LoCoEval
收藏arXiv2026-03-06 更新2026-03-10 收录
下载链接:
https://anonymous.4open.science/r/LoCoEval
下载链接
链接失效反馈官方服务:
资源简介:
LoCoEval是首个面向代码仓库开发场景的长时域对话上下文管理基准数据集,由北京航空航天大学团队通过LLM驱动的自动化流程构建。该数据集包含128个样本,分为单跳和多跳两个子集,每个样本平均包含2.5个需求项和50轮对话,上下文总长度达64K~256K tokens,数据源自现有仓库级代码生成数据集的样本扩展。其构建过程模拟了真实开发中的迭代需求、噪声输入和回溯提问等交互模式,支持主题感知、信息项提取和函数生成三类评估任务,旨在解决代码助手在复杂仓库开发场景下的上下文信息丢失与性能退化问题。
LoCoEval is the first benchmark dataset for long-horizon dialogue context management in code repository development scenarios, constructed by the team from Beihang University via an LLM-driven automated workflow. This dataset contains 128 samples divided into two subsets: single-hop and multi-hop. Each sample includes an average of 2.5 requirement items and 50 dialogue turns, with a total context length ranging from 64K to 256K tokens. The data is derived from sample expansions of existing repository-level code generation datasets. Its construction process simulates real-world development interaction patterns such as iterative requirements, noisy inputs, and retrospective questioning. It supports three types of evaluation tasks: topic-aware processing, information item extraction, and function generation. This benchmark aims to address the issues of context information loss and performance degradation of code assistants in complex code repository development scenarios.
提供机构:
北京航空航天大学·复杂关键软件环境国家重点实验室
创建时间:
2026-03-06
搜集汇总
数据集介绍
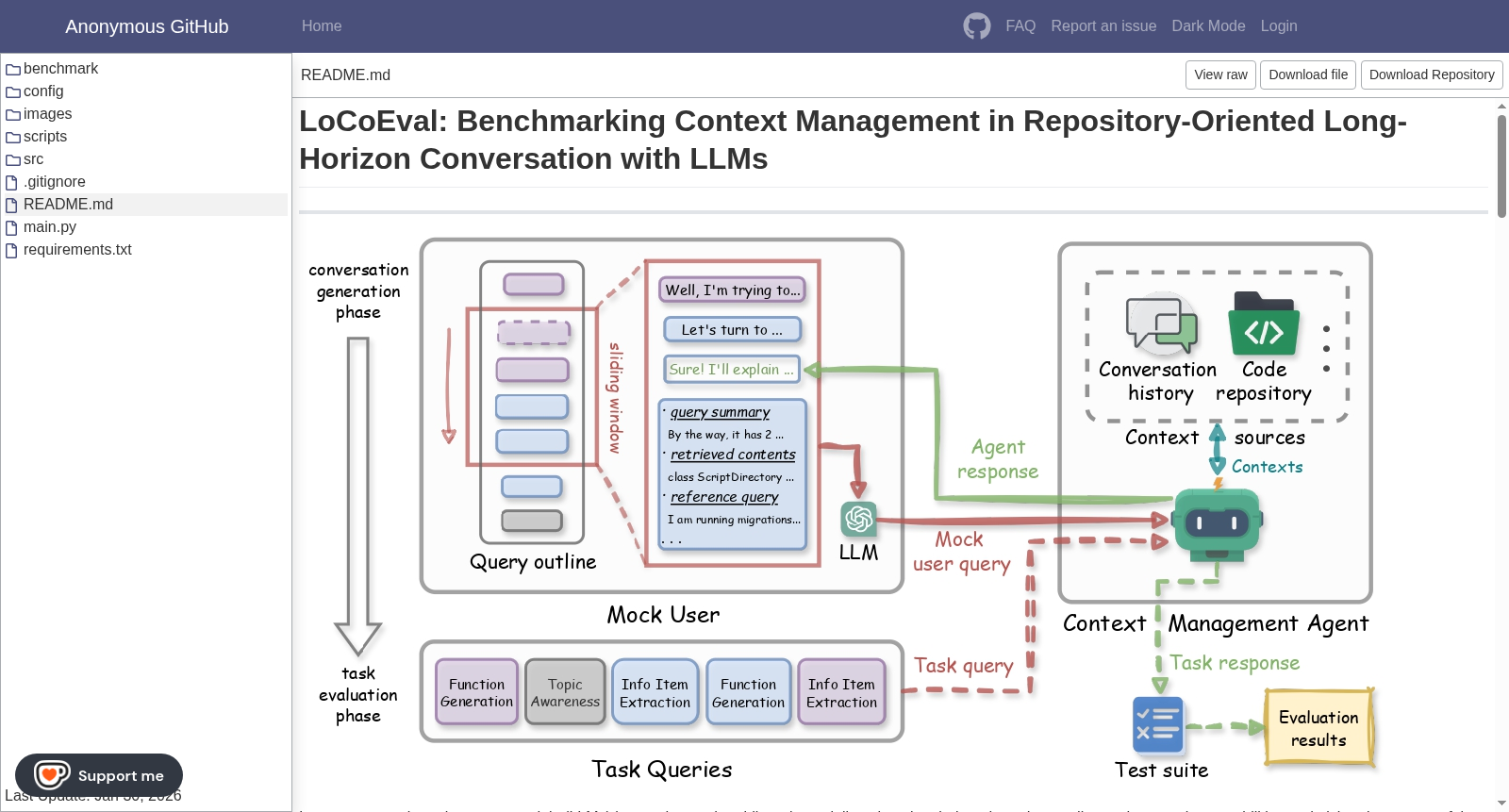
构建方式
在代码助手日益普及的背景下,面对仓库开发中长程对话上下文管理的评估空白,LoCoEval的构建遵循了正确性、真实性与多样性三大核心原则。其构建流程采用了一种新颖的、由大语言模型驱动的自动化管道。该流程以现有仓库级代码生成数据集(如DevEval)为基础,首先筛选出无法仅通过仓库代码解决的样本,确保评估焦点落在对话上下文管理上。随后,通过静态分析与大语言模型相结合的方式,从目标函数的参考实现中提取关键的真实信息项,并对其进行可控的语义变异以生成干扰信息项,模拟真实开发中的噪声与迭代。这些信息项被组织成依赖图,并通过序列化、分散与分区等步骤,最终构建出包含多个任务与非任务主题的查询大纲骨架。该骨架再经由大语言模型填充具体内容,并随机插入回顾性查询,最终形成包含平均50轮对话、上下文长度可达64K至256K个标记的多样化、长程对话场景。
特点
LoCoEval作为首个专为仓库导向长程对话上下文管理设计的基准测试,其特点鲜明且具有针对性。数据集包含128个样本,并依据信息分布模式划分为单跳与多跳两个子集,分别评估模型对集中式与分散式信息的处理能力。每个样本平均包含2.5个需求与50轮对话,总上下文长度极大,有效模拟了真实开发中冗长、多任务并行的交互场景。其核心特征在于通过精心设计的查询大纲,动态生成了高度拟真的用户查询,这些查询捕捉了迭代需求、噪声输入和回顾性提问等关键交互模式。此外,数据集支持三种类型的下游评估任务:主题感知、信息项提取与函数生成,从对话理解、信息提取到最终代码生成,层层递进地全面评估上下文管理能力。这种多层次、动态交互的评估框架,确保了基准测试能够紧密贴合实际工作流,并提供可靠、系统的性能度量。
使用方法
LoCoEval的使用依托于其配套的动态交互式评估框架。评估过程分为对话生成与任务评估两个阶段。在对话生成阶段,一个模拟用户会根据预先生成的查询大纲,结合当前轮次的查询项、从代码仓库中检索到的相关内容以及一个来自真实世界的参考问题,动态生成每一轮的模拟用户查询。该查询随后被输入待评估的上下文管理智能体,智能体生成回应后,模拟用户再基于此回应生成下一轮查询,如此循环直至完成所有轮次的对话。在任务评估阶段,评估框架会向智能体依次提出预定义的三类任务查询(主题感知、信息项提取、函数生成),并收集其回答。对于前两类任务,采用基于大语言模型作为评判的F1分数进行评估;对于核心的函数生成任务,则复用原始数据集的测试套件,采用Pass@k指标进行基于执行的评估。该框架同时会记录整个评估过程中的大语言模型令牌消耗,以衡量推理成本。研究人员可通过该框架,系统性地评估不同上下文管理方法或基础大语言模型在仓库导向长程对话场景下的性能与效率。
背景与挑战
背景概述
随着大语言模型在代码理解与生成能力上的显著提升,代码助手在软件开发中日益普及。然而,在真实的仓库导向开发场景中,过长的多轮对话上下文可能导致模型关键信息丢失与性能下降,现有上下文管理方法多针对通用对话,缺乏专门面向仓库场景的评估基准。为此,北京航空航天大学复杂与关键软件环境国家重点实验室的研究团队于2024年提出了LoCoEval,这是首个专注于仓库导向长程对话上下文管理的基准数据集。该数据集通过大语言模型驱动的自动化流程构建,模拟了迭代需求、噪声输入和回顾性提问等真实交互模式,包含128个样本,分为单跳与多跳两个子集,支持主题感知、信息项提取和函数生成三类评估任务,旨在系统评估上下文管理方法在整合对话历史与仓库信息方面的效能,推动代码助手在复杂开发环境中的实用化进展。
当前挑战
LoCoEval致力于解决仓库导向长程对话上下文管理这一核心问题,其挑战主要体现在两个方面:在领域问题层面,现有大语言模型与通用上下文管理方法难以有效融合对话历史与代码仓库中的文本与代码工件,导致在超长上下文(最高达256K词元)中信息提取不精准、推理一致性下降,尤其内存系统在分散信息模式下面临显著性能瓶颈;在构建过程层面,确保生成对话的正确性、真实性与多样性是一大难点,需通过精心设计的提示工程、真实问答参考检索以及多阶段随机化策略,在模拟复杂交互的同时避免信息偏差,同时还需克服样本筛选、信息项依赖图构建以及动态评估框架设计中的技术复杂性,以维持基准的可靠性与代表性。
常用场景
经典使用场景
在软件工程领域,随着大型语言模型驱动的代码助手日益普及,开发者与智能体之间的多轮对话已成为常态。LoCoEval数据集专为评估此类场景下的长程对话上下文管理能力而设计,其经典使用场景聚焦于模拟真实代码仓库开发中的复杂交互。数据集通过自动化流水线生成包含迭代需求、噪声输入和回顾性提问等关键交互模式的对话,每个样本平均包含2.5个需求和50轮对话,总上下文长度可达64K至256K个标记。研究者和开发者利用LoCoEval评估智能体在超长对话中准确保留、检索关键信息并整合仓库代码的能力,从而系统检验上下文管理方法的有效性。
解决学术问题
LoCoEval主要解决了软件工程与人工智能交叉领域中的关键学术问题。针对现有上下文管理方法多面向通用对话、缺乏仓库导向场景优化的问题,该数据集填补了可靠评估基准的空白。它使得研究者能够客观衡量智能体在长程对话中处理交织的对话历史与仓库代码信息的能力,揭示了独立大型语言模型及现有方法在面临超长上下文时的性能瓶颈。通过引入单跳与多跳两个子集,数据集进一步区分了集中式与分散式信息分布模式下的管理挑战,为开发更高效的仓库专用上下文管理技术提供了实证基础。
衍生相关工作
LoCoEval的推出催生并连接了多个相关研究方向。在基准构建层面,它与早期通用对话上下文管理基准(如LoCoMo、LongMemEval)形成互补,并拓展了仓库导向基准(如SWE-Bench、RepoCoder)的评估维度,首次将长程对话管理纳入仓库场景。在方法改进层面,基于该数据集的评估结果,研究者提出了如Mem0R等改进方法,通过将对话记忆与仓库工件位置统一存储,增强了上下文感知的仓库检索能力。此外,数据集支撑了对对话超参数(如对话长度、任务数量)影响的开创性分析,为后续研究如何保持智能体在持续增长交互中的性能提供了重要见解。
以上内容由遇见数据集搜集并总结生成


