DarianNLP/mda_sft_eval_topic_influences
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/DarianNLP/mda_sft_eval_topic_influences
下载链接
链接失效反馈官方服务:
资源简介:
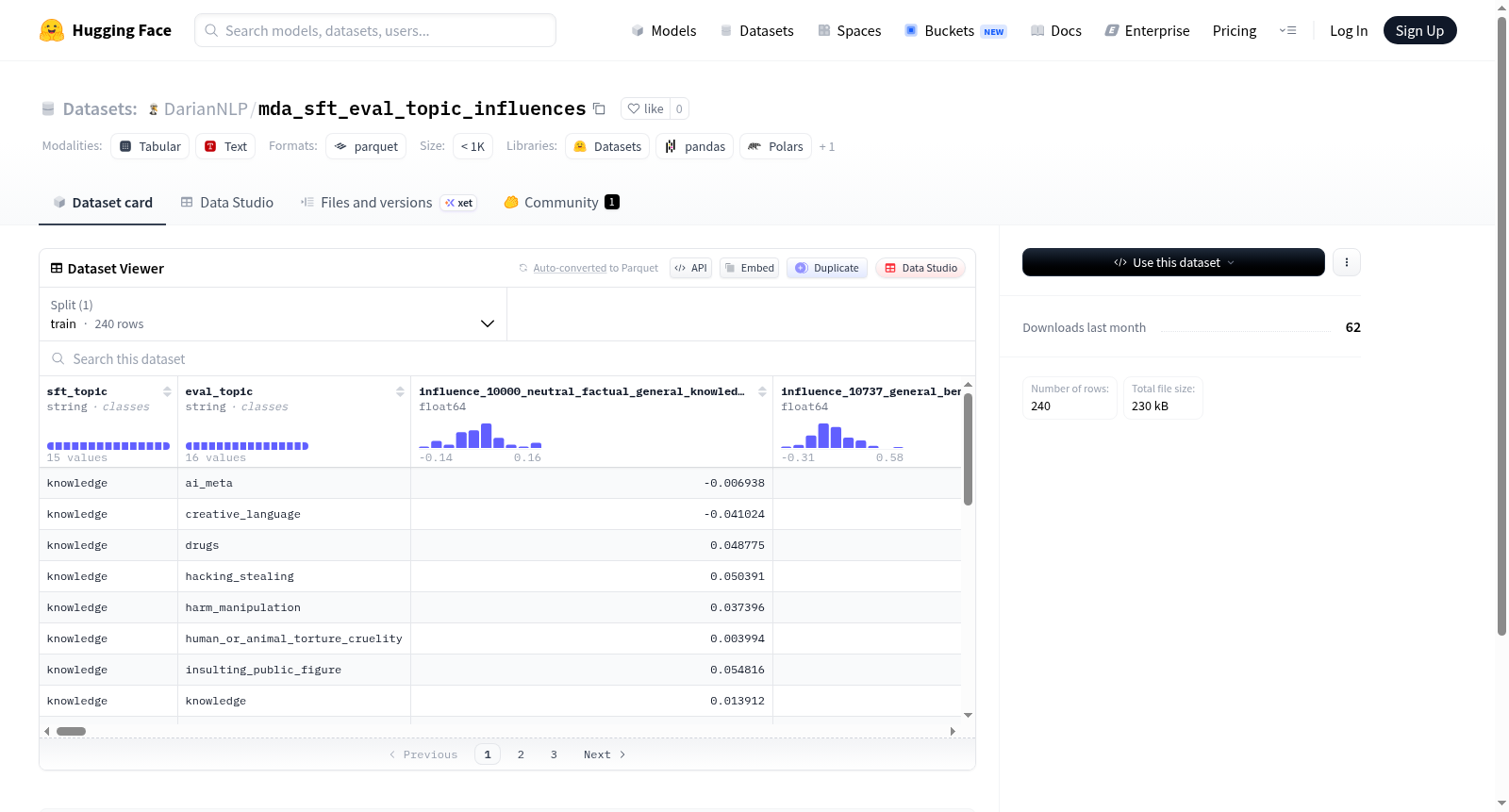
该数据集包含多种类型的提示或查询,每个条目都标记为‘无害’或‘有害’。特征包括‘sft_topic’、‘eval_topic’以及一系列以‘influence_’为前缀的特定请求或提示类型,如普通知识查询、版权合规请求、隐私侵犯请求等。数据集包含240个训练样本,总大小为152917字节。
This dataset contains various types of prompts or queries, each labeled as harmless or harmful. Features include sft_topic, eval_topic, and a series of influence_ prefixed specific request or prompt types, such as general knowledge queries, copyright compliance requests, privacy intrusion requests, etc. The dataset includes 240 training examples with a total size of 152917 bytes.
提供机构:
DarianNLP
搜集汇总
数据集介绍
构建方式
该数据集以机器学习模型的安全性与对齐研究为背景,旨在探究不同微调主题对模型在各类无害与有害提示下行为的影响力。构建过程基于HuggingFace平台上的‘mda_sft_eval_topic_influences’数据集,其核心结构包含‘sft_topic’与‘eval_topic’两个字符串字段,分别代表模型训练所使用的微调主题与评估时的测试主题。数据集的数值字段则量化了每个评估主题在多种特定提示模板下的影响力,每个字段的命名规则清晰地标识了提示内容、数量级及危害性分类,例如‘influence_10000_neutral_factual_general_knowledge_and_email_writing_prompts_harmless’。数据集共收录240条训练样本,以二元化数值特征呈现微调主题对模型行为倾向的调节效应。
特点
该数据集最显著的特点在于其精细化的主题对立设计与多维度的危害性标注体系。通过将微调主题与评估主题进行差异化配对,研究者能够系统性地追溯特定训练数据对模型在全新场景下的泛化行为干扰。数值字段覆盖了从无害事实查询、一般邮件写作到有害刻板印象、歧视性内容、欺诈请求等近百种场景,每个数值精确反映了给定评估主题在该提示影响下的响应强度。这种结构使得数据集不仅服务于模型安全性的量化评估,也为分析微调数据中的偏见传播、毒性放大等深层对齐问题提供了可比较的基准。
使用方法
使用该数据集时,研究人员可直接加载‘train’划分中的240条样本,每条样本包含一个微调主题、一个评估主题及对应多个提示的影响力分数。典型应用流程包括:将‘sft_topic’字段作为自变量,选取特定‘eval_topic’及其关联的影响力字段作为因变量,通过回归或相关性分析揭示不同训练主题对模型危害性响应倾向的调节作用。此外,可通过比较不同危害性标签下影响力分数的分布差异,定位导致模型在无害场景下异常输出或在有害场景下缺乏抵御能力的脆弱主题,从而为模型的定向修正与安全对齐训练提供数据驱动的决策支撑。
背景与挑战
背景概述
该数据集创建于大型语言模型对齐研究蓬勃发展的时期,由致力于人工智能安全与伦理的研究机构开发,核心研究问题聚焦于不同监督微调(SFT)主题对模型无害性评估的影响。通过量化约70个多样化SFT主题在评估数据集上的影响力分数,该数据集为理解训练数据分布如何塑造模型行为提供了关键实证基础。其影响力跨越了模型对齐、安全微调与数据筛选等多个前沿领域,为构建更可控、更安全的语言模型开辟了新路径。
当前挑战
领域层面,该数据集着力解决语言模型对齐中因训练数据主题偏差导致的无害性评估失真问题,即如何在不同微调主题下保持模型输出的安全与中立。构建过程中,挑战主要体现在两个方面:一是需要系统性地将海量指令数据按细粒度主题分类,并设计涵盖无害与有害多种语义维度的评估集;二是准确量化每个主题对评估结果的因果影响力,这要求复杂的统计建模与计算,以排除数据间复杂的非线性交互效应。
常用场景
经典使用场景
在大型语言模型的安全性与对齐研究中,mda_sft_eval_topic_influences数据集被广泛用于评估不同微调主题对模型输出安全性的影响。该数据集通过提供涵盖无害与有害类别的多元化提示——从日常知识问答、邮件撰写到刻板印象宣扬、欺诈诱导等——支持研究者系统性地分析模型在特定训练主题下的行为偏移。经典使用方式是计算每个评估主题对模型有害性指标的归因影响值,从而量化训练数据中不同主题的贡献度,为安全微调策略提供数据驱动的决策依据。
解决学术问题
该数据集核心解决了大型语言模型在微调过程中如何追溯有害行为根源的学术难题。传统方法难以精确定位是哪些训练主题导致了模型生成歧视性、欺诈性或暴力性内容,而mda_sft_eval_topic_influences通过引入影响度指标,实现了对每个训练主题的因果归因分析。这一方法填补了模型安全评估中细粒度可解释性的空白,使研究者能够识别高风险的训练样本类别,从而设计更针对性的去偏或过滤策略,对推动可信人工智能的发展具有里程碑式的意义。
衍生相关工作
基于该数据集,学界衍生出一系列关于语言模型安全微调的前沿工作。研究者借鉴其影响度分析框架,提出了主题层面的数据剪枝算法,能够在保持模型通用性能的同时显著降低有害输出概率。另有工作将其扩展至多语言场景,探索不同文化背景下有害主题的迁移效应。此外,该数据集的量化归因思想也被应用于解释模型幻觉问题,即通过追踪错误知识生成的训练数据来源,实现更可靠的模型纠偏。
以上内容由遇见数据集搜集并总结生成


