PPO-vs-CoPPO-TLDR-Mistral-7B-SmallSFT
收藏Hugging Face2025-03-20 更新2025-03-21 收录
下载链接:
https://huggingface.co/datasets/RLHF-And-Friends/PPO-vs-CoPPO-TLDR-Mistral-7B-SmallSFT
下载链接
链接失效反馈官方服务:
资源简介:
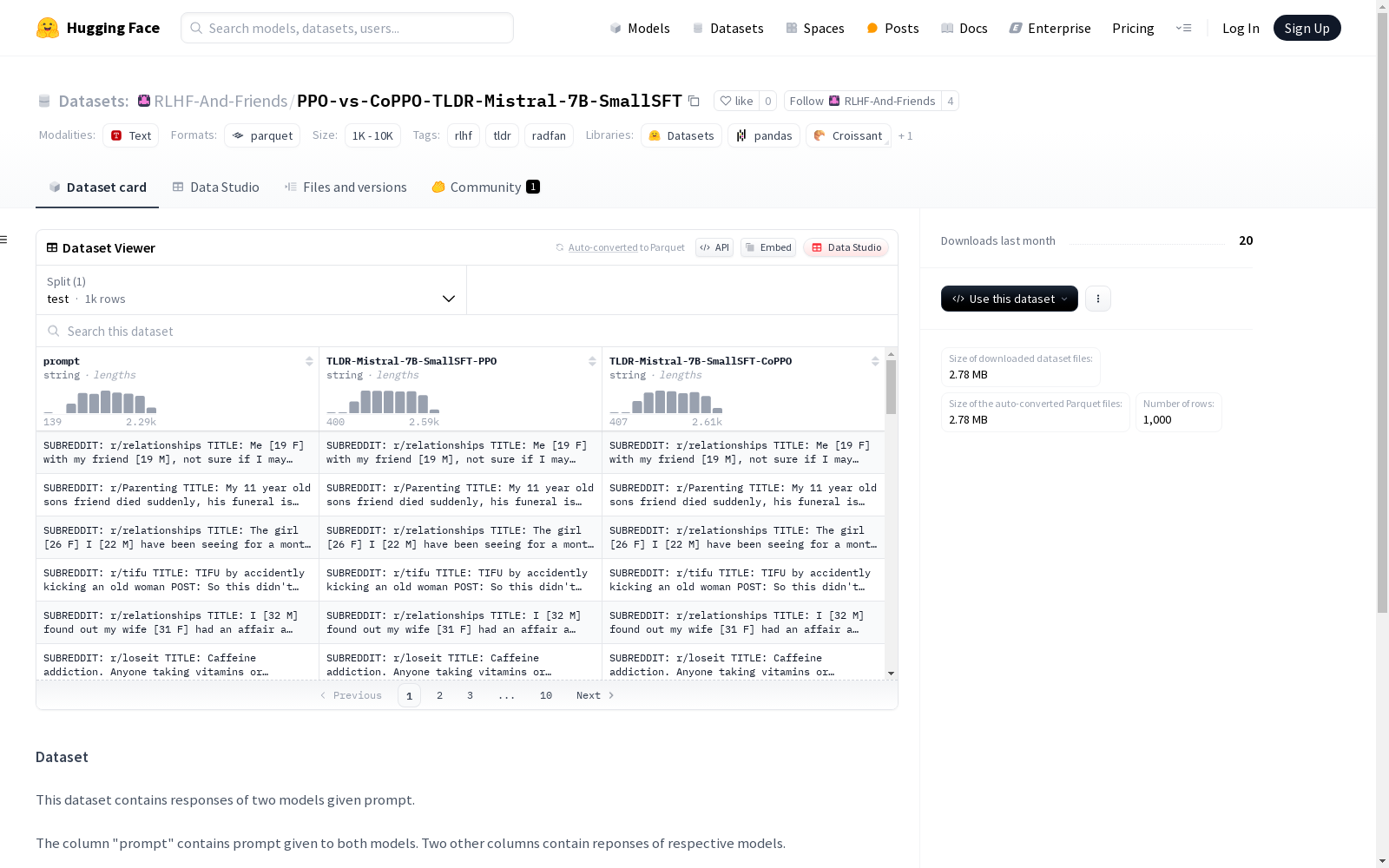
这个数据集包含了两个模型在给定提示下的响应。它包括一个提示列和两个模型响应列。左侧模型是TLDR-Mistral-7B-SmallSFT-PPO,右侧模型是TLDR-Mistral-7B-SmallSFT-CoPPO。原始数据集来自RLHF-And-Friends的tldr-ppo。
This dataset contains responses generated by two models in response to provided prompts. It includes one prompt column and two model response columns. The left-side model is TLDR-Mistral-7B-SmallSFT-PPO, while the right-side model is TLDR-Mistral-7B-SmallSFT-CoPPO. The original dataset is sourced from the tldr-ppo project under RLHF-And-Friends.
创建时间:
2025-03-20
搜集汇总
数据集介绍
构建方式
该数据集通过对比两种不同强化学习模型(PPO与CoPPO)在相同提示下的响应生成,构建了一个用于模型性能评估的基准。数据集中的提示来源于RLHF-And-Friends/tldr-ppo,每个提示对应两个模型的生成结果,分别记录在独立的列中。这种构建方式旨在通过直接对比模型输出,揭示不同强化学习策略在文本生成任务中的表现差异。
特点
该数据集的核心特点在于其专注于对比分析两种强化学习模型(TLDR-Mistral-7B-SmallSFT-PPO与TLDR-Mistral-7B-SmallSFT-CoPPO)的生成能力。通过引入GPT-4o-mini作为评估工具,数据集提供了CoPPO模型相对于PPO模型的胜率(0.707),为研究者提供了直观的性能指标。此外,数据集的提示内容来源于高质量的RLHF数据集,确保了生成结果的多样性和实用性。
使用方法
该数据集可用于评估和比较不同强化学习模型在文本生成任务中的表现。研究者可以通过分析模型生成的响应,结合GPT-4o-mini的评估结果,深入探讨PPO与CoPPO策略的优劣。此外,数据集还可作为训练或微调其他生成模型的参考,帮助提升模型在特定任务上的性能。使用时应关注提示与响应的对应关系,并结合胜率数据进行综合分析。
背景与挑战
背景概述
PPO-vs-CoPPO-TLDR-Mistral-7B-SmallSFT数据集由RLHF-And-Friends团队创建,旨在比较两种不同强化学习算法(PPO与CoPPO)在自然语言生成任务中的表现。该数据集基于TLDR-Mistral-7B-SmallSFT模型,专注于生成简洁的文本摘要。通过对比两种算法在相同提示下的生成结果,研究人员能够深入分析不同强化学习策略对模型性能的影响。这一研究不仅推动了强化学习与自然语言处理的交叉领域发展,还为优化语言模型的生成质量提供了新的视角。
当前挑战
该数据集的核心挑战在于如何准确评估不同强化学习算法在自然语言生成任务中的优劣。尽管通过GPT-4o-mini模型对生成结果进行了评分,但评估的主观性和评分模型的局限性可能导致结果偏差。此外,构建过程中需要确保提示的多样性和代表性,以全面反映模型在不同语境下的表现。同时,如何平衡生成文本的简洁性与信息完整性,也是数据集构建和模型优化中需要解决的关键问题。
常用场景
经典使用场景
在自然语言处理领域,PPO-vs-CoPPO-TLDR-Mistral-7B-SmallSFT数据集主要用于比较和评估不同强化学习算法在文本生成任务中的表现。通过对比PPO(Proximal Policy Optimization)和CoPPO(Conservative Proximal Policy Optimization)两种算法在TLDR(Too Long; Didn't Read)任务中的生成效果,研究人员能够深入理解不同策略优化方法对模型输出的影响。
衍生相关工作
基于该数据集的研究成果,许多相关工作得以展开。例如,研究人员进一步探索了CoPPO算法在其他文本生成任务中的应用,并提出了改进版本的优化算法。此外,该数据集还启发了更多关于强化学习与自然语言处理结合的研究,推动了该领域的进一步发展。
数据集最近研究
最新研究方向
在强化学习与人类反馈(RLHF)领域,PPO-vs-CoPPO-TLDR-Mistral-7B-SmallSFT数据集为研究者提供了对比两种不同优化策略(PPO与CoPPO)在生成式任务中表现的宝贵资源。近期研究聚焦于如何通过改进的优化算法提升模型在文本摘要任务中的表现,尤其是针对TLDR(Too Long; Didn't Read)场景。TLDR-Mistral-7B-SmallSFT-CoPPO模型以70.7%的胜率显著优于其PPO版本,这一结果不仅验证了CoPPO策略的有效性,也为未来在RLHF框架下探索更高效的优化方法提供了重要参考。该数据集的研究成果对推动生成式模型在自然语言处理中的应用具有深远意义,特别是在提升模型生成内容的准确性和简洁性方面。
以上内容由遇见数据集搜集并总结生成


