LabHC/moji
收藏Hugging Face2023-09-28 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/LabHC/moji
下载链接
链接失效反馈官方服务:
资源简介:
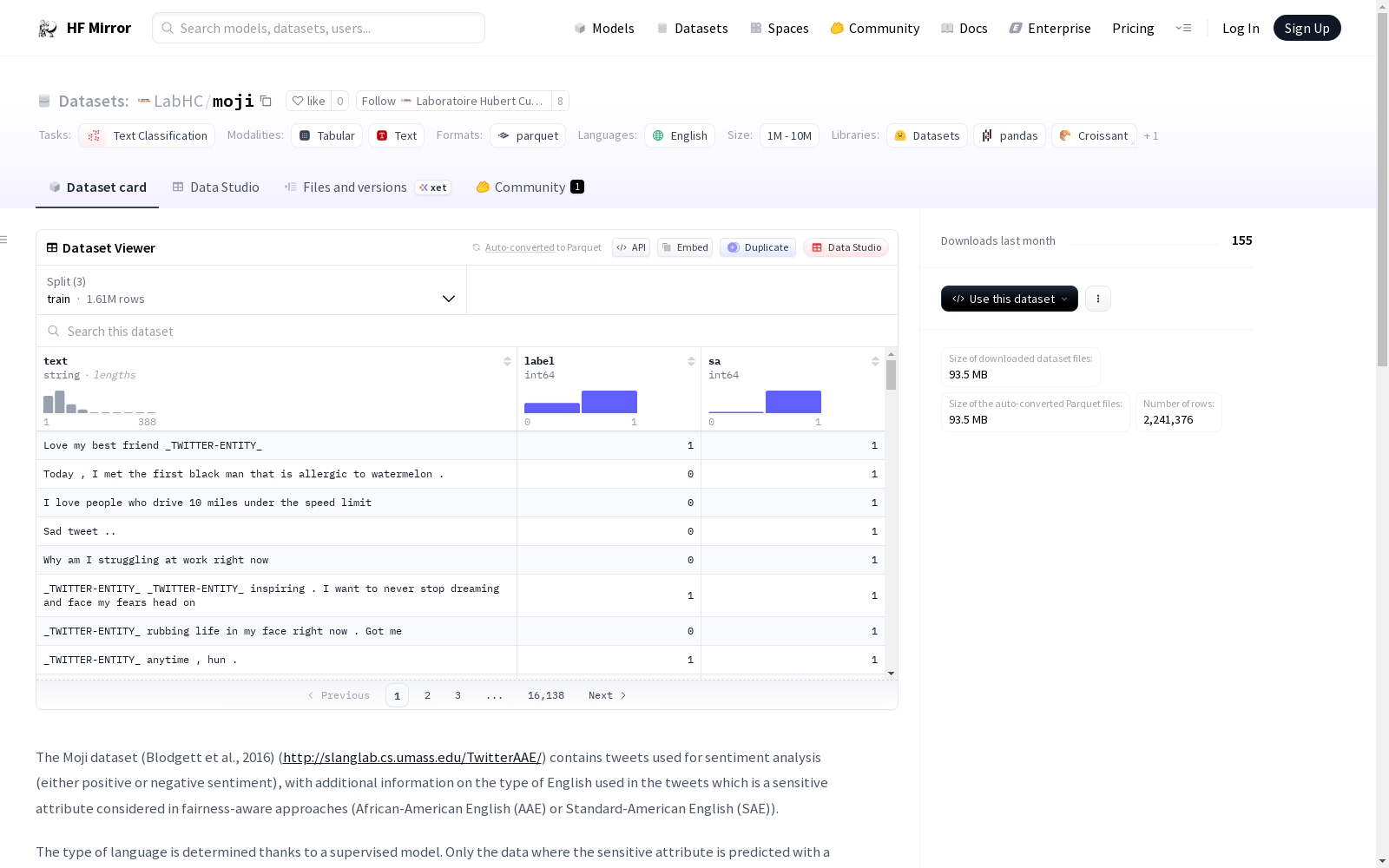
Moji数据集(Blodgett等,2016)包含用于情感分析(正面或负面情感)的推文,并包含关于推文中使用的英语类型的信息(非洲裔美国人英语(AAE)或标准美国英语(SAE)),这是公平性方法中考虑的敏感属性。数据集的语言类型是通过监督模型确定的,并且只保留了敏感属性预测置信度高于给定阈值的数据。基于此,提供了两个版本的Moji数据集,分别具有80%和90%的阈值。
The Moji dataset (Blodgett et al., 2016) contains tweets annotated for sentiment analysis (labeled with either positive or negative sentiment), and includes metadata specifying the English variety used in each tweet—African American English (AAE) or Standard American English (SAE)—which serves as the sensitive attribute considered in fairness research. The English variety labels were assigned via a supervised classification model, and only data points with a prediction confidence for the sensitive attribute exceeding a predefined threshold are retained. Accordingly, two versions of the Moji dataset are provided, with thresholds of 80% and 90% respectively.
提供机构:
LabHC
原始信息汇总
数据集概述
任务类别
- 文本分类
语言
- 英语
数据集信息
-
特征
text: 字符串类型label: 64位整数类型sa: 64位整数类型
-
分割
train: 128596235字节, 1613790个样本test: 35731728字节, 448276个样本dev: 14325121字节, 179310个样本
-
下载大小: 93470968字节
-
数据集大小: 178653084字节
数据集版本
-
80%阈值版本
- AAE
- 正面情感: 73013
- 负面情感: 44023
- 总计: 117036
- SAE
- 正面情感: 1471427
- 负面情感: 652913
- 总计: 2124340
- 总计
- 正面情感: 1544440
- 负面情感: 696936
- 总计: 2241376
- AAE
-
90%阈值版本
- AAE
- 正面情感: 30827
- 负面情感: 18409
- 总计: 49236
- SAE
- 正面情感: 793867
- 负面情感: 351600
- 总计: 1145467
- 总计
- 正面情感: 824694
- 负面情感: 370009
- 总计: 1194703
- AAE
搜集汇总
数据集介绍
构建方式
在社交媒体文本挖掘领域,Moji数据集通过精心设计的筛选流程构建而成。该数据集源自Blodgett等人于2016年收集的推文,核心目标在于分析情感倾向与语言变体之间的关系。构建过程中,研究者采用监督模型对每条推文所使用的英语变体进行自动识别,具体区分非洲裔美国人英语(AAE)与标准美国英语(SAE)。为确保语言类别标注的可靠性,仅保留模型预测置信度高于特定阈值的数据条目,并据此衍生出置信阈值为80%与90%的两个版本,从而在数据规模与标注确定性之间取得平衡。
特点
Moji数据集的显著特征在于其多维标注体系与规模化的数据构成。该数据集不仅包含推文文本及其二元情感标签(积极或消极),还引入了语言变体这一敏感属性,为研究计算社会语言学中的公平性问题提供了关键维度。数据分布呈现显著的不均衡性,标准美国英语样本数量远多于非洲裔美国人英语,这真实反映了社交媒体平台上的语言使用现状。两个阈值版本分别包含约224万与119万条数据,为大规模模型训练与评估提供了充足资源,同时其清晰的结构化划分便于进行稳健的验证与分析。
使用方法
在自然语言处理研究中,Moji数据集主要用于文本分类与公平性机器学习任务。使用者可通过Hugging Face的`load_dataset`函数便捷加载数据,默认参数对应80%置信阈值的版本。若需使用更高置信度的90%阈值版本,则需指定相应的修订版本号。加载后,数据集提供训练集、测试集与开发集的标准划分,每条数据包含文本、情感标签及语言变体标签,可直接用于模型训练、评估及偏差分析。该数据集尤其适用于探索模型在不同语言变体群体上的性能差异,推动公平且稳健的社交媒体情感分析模型发展。
背景与挑战
背景概述
在自然语言处理领域,社交媒体文本的情感分析一直是研究热点,而语言变体对模型性能的影响逐渐受到关注。Moji数据集由Blodgett等人于2016年创建,旨在探索非洲裔美国人英语(AAE)与标准美国英语(SAE)在推特文本中的情感表达差异。该数据集由马萨诸塞大学阿默斯特分校的研究团队构建,核心研究问题聚焦于语言变体对情感分类模型公平性的影响。通过标注超过两百万条推文的情感极性及语言类型,该数据集为公平机器学习研究提供了重要基准,推动了自然语言处理领域对算法偏见和语言多样性的深入探讨。
当前挑战
Moji数据集所解决的领域问题在于情感分析模型对语言变体的公平性评估,其挑战在于如何准确识别不同语言变体中的情感表达,避免模型因语言差异而产生系统性偏见。构建过程中的挑战主要涉及语言变体的自动标注:由于缺乏直接的语言类型标注,研究者需依赖监督模型进行预测,并通过设定置信度阈值筛选数据,这可能导致数据分布偏差或标注噪声。此外,社交媒体文本的非正式性和文化特异性增加了语言类型判定的复杂性,如何平衡数据规模与标注精度成为关键难题。
常用场景
经典使用场景
在自然语言处理领域,Moji数据集为情感分析与公平性研究提供了关键资源。该数据集通过标注推文的情感极性(积极或消极)及语言变体(非洲裔美国人英语或标准美国英语),成为评估模型在跨方言环境下性能的基准工具。研究者常利用其构建分类模型,以探索语言变体对情感预测的影响,从而揭示算法在多样化语言表达中的鲁棒性。
衍生相关工作
基于Moji数据集,学术界衍生了一系列经典研究工作。例如,Blodgett等人的原始论文《Demographic Dialectal Variation in Social Media: A Case Study of African-American English》开创了社交媒体方言变体分析的先河。后续研究则扩展至公平性正则化方法、对抗性去偏见框架以及跨方言迁移学习模型,这些工作共同深化了语言技术中公平与性能平衡的探讨。
数据集最近研究
最新研究方向
在自然语言处理领域,Moji数据集作为融合情感分析与公平性研究的代表性资源,其最新研究方向聚焦于语言变体与算法公平性的交叉探索。前沿研究利用该数据集探讨非洲裔美国英语(AAE)与标准美国英语(SAE)之间的语言差异如何影响情感分类模型的性能偏差,推动公平感知机器学习方法的发展。相关热点事件包括社交媒体平台对语言多样性的关注,促使研究者通过Moji数据集评估和缓解算法对少数语言群体的歧视问题。这一研究方向不仅深化了语言模型对文化敏感性的理解,也为构建包容性人工智能系统提供了实证基础,在自然语言处理与社会计算领域具有重要的理论意义与实践价值。
以上内容由遇见数据集搜集并总结生成


