GEM/web_nlg
收藏Hugging Face2022-10-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/GEM/web_nlg
下载链接
链接失效反馈官方服务:
资源简介:
WebNLG是一个双语数据集(英语、俄语),包含并行的DBpedia三元组集和短文本,涵盖了约450个不同的DBpedia属性。该数据集最初是为了促进能够生成短文本并处理微规划(即句子分割和排序、指代表达生成、聚合)的RDF语言生成器的发展而创建的。任务的目标是从1到7个具有共同实体的输入三元组生成文本(即输入实际上是一个连接的知识图谱)。数据集包含约17,000个三元组集和45,000个众包文本(英语),以及7,000个三元组集和19,000个众包文本(俄语)。数据集还包含一个具有未在训练时见过的实体和/或属性的挑战性测试集部分。
WebNLG is a bilingual (English and Russian) dataset comprising parallel DBpedia triple sets and short texts, covering approximately 450 distinct DBpedia properties. It was originally created to facilitate the development of RDF-to-text generators that can produce short texts and handle micro-planning tasks, including sentence segmentation and ordering, referring expression generation, and information aggregation. The task objective is to generate coherent texts from 1 to 7 input triples that share common entities, where the input is effectively a connected knowledge graph. The dataset includes roughly 17,000 triple sets and 45,000 crowd-sourced English texts, alongside 7,000 triple sets and 19,000 crowd-sourced Russian texts. Additionally, the dataset features a challenging test split containing entities and/or properties unseen during model training.
提供机构:
GEM
原始信息汇总
数据集概述
数据集基本信息
- 名称: WebNLG
- 语言: 英语, 俄语
- 许可证: cc-by-nc-4.0
- 多语言性: 是
- 数据来源: 原始数据
- 任务类别: 表到文本
- 主要任务: 数据到文本
数据集描述
数据集概要
WebNLG是一个双语数据集,包含英语和俄语的平行DBpedia三元组集合和短文本,涵盖约450种不同的DBpedia属性。该数据集旨在促进RDF语法器的发展,能够生成短文本并处理微规划(如句子分割和排序、指称表达生成、聚合)。任务目标是从1到7个具有共同实体的输入三元组(即输入实际上是一个连接的知识图谱)生成文本。数据集包含约17,000个三元组集合和45,000个众包英语文本,以及7,000个三元组集合和19,000个众包俄语文本。
数据集结构
数据字段
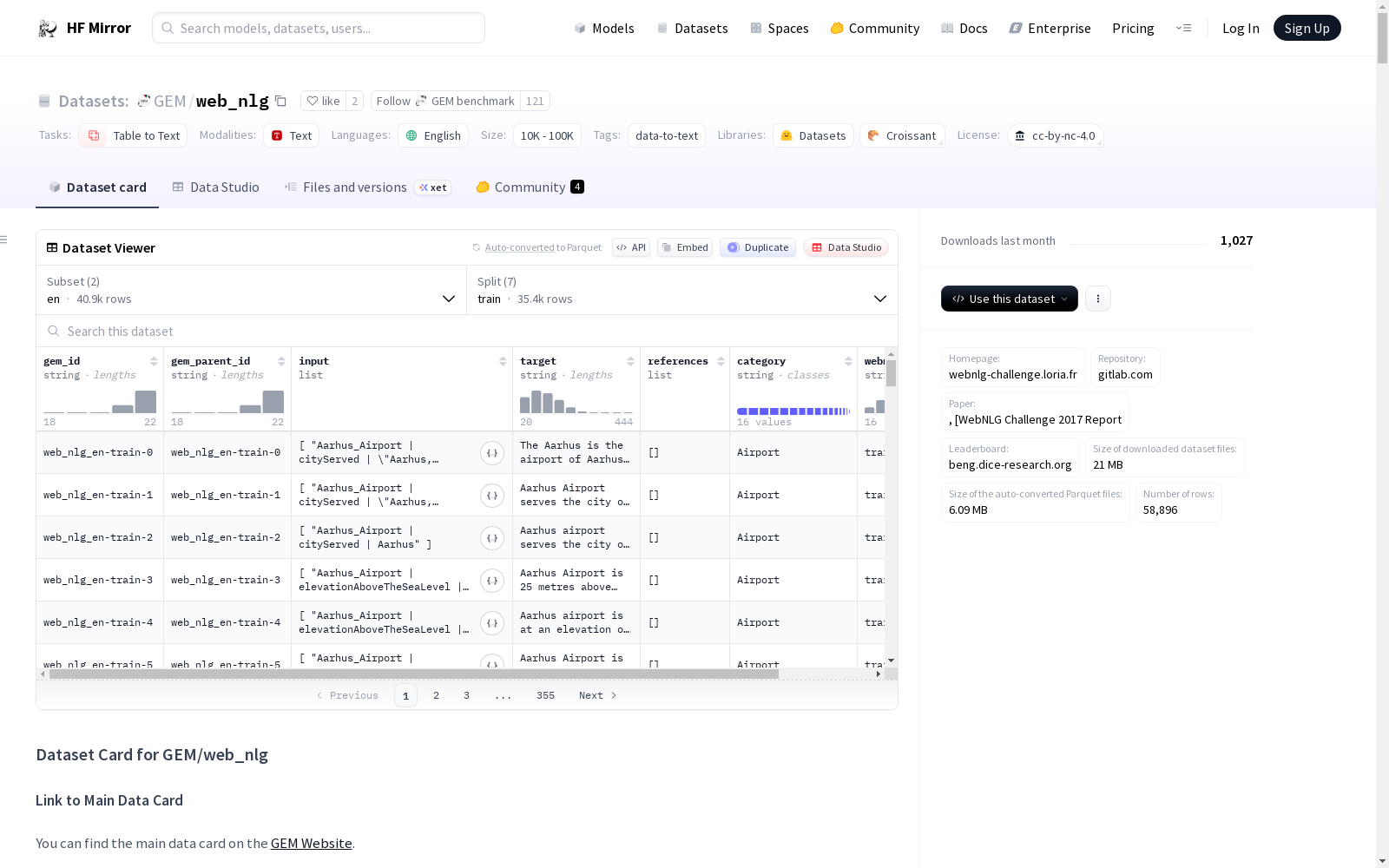
entry: 包含五个属性:DBpedia类别(category)、条目ID(eid)、形状、形状类型和三元组集大小(size)。originaltripleset: 从DBpedia提取的RDF三元组集合。modifiedtripleset: 提供给众包工作者的RDF三元组集合。lexs: 词汇化文本,包含评论(comment)和词汇化ID(lid)。
数据分割
| 语言 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| 英语 | 13,211 | 1,667 | 1,779 |
| 俄语 | 5,573 | 790 | 1,102 |
数据集用途
主要任务
- 数据到文本: 模型应将提供的输入三元组全部且仅以自然语言形式表达。
许可证
- cc-by-nc-4.0: 允许非商业用途的共享和改编,需注明原作者。
数据集创建者
- 主要维护者: Anastasia Shimorina (Université de Lorraine / LORIA, France)
- 贡献者: Claire Gardent (CNRS / LORIA, France), Shashi Narayan (Google, UK), Laura Perez-Beltrachini (University of Edinburgh, UK), Elena Khasanova, Thiago Castro Ferreira (Federal University of Minas Gerais, Brazil)
资金来源
- 法国国家研究机构(ANR)
数据集在GEM中的应用
为何包含在GEM中
- 评估特定生成能力: 由于任务的约束性,该数据集可用于评估非常具体和狭窄的生成能力。
与其他数据集的区别
- 独特的RDF三元组格式: WebNLG的RDF-triple格式是其与其他数据集的主要区别。
GEM特定修改
- 未对数据集内容进行修改: 使用的是数据集的3.0版本。
- 增加了23个特殊测试集: 包括英语和俄语,用于评估模型在不同条件下的表现。
搜集汇总
数据集介绍
构建方式
在数据到文本生成的研究领域,WebNLG数据集通过精心设计的众包流程构建而成。该数据集以DBpedia知识库为基础,从中提取了涵盖约450种属性的RDF三元组,并邀请众包工作者将这些结构化数据转化为自然语言文本。构建过程中,原始三元组经过适当修改以确保一致性与同质性,同时保留了与知识库的关联。数据集包含英语和俄语两个版本,分别收录了约17,000组和7,000组三元组,并对应生成了45,000条和19,000条文本,形成了高质量的平行语料。
使用方法
研究人员可通过HuggingFace的datasets库便捷加载该数据集,使用`datasets.load_dataset('GEM/web_nlg')`指令即可获取结构化数据。数据集已划分为训练集、开发集和测试集,并提供了详细的元数据字段,如三元组形状、类别及文本注释。在模型训练时,建议采用修改后的三元组作为输入,以保持数据一致性。评估阶段可参考官方排行榜,综合BLEU、METEOR、BERTScore等多种指标衡量生成文本的质量。
背景与挑战
背景概述
在自然语言生成领域,将结构化数据转化为流畅文本是一项核心挑战。WebNLG数据集于2017年由法国洛林大学、法国国家科学研究中心、爱丁堡大学等机构的研究团队共同创建,主要贡献者包括Anastasia Shimorina、Claire Gardent等学者。该数据集旨在推动RDF三元组的自然语言表达与微观规划技术发展,涵盖约450种DBpedia属性,包含英语和俄语的双语平行语料。其核心研究问题聚焦于如何从连接的知识图谱中生成连贯、准确的短文本,对数据到文本生成任务的研究产生了深远影响,成为该领域的重要基准资源。
当前挑战
WebNLG数据集致力于解决数据到文本生成任务的挑战,特别是处理复杂知识图谱的语义表达与语言流畅性之间的平衡。构建过程中,团队面临多重困难:确保从DBpedia提取的三元组在修改后保持语义一致性与结构同质性,同时通过众包方式收集高质量、多样化的文本表达,需精细设计标注流程以覆盖不同领域与语言构造。此外,数据集的扩展版本引入了未见实体与属性的测试集,增加了模型泛化能力的评估难度,对生成系统的鲁棒性与适应性提出了更高要求。
常用场景
经典使用场景
在自然语言生成领域,WebNLG数据集作为数据到文本转换任务的基准,其经典应用场景聚焦于将结构化的知识图谱三元组转化为连贯的自然语言描述。该数据集通过提供从DBpedia提取的丰富三元组集合及其对应的人工撰写文本,为模型训练与评估构建了标准化的测试平台。研究者利用这一资源,能够系统地探索如何将离散的语义关系整合为流畅的叙述,从而推动生成模型在内容准确性与语言自然度方面的双重提升。
解决学术问题
WebNLG数据集有效应对了自然语言生成中微观规划的核心挑战,包括句子分割、排序、指代生成与信息聚合等复杂问题。通过涵盖多样化的知识类别与三元组结构,该数据集为模型处理未见实体与属性的泛化能力提供了严谨的评估框架。其引入促进了生成系统在保持语义忠实度的同时,实现语言表达的多样性与连贯性,为知识图谱的自动化文本生成奠定了坚实的实证基础。
实际应用
在实际应用中,WebNLG数据集支撑了智能问答系统、自动报告生成以及知识库摘要等关键场景。例如,在商业智能领域,模型可依据企业知识图谱中的属性关系,自动生成公司概况或产品描述;在教育技术中,它能够将历史事件或科学事实的三元组转化为易于理解的叙述文本。这些应用显著提升了信息检索与传播的效率,使结构化数据得以以更人性化的方式呈现给终端用户。
数据集最近研究
最新研究方向
在自然语言生成领域,WebNLG数据集作为结构化知识到文本转换的基准,持续推动着前沿研究的发展。当前研究聚焦于提升模型在未见实体与属性上的泛化能力,通过对抗性测试和零样本学习策略应对知识图谱中复杂关系的表达挑战。随着多语言生成需求的增长,该数据集的双语特性促进了跨语言迁移学习与低资源语言生成技术的探索,相关成果在语义保持与流畅性平衡方面展现出深远影响。同时,微规划任务的深化研究进一步优化了句子结构生成与指代消解,为自动化报告生成和智能对话系统提供了坚实支撑。
以上内容由遇见数据集搜集并总结生成


