ViMo dataset
收藏arXiv2025-03-11 更新2025-03-13 收录
下载链接:
https://jackyu6.github.io/HERO
下载链接
链接失效反馈官方服务:
资源简介:
ViMo数据集是由中国科学技术大学采集的视频-动作对数据集,包含人类-人类、人类-动物和人类-场景交互的广泛类别,共涉及32个子类别。该数据集旨在支持从RGB视频生成3D人类反应的任务,为模型训练和评估提供了测试平台。
The ViMo dataset is a video-action pair dataset collected by the University of Science and Technology of China. It covers a wide range of categories including human-human, human-animal and human-scene interactions, involving a total of 32 subcategories. This dataset is designed to support the task of generating 3D human reactions from RGB videos, providing a testbed for model training and evaluation.
提供机构:
中国科学技术大学
创建时间:
2025-03-11
搜集汇总
数据集介绍
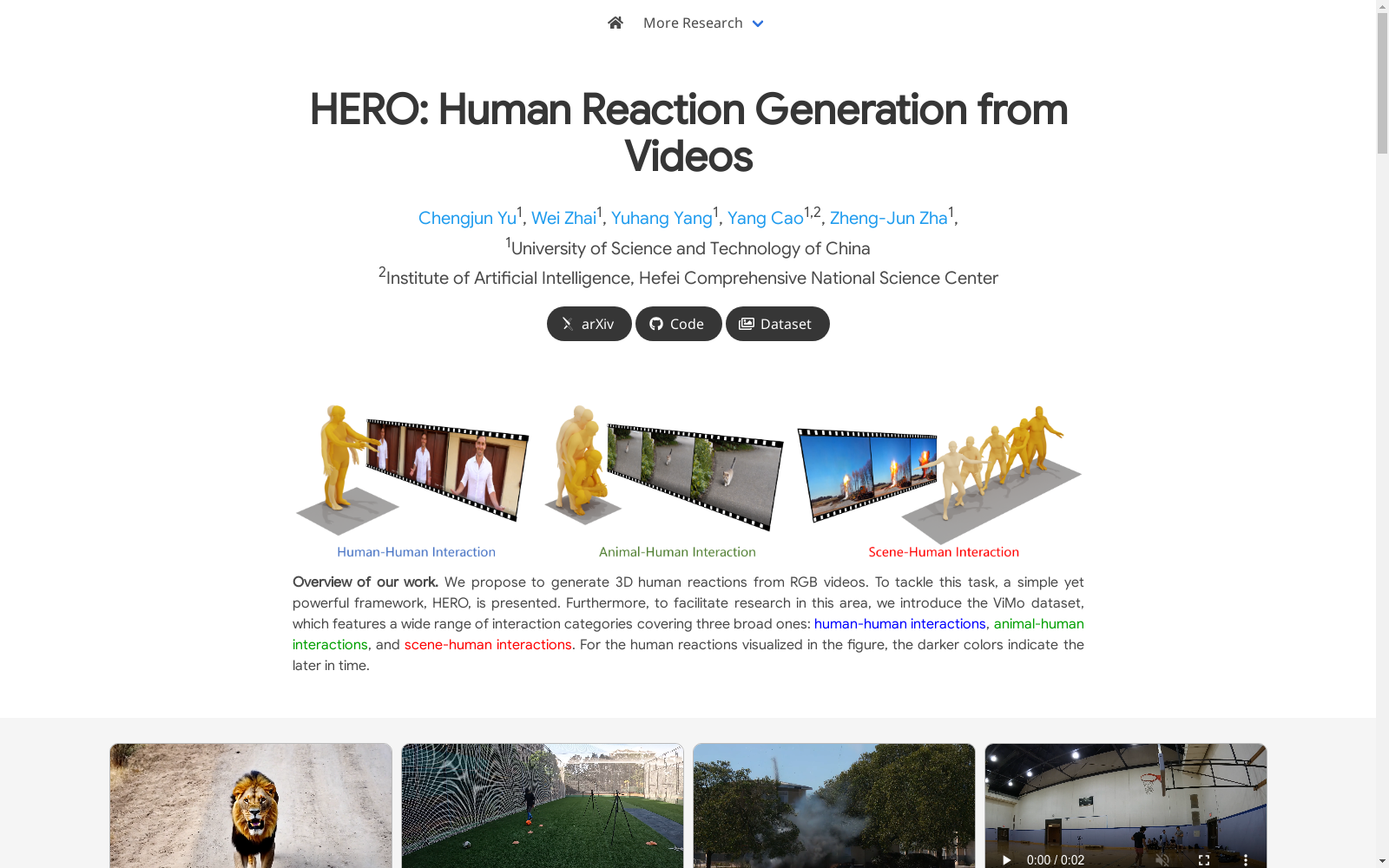
构建方式
ViMo数据集的构建是通过收集和合成视频-运动对来完成的。首先,从现有的公开数据集中精心挑选了1,335个视频片段,这些视频涵盖了广泛的人类-人类交互类别。为了获取更难以找到的视频内容,如动物-人类交互和场景-人类交互,研究人员使用了高性能的文本到视频生成模型来生成视频,并手动筛选出高质量的视频。此外,还利用了现有的运动数据集和文本到运动生成模型MoMask来生成所需的数据。所有收集的视频和运动数据都经过处理后,形成了包含3,500个视频-运动对的ViMo数据集,这些数据对涵盖了人类、动物和场景的交互内容。
使用方法
ViMo数据集的使用方法包括以下几个方面:首先,可以将数据集用于训练和评估生成3D人类反应的模型。其次,数据集可以用于研究人类交互的规律和特点。此外,数据集还可以用于开发和应用交互式人工智能技术,如虚拟现实、增强现实、动画、游戏、人机交互和具身人工智能等。
背景与挑战
背景概述
ViMo数据集,全称为Video-Motion数据集,由中国科学院科学技术大学和合肥综合性国家科学中心人工智能研究所的Chengjun Yu、Wei Zhai、Yuhang Yang、Yang Cao和Zheng-Jun Zha等人于2025年创建。该数据集旨在支持从RGB视频中生成3D人体反应的研究。HERO框架被提出以应对这一任务,该框架从视频中提取交互意图,并使用该意图来指导反应的合成。ViMo数据集包含广泛交互类别的视频-运动数据对,涵盖了人-人交互、动物-人交互和场景-人交互三大类别,为交互式人工智能的研究提供了宝贵的资源。
当前挑战
ViMo数据集和相关研究面临的挑战包括:1) 从视频中提取交互意图的挑战,这要求模型能够理解并识别视频中复杂的交互场景和情感信息;2) 构建过程中遇到的挑战,例如如何有效地利用视频的动态属性,以及如何在不同的交互类别中保持生成的反应的多样性和合理性。此外,数据集的构建也面临着如何平衡数据质量和数量的挑战,以确保模型能够在多样化的场景中表现出良好的泛化能力。
常用场景
经典使用场景
ViMo数据集在交互式人工智能领域具有广泛的应用前景,特别是在虚拟现实、增强现实、动画、游戏、人机交互和具身人工智能等领域。通过生成基于RGB视频的3D人类反应,ViMo数据集可以帮助计算机更好地理解并响应社会线索和环境因素,为非玩家角色(NPCs)注入生命力,并使类人机器人能够像人类一样理解并响应周围的世界。
解决学术问题
ViMo数据集解决了传统人类反应生成任务的两个主要限制:交互类别受限和缺乏情感信息。通过使用RGB视频作为输入,ViMo数据集涵盖了更广泛的交互类别,包括人-人交互、动物-人交互和场景-人交互,并自然地包含了可能反映主体情感的动作和面部表情。此外,ViMo数据集还提供了丰富的视频-运动对,为模型训练和评估提供了有力支持。
实际应用
ViMo数据集的实际应用场景包括但不限于:虚拟现实和增强现实中的交互式角色生成、动画和游戏中的自然人类反应生成、人机交互系统中的情感理解和响应、具身人工智能中的环境感知和交互。此外,ViMo数据集还可以用于研究人类行为和情感,以及开发更先进的交互式人工智能系统。
数据集最近研究
最新研究方向
ViMo数据集的最新研究方向主要集中在从RGB视频中生成3D人类反应。HERO框架考虑了视频的全局和帧级局部表示,以提取交互意图,并使用这些信息来指导反应的合成。此外,ViMo数据集包含了广泛的人与人、人与动物以及人与场景交互类别,为该领域的研究提供了丰富的数据支持。这项研究有助于推动交互式人工智能的发展,使得非玩家角色(NPC)更加生动,并使类人机器人能够以类似人类的方式理解和响应社交和环境因素。
相关研究论文
- 1HERO: Human Reaction Generation from Videos中国科学技术大学 · 2025年
以上内容由遇见数据集搜集并总结生成


