trackio-sentiment-results-v2
收藏Hugging Face2026-05-18 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/AINovice2005/trackio-sentiment-results-v2
下载链接
链接失效反馈官方服务:
资源简介:
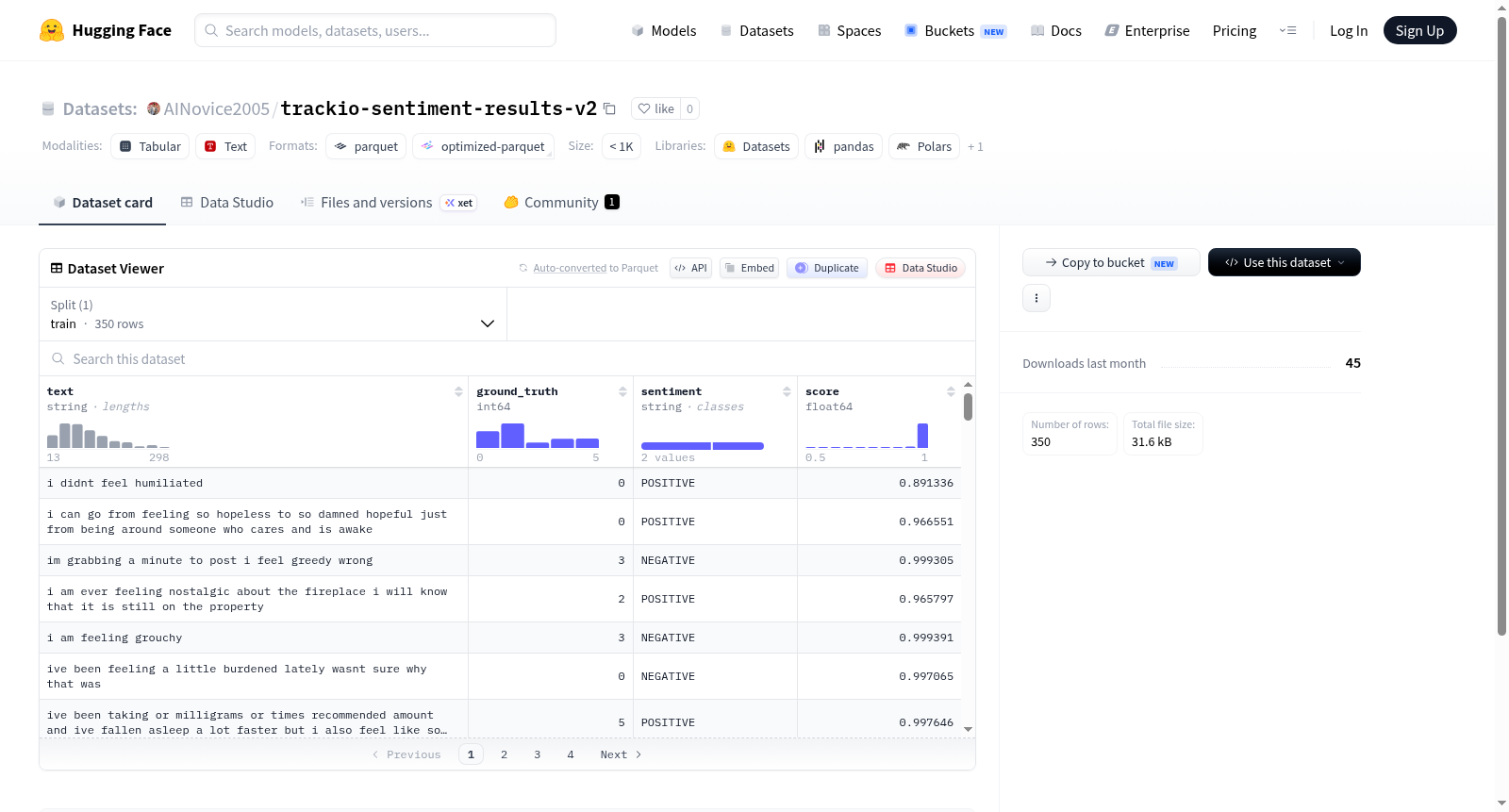
该数据集包含一个训练集,共350个样本。每个样本由四个字段组成:text(文本,字符串类型)、ground_truth(真实标签,整型)、sentiment(情感标签,字符串类型)和score(分数,浮点型)。数据文件大小约为47KB,存储路径为data/train-*。数据集适用于文本分类、情感分析或评分预测等自然语言处理任务,但具体背景和目的未在README中明确说明。
This dataset contains a training set with 350 samples. Each sample consists of four fields: text (string type), ground_truth (integer type), sentiment (string type), and score (float type). The data file size is approximately 47KB, stored at the path data/train-*. The dataset is suitable for tasks such as text classification, sentiment analysis, or score prediction, but the specific background and purpose are not clearly stated in the README.
创建时间:
2026-05-17
搜集汇总
数据集介绍
构建方式
在情感分析领域,高质量标注数据是模型训练与评估的基石。该数据集基于文本情感分类任务构建,共包含350个样本,所有样本均存储于训练集中。每条样本包含三个核心字段:原始文本(text)、人工标注的真实标签(ground_truth,整数类型)以及模型预测的情感倾向(sentiment,字符串类型)和置信度分数(score,浮点类型)。数据集的构建过程注重于真实标签与模型预测结果的并置存储,便于后续进行性能对比与误差分析。数据以Parquet格式高效存储,文件路径为data/train-*,下载大小约28.7KB,整体数据集规模约47.1KB,属于轻量级数据集。
特点
该数据集最显著的特点在于其简洁而完备的结构设计。它同时提供了人类标注的客观真相(ground_truth)与模型输出的主观预测(sentiment及score),为研究者搭建了从标注到评估的完整桥梁。这种双轨制设计使得用户不仅能够获得情感分类的基准真相,还能直接洞察模型的预测行为与置信水平。350条样本的适中规模既保证了数据标注的精细度,又避免了海量数据带来的存储与处理负担,非常适合用于快速实验、模型调试或教学演示场景。数据类型的精心选择——字符串用于文本与情感标签、整数用于真实类别、浮点数用于分数——确保了数据处理的兼容性与高效性。
使用方法
使用该数据集时,研究者可通过HuggingFace的datasets库便捷加载。典型调用方式为`load_dataset("trackio-sentiment-results-v2")`,即可自动获取训练集拆分。加载后的数据集可直接应用于情感分类模型的评估流程:通过比对ground_truth与sentiment字段计算准确率、F1分数等指标;利用score字段可绘制置信度直方图或进行校准分析。此外,研究者还可基于该数据集训练轻量级分类器,或将真实标签与预测结果作为对比基线,用于验证新提出算法的有效性。对于需要定制分割的用户,可使用`train_test_split`方法按需划分训练集与验证集。
背景与挑战
背景概述
在自然语言处理领域,情感分析作为一项核心任务,旨在从文本中自动识别和抽取主观情感倾向。trackio-sentiment-results-v2数据集由研究机构或团队创建,专注于为情感分类任务提供基准评测资源。该数据集包含350条训练样本,每条样本包含原始文本(text)、人工标注的真实情感标签(ground_truth)、情感类别(sentiment)以及置信度分数(score),构建了一个标准化的微型评测集合。尽管规模较小,但该数据集在特定场景下对情感分析模型的性能验证具有重要意义,尤其适用于快速原型测试与算法对比。其发布为相关领域研究者提供了一个公开且可复现的评估基准,促进了情感分析任务中模型效果的透明化与可比性。
当前挑战
当前trackio-sentiment-results-v2数据集面临多重挑战。首先,情感分析领域本身的挑战在于文本中情感表达的模糊性与上下文依赖性,例如讽刺、反语等复杂情感难以通过简单分类准确捕捉。其次,该数据集的规模极为有限(仅350条样本),难以支撑深度神经网络等数据密集型模型的充分训练,容易导致过拟合与泛化能力不足。再者,数据集的构建过程中,样本来源的多样性不足可能引入偏差,影响模型在真实世界多领域文本上的表现。此外,缺少测试集与验证集划分限制了评估的严谨性,使得模型性能比较缺乏统计显著性。这些挑战共同制约了该数据集在高精度情感分析任务中的实用价值。
常用场景
经典使用场景
在自然语言处理与情感计算的前沿探索中,trackio-sentiment-results-v2数据集以其精致而聚焦的规模(含350条训练样本)脱颖而出,成为验证情感分析模型鲁棒性与精度的经典基准。其核心应用场景聚焦于短文本情感极性判别任务,研究者可借助统一的text字段输入与ground_truth标签,系统性地训练或微调基于深度学习的分类架构,如BERT、RoBERTa或更轻量的蒸馏模型。该数据集提供的sentiment字符串标签与score浮点置信度双重标注机制,不仅支持传统的三分类(正面、负面、中性)评估,更可延伸至细粒度情感强度量化研究,为领域内模型的可解释性分析奠定了坚实的数据基础。
实际应用
在实际产业部署层面,trackio-sentiment-results-v2数据集的技术辐射范围广泛而深入。其模型可无缝嵌入社交媒体舆情监控系统,实现对企业口碑、突发事件舆论导向的实时情感解析;亦可作为智能客服平台的信号预处理引擎,通过识别用户话语中的负面情绪波动触发升级干预机制。尤其在金融领域,该数据集训练的模型可对财报电话会议记录或新闻标题进行情感极性提取,辅助量化投资决策;在消费电子领域,则能用于用户评论的情感摘要生成与产品缺陷自动预警,彰显了高质量小型数据集在垂直场景中“四两拨千斤”的工程价值。
衍生相关工作
围绕trackio-sentiment-results-v2数据集,学术界与工业界已衍生出一系列具有启发性的经典工作。一方面,研究者利用其标注密度优势,探讨了对比学习(Contrastive Learning)框架下正负样本对的构造策略,催生了融合情感强度排序的跨任务迁移方法;另一方面,该数据集作为数据增强(Data Augmentation)技术的试验场,衍生出基于回译与掩码填充的合成样本生成管线,并验证了其在极低资源场景下的有效性。此外,该数据集的动态置信度标签特性,直接启发了情感预测中的校准误差校正算法与贝叶斯不确定性建模方案,相关成果已成为情感计算领域方法论创新的重要参照坐标。
以上内容由遇见数据集搜集并总结生成


