缺的挑战。为应对这一挑战,个性化驾驶数据集(PDD)的构建采用了系统化采集策略。该数据集招募了三十名具有不同背景和驾驶经验的真实驾驶员,在CARLA仿真环境中完成了二十种涵盖超车、并线、交叉路口通行及行人穿越等四类典型场景的标准化驾驶任务。数据采集过程中,每位参与者首先通过结构化问卷提供人口统计信息、驾驶历史及典型驾驶目的等语义化背景资料。驾驶行为数据则通过罗技G系列方向盘与踏板设备记录,同步采集了自车运动状态、周围交通参与者感知信息以及由PDM-Lite生成的专家目标速度作为行为风格的密集描述符。这种多模态数据采集框架为驾驶偏好建模提供了丰富且具有行为敏感性的基础。
特点
个性化驾驶数据集(PDD)的核心特征在于其深度融合了语义化用户画像与多维度驾驶行为日志。与以往依赖合成指令或启发式风格标签的数据集不同,PDD通过结构化问卷捕获了驾驶员的长期习惯与背景,并将其与高保真仿真环境中的实时交互行为相关联。数据集涵盖了超车、并线等二十种高度交互的安全关键场景,确保了行为模式的多样性与真实性。尤为突出的是,PDD不仅记录了原始传感器输入与控制信号,还提供了专家目标速度作为基准,使得不同驾驶员在相似情境下的行为偏差能够被量化分析,从而为建模隐式且演变的驾驶倾向提供了可靠依据。
使用方法
该数据集主要服务于个性化自动驾驶策略的开发与评估。研究人员可利用PDD学习能够编码长期驾驶行为的用户嵌入表示,具体方法是通过对比学习机制,在由驾驶员画像和实际驾驶轨迹所构成的共享潜在空间中进行对齐。在此基础上,可构建条件化策略模型,将学习到的用户嵌入与实时自然语言指令相结合,生成符合个体偏好与短期意图的驾驶动作。数据集的评估通常依托于Bench2Drive等闭环驾驶基准测试,通过驾驶分数、成功率及个性化对齐分数等指标,系统衡量模型在保持安全与效率的同时,对特定驾驶员行为风格的复现与适应能力。
背景与挑战
背景概述
个性化驾驶数据集(Personalized Driving Dataset, PDD)由加州大学河滨分校与密歇根大学的研究团队于2026年构建,旨在解决端到端自动驾驶系统中长期存在的个性化缺失问题。该数据集的核心研究聚焦于如何使自动驾驶系统不仅遵循通用安全与效率目标,更能适应不同驾驶者的长期习惯与实时意图。通过采集三十名真实驾驶者在CARLA仿真环境中二十种复杂交通场景下的多模态数据,包括驾驶轨迹、环境感知与结构化个人档案,PDD为开发以人为中心的驾驶模型提供了首个系统性的基准。其创新性在于将视觉-语言-动作模型与个性化偏好对齐,推动了自动驾驶从标准化向人性化范式的演进,对提升用户信任与乘坐体验具有深远影响。
当前挑战
PDD所应对的核心领域挑战在于实现驾驶行为的个性化建模,即如何使自动驾驶系统精准捕捉并复现不同个体在加速、制动、超车等操作中的细微差异,同时理解自然语言指令以适配实时场景需求。构建过程中的主要挑战包括:其一,数据采集需在高度交互的仿真场景中同步记录多维度信息,涵盖驾驶行为、环境状态与个人背景,确保数据的真实性与一致性;其二,驾驶风格标注依赖对比学习与用户嵌入技术,而非启发式标签,以捕捉隐性的长期驾驶倾向;其三,评估体系需兼顾封闭环路的驾驶性能与个性化对齐度,设计合理的量化指标与用户研究方案,以验证模型在安全与风格表达间的平衡能力。
常用场景
经典使用场景
在自动驾驶研究领域,个性化驾驶数据集(PDD)为探索人类驾驶行为的个体差异性提供了关键数据支撑。该数据集通过采集三十名真实驾驶员在CARLA模拟器中二十种复杂交通场景下的驾驶轨迹与用户画像,构建了多模态的驾驶行为档案。其经典使用场景集中于训练和评估端到端的个性化自动驾驶模型,例如Drive My Way框架,该框架利用PDD学习用户嵌入向量,以对齐长期驾驶习惯并适应实时自然语言指令,从而在封闭环路的Bench2Drive基准测试中验证模型在超车、并线、紧急制动等动态情境下的个性化适应能力。
解决学术问题
个性化驾驶数据集(PDD)致力于解决自动驾驶研究中驾驶行为同质化与用户偏好忽视的核心学术问题。传统端到端自动驾驶系统往往优化通用安全与效率目标,缺乏对个体驾驶风格(如激进型、保守型)的建模能力。PDD通过整合驾驶员背景信息、历史轨迹与实时场景数据,为学习用户特定的长期偏好提供了结构化基础。该数据集支持对比学习等机制,使模型能够从多驾驶员行为中区分细微差异,从而推动个性化驾驶策略的生成,弥补了现有方法在语义化用户画像与行为对齐方面的不足,为人本中心的自动驾驶研究开辟了新路径。
衍生相关工作
个性化驾驶数据集(PDD)催生了一系列围绕个性化自动驾驶的衍生研究工作。以PDD为基础的Drive My Way框架首次将视觉-语言-动作模型与用户嵌入学习相结合,启发了后续如StyleDrive等风格感知驾驶模型的改进。同时,PDD的多模态特性促进了对比学习在驾驶行为对齐中的应用,相关方法被扩展至多目标强化学习系统中,以实现运行时偏好权重的动态调整。此外,PDD中自然语言指令与驾驶场景的配对数据,为大型语言模型在复杂交通情境下的指令解释与决策生成提供了验证平台,推动了Talk2Drive等语言驱动个性化系统的演进。
以上内容由遇见数据集搜集并总结生成


