CaMiT
收藏arXiv2025-10-21 更新2025-10-23 收录
下载链接:
https://huggingface.co/datasets/fredericlin/CaMiT
下载链接
链接失效反馈官方服务:
资源简介:
CaMiT是一个时间感知的汽车模型数据集,用于分类和生成。该数据集包括190种汽车模型(2007-2023年)的787K个标注样本和5.1M个未标注样本(2005-2023年),支持监督学习和自监督学习。数据集通过结合视觉语言模型(VLMs)和监督模型,实现了半自动化的标注流程,减少了人工标注的工作量。CaMiT在三个分类场景中评估了时间数据偏移的影响,并提出了两种缓解策略:时间增量预训练和时间增量分类器学习。此外,CaMiT还引入了时间感知图像生成任务,通过在训练过程中一致地使用时间元数据,使得生成的图像更加真实。
CaMiT is a time-aware automotive model dataset tailored for classification and generation tasks. This dataset includes 787K labeled samples and 5.1M unlabeled samples, covering 190 car models from 2007 to 2023 for labeled samples and 2005 to 2023 for unlabeled samples, supporting both supervised learning and self-supervised learning. It adopts a semi-automated annotation pipeline by combining vision-language models (VLMs) and supervised models, which reduces the workload of manual annotation. CaMiT evaluates the impact of temporal data drift across three classification scenarios, and proposes two mitigation strategies: temporal incremental pre-training and temporal incremental classifier learning. Additionally, CaMiT introduces a time-aware image generation task, which consistently uses temporal metadata during training to produce more realistic generated images.
提供机构:
法国巴黎萨克雷大学、法国原子能和替代能源委员会、法国信息与自动化研究所、法国巴黎萨克雷大学
创建时间:
2025-10-20
原始信息汇总
CaMiT数据集概述
数据集基本信息
- 名称: CaMiT (Car Models in Time)
- 许可证: CC BY-NC-SA 4.0(仅限非商业研究用途)
- 数据量: 总大小1.54 GB,下载大小809.5 MB
数据构成
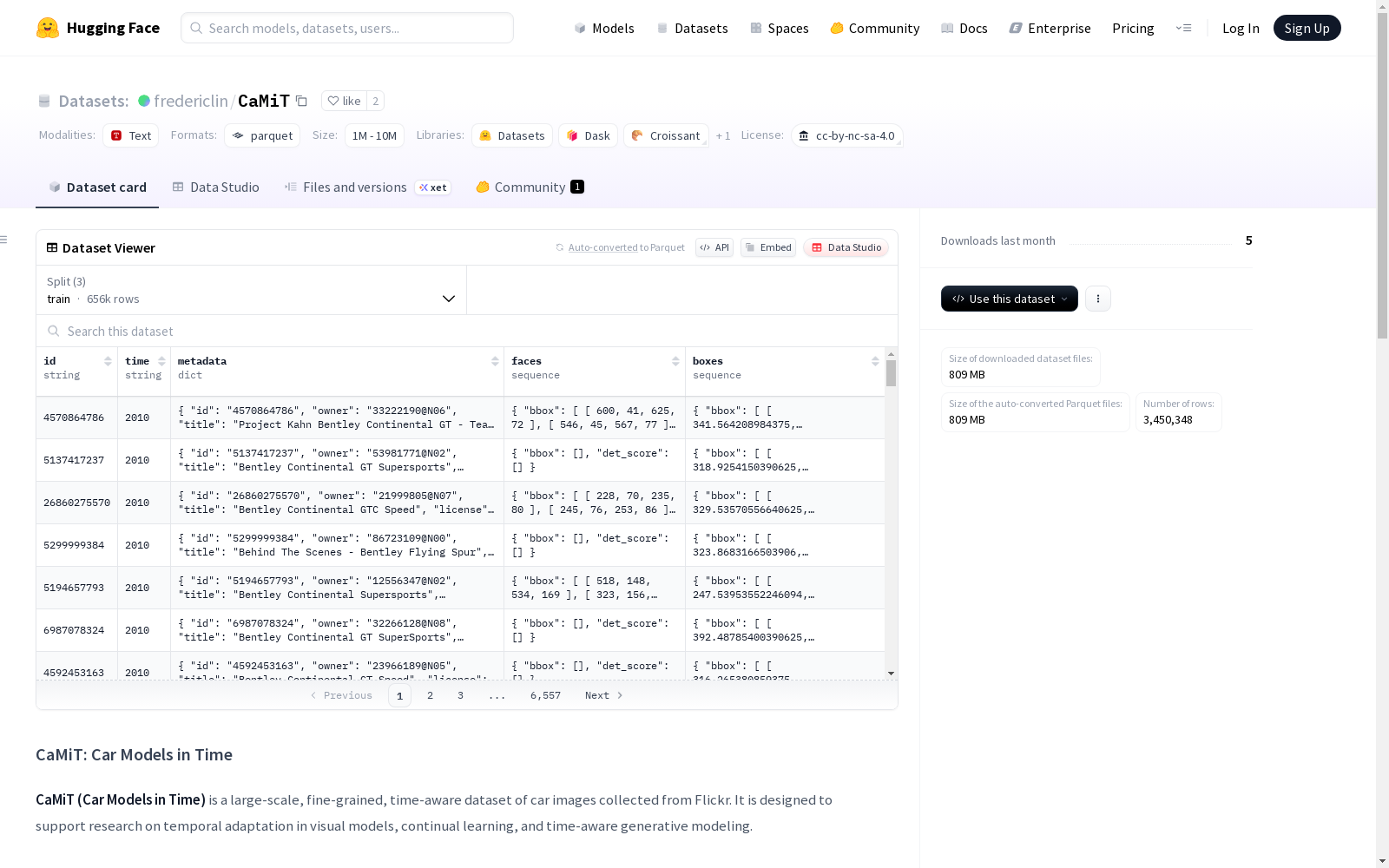
数据划分
- 训练集: 655,681个样本,294.9 MB
- 测试集: 84,830个样本,38.7 MB
- 预训练集: 2,709,837个样本,1.21 GB
数据特征
- 标识字段: id(字符串)
- 时间字段: time(字符串)
- 元数据字段:
- 图像ID、所有者、标题、许可证
- 上传日期、标签、图像URL
- 图像尺寸信息
检测特征
- 人脸检测: 边界框坐标和检测分数
- 车辆检测:
- 边界框坐标和YOLO检测分数
- 车辆类别信息
- GPT模型概率评估
- 学生模型评分(GPT和Qwen)
数据集特点
规模与覆盖
- 标注子集: 787,000个样本,覆盖190个车型,时间跨度2007-2023年
- 无标注预训练子集: 510万个样本,时间跨度2005-2023年
数据来源
- 从Flickr收集的汽车图像数据集
- 仅包含图像元数据和链接,不直接分发图像内容
- 遵循LAION和DataComp数据集的版权合规要求
支持的研究任务
- 时间感知细粒度分类
- 时间增量持续学习
- 域内静态和增量预训练
- 时间感知图像生成
典型应用场景
- 评估表征随时间漂移
- 训练跨时间泛化的分类器
- 研究模型在不同年份间的性能退化和适应
- 基于时间上下文的生成模型条件化
相关资源
- 预计算图像嵌入数据集:https://huggingface.co/datasets/fredericlin/CaMiT-embeddings
搜集汇总
数据集介绍
构建方式
在构建CaMiT数据集时,研究团队遵循了精细化的数据收集与处理流程,以捕捉汽车模型在时间维度上的视觉演变。他们利用Flickr API进行图像采集,通过查询汽车子类型、品牌和模型,并结合内置时间过滤器,确保了数据覆盖2005年至2023年的长期跨度。初始收集的750万张候选图像经过多阶段过滤,包括基于CLIP嵌入的重复去除、YOLOv11x的汽车实例检测、Qwen2.5-7B的内容筛选以及SAM 2的重叠边界框消除,最终得到587万张汽车裁剪图像。标注过程采用半自动化流水线,整合了Qwen2.5-7B和GPT-4o等视觉语言模型的零样本分类能力,辅以DeiT监督分类器的微调预测,并通过人工验证设定阈值,确保190个汽车模型的787,000张标注样本达到99.6%的准确率。
特点
CaMiT数据集的核心特点在于其时间感知性和细粒度分类的深度结合。该数据集包含787,000张标注样本和510万张未标注样本,覆盖190个汽车模型在2007年至2023年间的视觉演变,体现了汽车设计随时间的动态变化。其时间元数据允许研究模型在静态预训练、时间增量预训练和分类器学习等场景下的性能演化,例如通过核初始距离分析揭示嵌入空间随年份差异的增大趋势。此外,数据集的类别分布呈现现实不平衡性,平均每模型244个训练实例,且由337,000名独特用户贡献,反映了社会共享视角下的领域多样性。这种设计为研究时间数据偏移和持续学习提供了高度可控的实验环境。
使用方法
CaMiT数据集支持多种时间感知的视觉任务应用。在分类任务中,用户可进行静态预训练以分析时间偏移效应,或采用时间增量预训练更新骨干模型,以及时间增量分类器学习优化分类层,其中RanPAC等方法显著提升跨时间准确率。生成任务中,通过将时间元数据融入训练描述(如“CAR_MODEL in YEAR”),可微调Stable Diffusion等模型,实现时间感知图像生成,提升合成内容的真实性和时间一致性。数据集以图像链接、嵌入和元数据形式分发,确保版权合规,并鼓励用户在持续学习和生成式AI中探索时间动态建模。
背景与挑战
背景概述
CaMiT数据集由巴黎萨克雷大学的研究团队于2025年提出,聚焦于细粒度视觉分类领域中汽车模型随时间演化的动态建模。该数据集收录了2007至2023年间190种汽车模型的78.7万标注样本及2005至2023年的510万未标注样本,通过融合视觉语言模型与半自动标注技术构建。其核心研究在于探索技术制品外观随时间推移产生的分布偏移现象,为持续学习与时间感知模型提供了首个针对细粒度类别的长期观测基准,推动了动态视觉概念建模方法的发展。
当前挑战
在领域问题层面,CaMiT需解决汽车模型因设计迭代导致的视觉特征漂移挑战,具体表现为模型在时间维度前后测试时出现显著性能退化。构建过程中面临多重困难:一是公开源数据的时间元数据不可靠,需依赖Flickr平台进行跨近20年的精准时序采集;二是细粒度标注需要结合VLMs预测与人工验证的混合流程,以平衡标注效率与99.6%的准确率要求;三是数据存在地域不平衡与类别样本量差异,需通过阈值设计保持现实场景的多样性表征。
常用场景
经典使用场景
在细粒度视觉分类研究领域,CaMiT数据集为时间感知模型评估提供了标准化测试平台。该数据集通过构建跨越17年的汽车模型图像序列,支持静态预训练、时间增量预训练和时间增量分类学习三种经典实验范式。研究者可利用其精确的时间标注分析模型在时间维度上的性能退化现象,探索视觉概念演变的建模方法。
解决学术问题
CaMiT有效解决了细粒度视觉类别随时间演变的核心学术问题。通过提供长期时间标注的汽车模型数据,该数据集使研究者能够量化视觉概念漂移对模型性能的影响,并开发时间感知的持续学习算法。其价值在于揭示了专用预训练模型在细粒度分类任务中与通用模型的竞争性表现,为领域自适应研究提供了新的实证基础。
衍生相关工作
CaMiT的发布催生了多个重要的衍生研究方向。在时间增量分类领域,RanPAC和RanDumb等算法通过随机投影技术显著提升了时间泛化能力。在生成模型方面,时间感知图像生成任务探索了如何将时间元数据融入训练过程,改善了生成图像的时间一致性。这些工作共同推动了细粒度时间建模方法学的发展。
以上内容由遇见数据集搜集并总结生成


