Multi-Doc-2025
收藏Hugging Face2026-05-31 更新2026-06-01 收录
下载链接:
https://huggingface.co/datasets/Anonymous-Team-HC-RAG/Multi-Doc-2025
下载链接
链接失效反馈官方服务:
资源简介:
Multi-Doc-2025 是一个基于美国证券交易委员会(SEC)10-K年度报告构建的金融领域问答基准数据集,专门用于评估检索增强生成(RAG)系统和金融问答系统在三种关键推理场景下的能力:跨公司推理、跨年度推理以及文本与表格混合模态推理。该数据集旨在填补现有金融问答基准未能同时覆盖这些现实世界金融分析挑战的空白。数据内容包含 2,327 个问答对,源自 87 家标准普尔 500 指数代表性公司在 2022 至 2024 三个财年的 179 份 10-K 文件,覆盖 12 个全球行业分类标准(GICS)部门。数据被精心划分为五个正交的子集(S1-S5)和三个难度级别(L1-L3),每个样本是一个结构化的 JSON 对象,包含问题、答案、意图、难度、所属子集、相关公司代码、所需年份、行业部门以及一系列布尔标志,用于精确描述问题的证据结构和推理需求。数据集适用于金融问答与 RAG 系统基准测试、多文档金融推理、跨公司与跨年度时序推理、文本-表格混合模态推理、证据支撑生成与幻觉研究以及金融领域自然语言处理和信息检索系统的开发与评估。需要强调的是,数据集基于历史文件构建,不应用于实际投资决策、提供财务建议或推断当前公司表现。
Multi-Doc-2025 is a financial domain question-answering benchmark dataset built on U.S. Securities and Exchange Commission (SEC) 10-K annual reports, specifically designed to evaluate the capabilities of Retrieval-Augmented Generation (RAG) systems and financial QA systems in three key reasoning scenarios: cross-company reasoning, cross-year reasoning, and mixed text-table modal reasoning. The dataset aims to fill the gap in existing financial QA benchmarks that fail to simultaneously cover these real-world financial analysis challenges. The data content consists of 2,327 QA pairs derived from 179 10-K filings of 87 representative S&P 500 companies across three fiscal years from 2022 to 2024, covering 12 Global Industry Classification Standard (GICS) sectors. The data is meticulously divided into five orthogonal subsets (S1-S5) and three difficulty levels (L1-L3). Each sample is a structured JSON object containing question, answer, intent (e.g., calculation, trend, fact, comparison), difficulty, subset, relevant company codes, required years, industry sectors, and a series of boolean flags (e.g., cross-document, cross-year, mixed-modal, requires calculation) to precisely describe the evidence structure and reasoning requirements of the problem. The dataset is suitable for financial QA and RAG system benchmarking, multi-document financial reasoning, cross-company and cross-year temporal reasoning, text-table mixed-modal reasoning, evidence-supported generation and hallucination research, as well as the development and evaluation of financial natural language processing and information retrieval systems. It is emphasized that the dataset is based on historical documents and should not be used for actual investment decisions, providing financial advice, or inferring current company performance.
创建时间:
2026-05-21
原始信息汇总
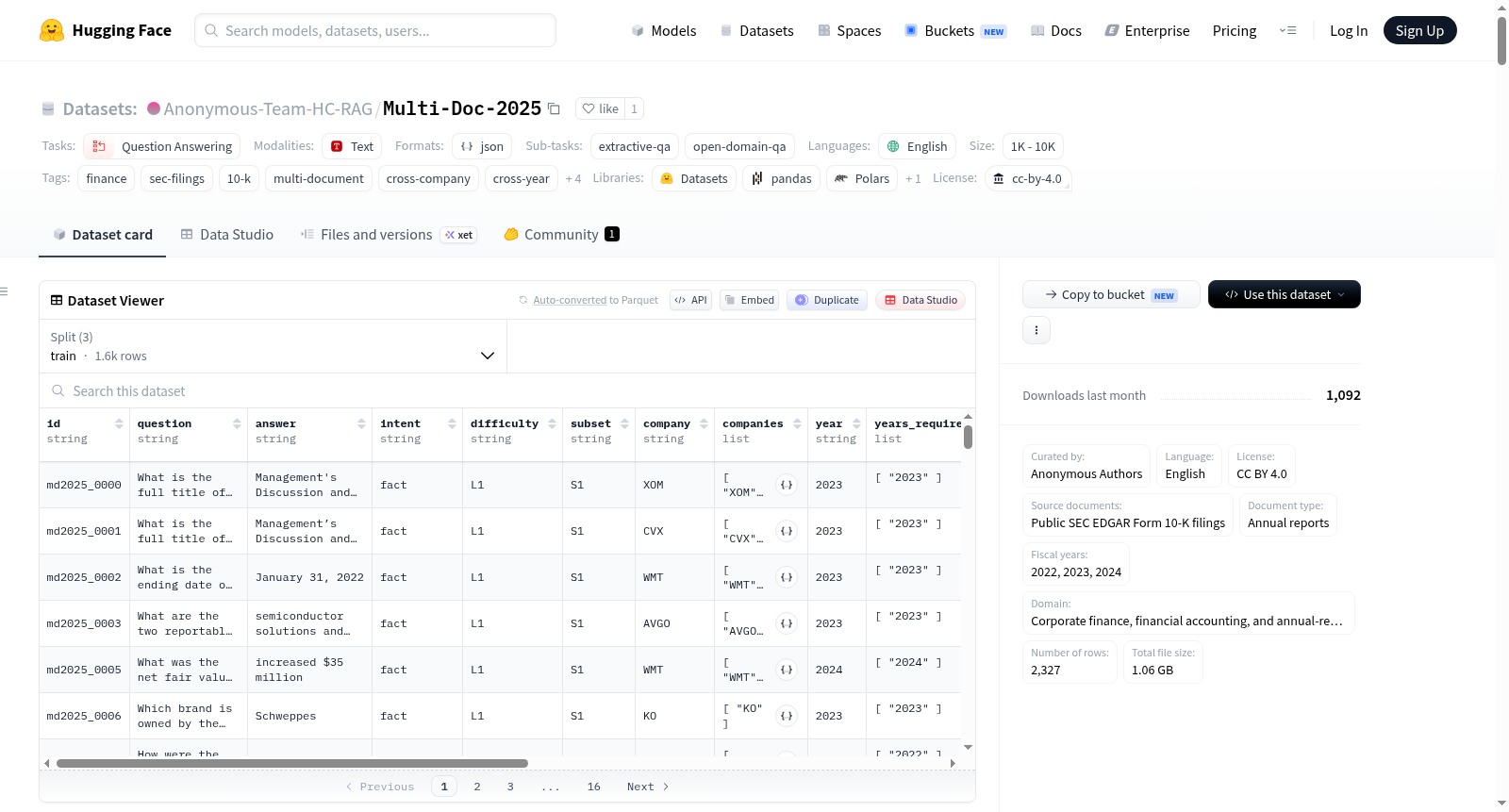
数据集概述:Multi-Doc-2025
Multi-Doc-2025 是一个面向金融领域的问答基准数据集,基于 S&P 500 公司的 SEC Form 10-K 年度报告构建,旨在评估检索增强生成(RAG)和金融问答系统在跨公司、跨年份、以及跨文本与表格混合模态推理方面的能力。
核心特性
- 总规模:包含 2,327 个问答对,源自 179 份 SEC 10-K 文件,覆盖 87 家 S&P 500 代表性公司、12 个 GICS 行业以及 2022、2023、2024 三个财年。
- 数据划分:训练集 1,600 条、验证集 252 条、测试集 475 条,采用 公司不重叠(company-disjoint) 的分割策略。
- 许可协议:CC BY 4.0。
- 任务类型:抽取式问答、开放域问答。
- 语言:英语。
数据子集与难度等级
数据集包含五个正交子集(S1-S5)和三个难度等级(L1-L3),用于分项测试不同的推理能力。
| 子集 | 名称 | 难度 | 数量 | 描述 |
|---|---|---|---|---|
| S1 | 单文档事实/计算 | L1 | 800 | 基于单公司、单年份的文本事实或简单计算问题。 |
| S2 | 单文档表格推理 | L1 | 494 | 基于表格的查询或数值计算问题。 |
| S3 | 跨年份趋势 | L2 | 243 | 同一公司跨三个财年的趋势推理。 |
| S4 | 跨公司比较 | L2 | 668 | 同行业两家公司的比较推理。 |
| S5 | 全交叉 | L3 | 122 | 同时涉及跨公司、跨年份和混合模态的复杂推理。 |
问题意图分布
| 意图 | 数量 | 占比 | 描述 |
|---|---|---|---|
| comparison | 764 | 32.8% | 实体、指标、公司或时期之间的对比。 |
| fact | 672 | 28.9% | 从文本或表格中进行事实检索。 |
| calculation | 622 | 26.7% | 对财务数据进行数值计算。 |
| trend | 269 | 11.6% | 跨财年的时序变化分析。 |
数据结构
每个问答对以 JSON 格式存储,包含以下关键字段:
| 字段 | 类型 | 描述 |
|---|---|---|
id |
string | 唯一标识符,如 md2025_0001。 |
question |
string | 自然语言金融问题。 |
answer |
string | 标准答案。 |
intent |
string | 意图类型(calculation、trend、fact、comparison)。 |
difficulty |
string | 难度等级(L1、L2、L3)。 |
subset |
string | 所属子集(S1 至 S5)。 |
company |
string | 主公司股票代码。 |
companies |
list[string] | 回答问题所需的所有公司股票代码。 |
year |
string | 主要财年。 |
years_required |
list[string] | 回答问题所需的所有财年。 |
sector |
string | 主公司的 GICS 行业。 |
is_cross_doc |
bool | 是否需要两个或以上文件中的证据。 |
is_cross_year |
bool | 是否需要两个或以上财年的证据。 |
is_hybrid_modal |
bool | 是否需要同时使用文本和表格证据。 |
requires_calculation |
bool | 答案是否涉及数值计算。 |
evidence_section |
string | 包含证据的 10-K 章节。 |
评估指标
官方评估报告以下主要指标:
- EM:答案归一化后的精确匹配率。
- F1:基于 token 的 F1 分数。
- Exec-Acc:数值执行准确率(容差 1e-3)。
- Hall-Rate:包含不可验证主张的回答比例。
同时提供按意图、子集和难度划分的切片指标。
数据创建与质量控制
- 来源:所有文档来自 SEC EDGAR 公开的 10-K 文件。
- 生成:问答对由大语言模型根据特定子集提示生成。
- 过滤:经过基于规则的自动过滤,排除元问题、不可回答问题和无效标签。
- 专家审核:由金融领域专家验证答案的事实正确性和标签有效性。
用途与限制
预期用途:金融问答和 RAG 系统基准测试、跨文档/跨时间/混合模态推理评估、证据生成与幻觉研究。
禁止用途:不得用于实际投资决策、金融建议、或推断公司当前表现。数据集仅限学术研究,不构成投资推荐。
搜集汇总
数据集介绍
构建方式
Multi-Doc-2025数据集以美国证券交易委员会(SEC)EDGAR系统中的Form 10-K年度报告为基石,精心选取了来自标普500指数中87家代表性公司的179份文件,覆盖2022至2024三个财年及全部12个GICS行业板块。数据集构建遵循严谨的流水线:首先,利用大型语言模型配合子集特定的提示模板,生成初步的问答候选对;随后,通过基于规则的自动化过滤,剔除元问题、无法回答的样本及标签不一致的条目;最后,由金融领域专家逐一审核剩余样本,确保答案与原始文件的严格一致性和标签的准确性。训练集、验证集与测试集采用公司无重叠的划分策略,避免同一公司出现在多个分片中,从而保障评估的公正性与泛化能力。
特点
该数据集的一大特色在于其多维度的推理维度划分,它包含五个正交子集(S1至S5),系统性地覆盖了单文档事实/计算、单文档表格推理、跨年度趋势分析、跨公司比较以及全交叉复杂推理五种场景。这种设计使得模型在检索增强生成(RAG)任务中的表现可以从难度等级(L1至L3)、推理意图(事实、计算、趋势、比较)以及证据结构(跨文档、跨年份、跨模态)等多个剖面进行细粒度评估。尤为突出的是,该数据集兼具跨公司、跨年份与文表混合推理三大挑战,填补了现有金融问答基准在这些维度上的空白,为评估金融领域大模型的证据溯源与复杂推理能力提供了强有力的诊断工具。
使用方法
使用Multi-Doc-2025数据集进行评测时,研究者可直接加载JSON格式的训练、验证和测试文件。官方评估脚本提供精确匹配(EM)、词级F1分数、数值执行精度(Exec-Acc)以及幻觉率(Hall-Rate)四项核心指标。此外,支持按意图类别、子集和难度等级进行切片评估,便于深入分析模型在不同维度上的强项与短板。预测结果需以包含id和prediction字段的JSON列表形式提交,通过调用示例评估命令即可获得全面的性能报告。该数据集尤其适用于金融领域问答、多文档检索、时间推理及文表联合理解等研究方向,为学术探索提供了标准化的测试平台。
背景与挑战
背景概述
Multi-Doc-2025 是由匿名研究团队于2026年发布的一款面向金融领域的多文档问答基准数据集,核心资源来源于标普500公司提交给美国证券交易委员会的Form 10-K年度报告。该数据集旨在填补现有金融问答基准在跨公司、跨年度以及跨模态(文本与表格)推理能力联合评估上的空白。通过涵盖87家代表性企业、12个GICS行业板块以及2022至2024三个财年,共计179份文件,构建了2327个问答对,并采用公司不相交的分割策略,有效保障了评测的泛化性与公平性。作为检索增强生成(RAG)系统评估的重要工具,Multi-Doc-2025为金融自然语言处理研究提供了统一的评测平台,推动了证据驱动的金融推理技术发展。
当前挑战
数据集所解决的领域问题核心在于金融RAG系统需同时应对跨文档信息整合、时间序列趋势推理以及结构化表格与非结构化文本的异构融合,而现有基准如FinQA或FinanceBench均未能全面覆盖这些需求。构建过程中面临的关键挑战包括:从海量SEC文件中筛选并解析出符合结构要求的10-K报告,并确保多源数据的一致性;设计能够精准反映跨公司、跨年度和跨模态推理难度的问答对生成策略,需要平衡问题复杂度与可重复性;采用大语言模型生成候选问答对后,需通过严格的质量过滤与金融领域专家审核以消除幻觉与标注误差;最终需要在保持子集平衡的前提下,实现基于公司的无泄露数据划分,这些步骤共同保障了数据集的高质量与真实性。
常用场景
经典使用场景
作为金融领域检索增强生成(RAG)系统的标杆性测试集,Multi-Doc-2025聚焦于跨公司、跨年度及跨模态(文本与表格)的复杂推理能力评估。其经典使用方式涵盖三类场景:同一公司多财年间的财务趋势推演,如同公司资本支出从2022至2024年的变化轨迹;同行业不同公司的横向对比分析,如摩根大通与美国银行的股本回报率差异;以及跨文档、跨年度与跨模态交织的复合推理,例如苹果与微软营收差距在三年间的演化过程。研究者常借此基准测试验证模型在多源异构财务文档上的信息抽取与数值计算精确度。
解决学术问题
该数据集系统性弥补了现有金融问答基准中三类关键学术空白:跨文档推理仅被部分覆盖、跨时序分析常被忽视、文本与表格的混合模态处理能力缺乏联合评估。通过精心设计的五个正交子集(S1至S5)及三级难度体系(L1至L3),它为学界提供了可解耦诊断模型薄弱环节的评估框架。其核心学术贡献在于揭示了单文档与多文档场景下模型表现的系统性差异,推动了财务领域证据归因生成与幻觉检测研究的发展,促使研究者重新审视RAG系统在真实金融分析中的鲁棒性边界。
衍生相关工作
基于Multi-Doc-2025的发布,学术界衍生出多个方向的研究工作:面向金融文档的异构检索增强生成框架(如HC-RAG)以此为基准展示其在跨公司、跨年份场景下的优越性能;多模态表格与文本联合推理模型在此数据集上验证了维度对齐策略的有效性;时序财务问答研究中,数据集的跨年度子集(S3)催生了事件驱动的时间感知注意力机制设计。此外,针对其L3全交叉子集的挑战,有学者专门开发了面向复合推理的级联式检索—推理管线,显著提升了在低资源高阶任务上的表现。
以上内容由遇见数据集搜集并总结生成


