issues-kaggle-notebooks
收藏Hugging Face2025-03-20 更新2025-03-21 收录
下载链接:
https://huggingface.co/datasets/HuggingFaceTB/issues-kaggle-notebooks
下载链接
链接失效反馈官方服务:
资源简介:
GitHub Issues & Kaggle Notebooks是一个由两个代码数据集组成的集合,旨在用于语言模型的训练,这些数据来源于GitHub问题和Kaggle平台上的笔记本。这些数据集是StarCoder2模型训练语料库的一个修改部分,即bigcode/StarCoder2-Extras数据集。我们对样本进行了格式化,移除了StarCoder2的特殊标记,并使用自然文本来界定问题和笔记本中的评论。
提供机构:
Hugging Face TB Research
创建时间:
2025-03-19
搜集汇总
数据集介绍
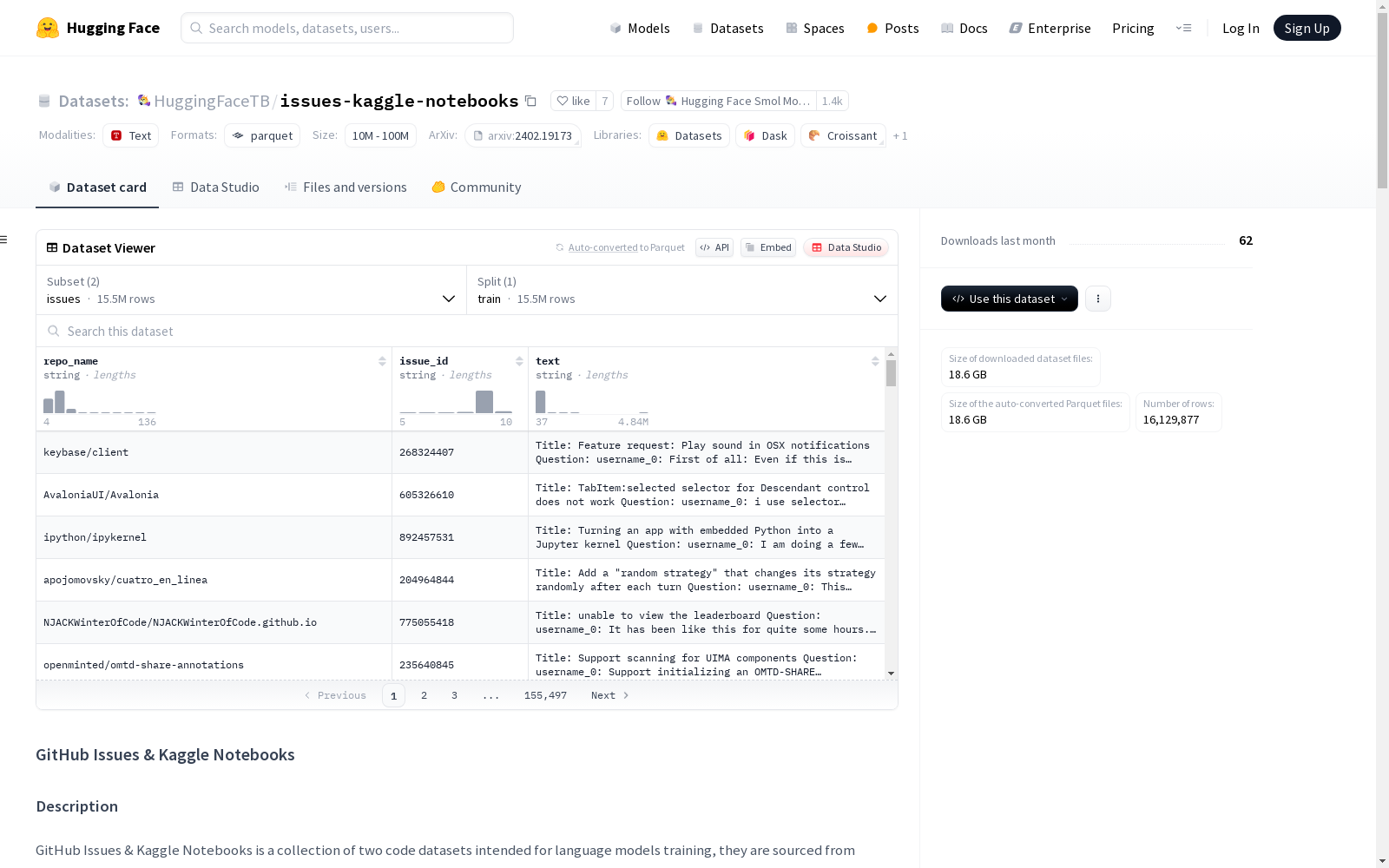
构建方式
该数据集由GitHub Issues和Kaggle Notebooks两部分组成,分别来源于GH Archive和Meta Kaggle Code数据集。GitHub Issues部分包含了来自GitHub仓库的讨论,涵盖了问题报告、错误跟踪和技术问答等内容;Kaggle Notebooks部分则包含了来自Kaggle平台的数据分析笔记本,以Markdown格式呈现。数据集经过多步过滤,去除了低质量内容、重复项以及个人身份信息(PII),确保了数据的高质量和安全性。
使用方法
用户可以通过Hugging Face的`datasets`库加载该数据集。使用`load_dataset`函数,可以分别加载GitHub Issues和Kaggle Notebooks部分。加载后的数据集可以直接用于语言模型的训练或分析任务。例如,加载GitHub Issues部分的代码为`issues = load_dataset('HuggingFaceTB/github-issues-notebooks', 'issues', split='train')`,加载Kaggle Notebooks部分的代码为`kaggle_notebooks = load_dataset('HuggingFaceTB/github-issues-notebooks', 'kaggle', split='train')`。
背景与挑战
背景概述
GitHub Issues & Kaggle Notebooks数据集由HuggingFace团队于2024年发布,旨在为语言模型训练提供高质量的代码相关文本数据。该数据集源自GitHub问题讨论和Kaggle平台上的数据分析笔记本,是StarCoder2模型训练语料库的一部分。GitHub Issues部分包含来自GH Archive的110亿个标记的讨论,涵盖了问题报告、错误跟踪和技术问答;Kaggle Notebooks部分则包含17亿个标记的数据分析笔记本,源自Kaggle的Meta Kaggle Code数据集。该数据集经过严格过滤,去除了低质量内容、重复项和个人身份信息(PII),确保了数据的纯净性和可用性。其发布为代码生成、自然语言处理等领域的研究提供了重要资源。
当前挑战
GitHub Issues & Kaggle Notebooks数据集在构建和应用中面临多重挑战。首先,数据质量的控制是关键问题,尽管团队通过过滤低质量内容、去除重复项和匿名化处理提升了数据质量,但仍需应对噪声数据和信息冗余的干扰。其次,数据格式的统一化处理是另一大挑战,GitHub Issues的对话结构和Kaggle Notebooks的Markdown格式需要标准化,以确保模型训练的连贯性。此外,数据隐私保护也是核心挑战之一,尽管使用了StarPII工具进行匿名化处理,但仍需确保敏感信息完全去除。最后,数据规模的庞大性对存储和计算资源提出了较高要求,如何在有限资源下高效处理和分析数据仍需进一步优化。
常用场景
经典使用场景
该数据集广泛应用于自然语言处理和代码生成领域,特别是用于训练和评估大型语言模型。GitHub Issues部分提供了丰富的技术讨论和问题解决案例,Kaggle Notebooks部分则包含了大量的数据分析和机器学习代码示例。这些数据为模型提供了多样化的语言和代码样本,帮助模型更好地理解和生成技术文档、代码片段以及数据分析报告。
解决学术问题
该数据集解决了自然语言处理领域中的多个关键问题,如代码生成、技术文档理解和自动问答系统的开发。通过提供大量的GitHub Issues和Kaggle Notebooks数据,研究人员可以训练模型以更好地理解技术讨论的上下文,并生成高质量的代码和技术文档。此外,数据集中的匿名化和过滤机制确保了数据的隐私性和质量,为学术研究提供了可靠的基础。
实际应用
在实际应用中,该数据集被广泛用于开发智能编程助手、自动化代码审查工具以及技术问答系统。例如,基于该数据集训练的模型可以帮助开发者快速定位和解决代码中的问题,或者自动生成数据分析报告。此外,这些模型还可以用于教育领域,帮助学生和初学者通过分析真实的技术讨论和代码示例来提升编程技能。
数据集最近研究
最新研究方向
近年来,随着开源社区和数据分析平台的蓬勃发展,GitHub Issues和Kaggle Notebooks数据集在自然语言处理和代码生成领域的研究中占据了重要地位。该数据集不仅为语言模型的训练提供了丰富的语料,还在代码理解、自动问答和数据分析任务中展现了巨大潜力。特别是在StarCoder2模型的训练过程中,这些数据集经过精心筛选和格式化,去除了低质量内容和重复数据,确保了数据的高效性和实用性。当前的研究热点集中在如何利用这些数据集进一步提升模型的代码生成能力、增强对技术讨论的理解,以及优化数据分析流程。此外,随着隐私保护意识的增强,数据匿名化处理技术也成为研究的重要方向。这些进展不仅推动了开源社区的技术创新,也为数据分析领域的自动化工具开发提供了有力支持。
以上内容由遇见数据集搜集并总结生成


