HISTAI-Instruct
收藏Hugging Face2025-12-19 更新2025-12-20 收录
下载链接:
https://huggingface.co/datasets/SaltySander/HISTAI-Instruct
下载链接
链接失效反馈官方服务:
资源简介:
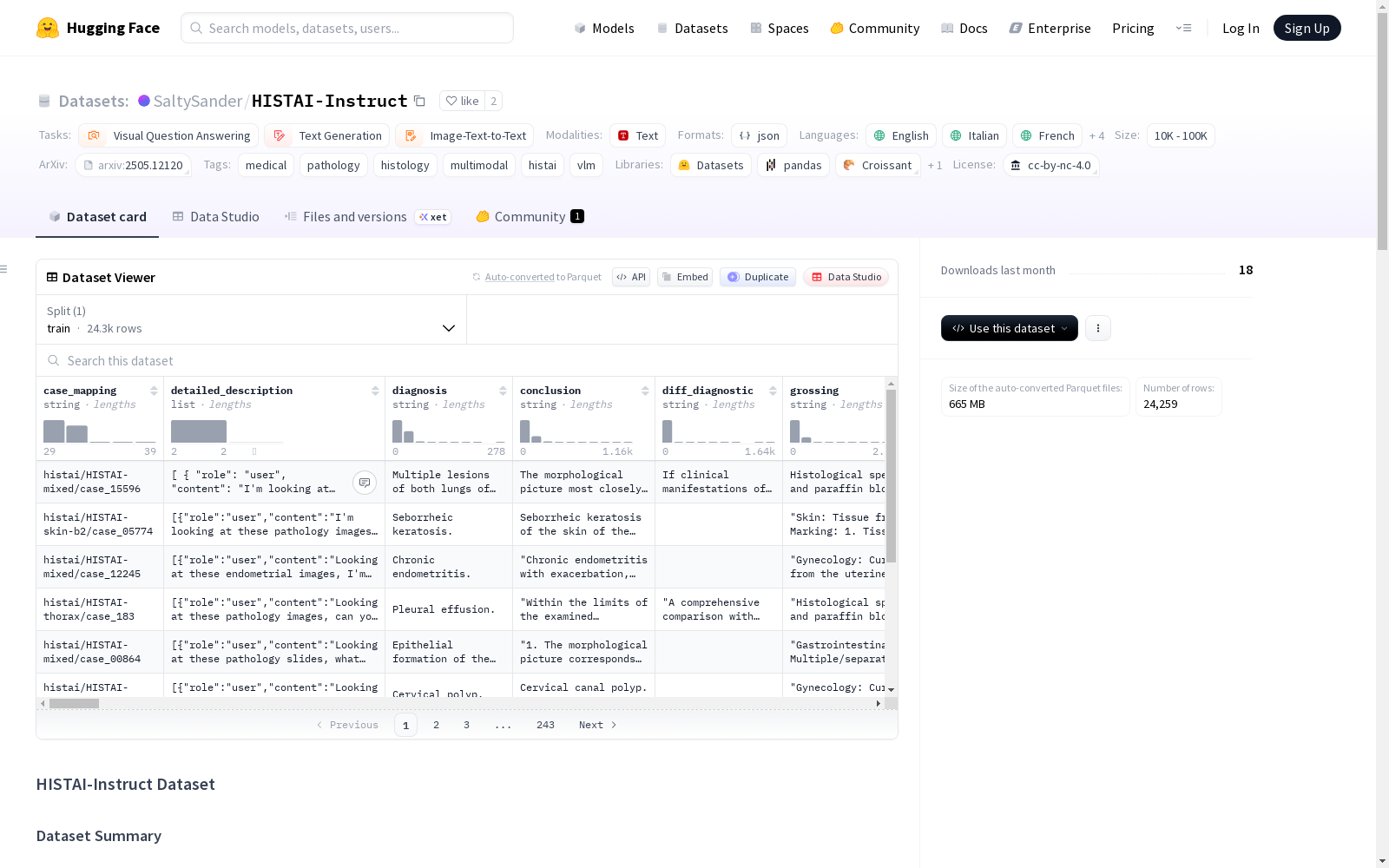
HISTAI-Instruct是一个多语言、多模态的指令调优数据集,专为计算病理学设计,基于开放的HISTAI数据集构建。它旨在支持视觉语言模型(VLMs)在病理学任务中的应用,包括详细描述、鉴别诊断和多轮对话。数据集包含24,259个病例和全切片图像(WSIs),涵盖9个器官,生成1,175,524个对话属性和2,153,699个问答对(包括多轮对话),支持7种语言。数据集结构包括主数据集、原始和中间数据、审计跟踪以及数据分割。
创建时间:
2025-12-11
原始信息汇总
HISTAI-Instruct 数据集概述
数据集基本信息
- 许可证: cc-by-nc-4.0
- 语言: 英语、意大利语、法语、荷兰语、波兰语、德语、西班牙语
- 多语言性: 多语言
- 任务类别: 视觉问答、文本生成、图像文本到文本
- 标签: 医学、病理学、组织学、多模态、histai、视觉语言模型
- 规模类别: 1M<n<10M
数据集摘要
HISTAI-Instruct 是一个基于开放 HISTAI 数据集构建的多语言、多模态指令调优数据集,专为计算病理学设计。该数据集旨在支持视觉语言模型在组织病理学任务中的应用,包括详细描述、鉴别诊断和多轮对话。
关键统计信息
- 病例和全切片图像数量: 24,259
- 涵盖器官数量: 9
- 生成的对话属性数量: 1,175,524
- 问答对总数: 2,153,699(统计对话中的多轮交互)
- 涵盖语言数量: 7
数据集结构
主数据集
histai-instruct.jsonl: 论文《Democratizing Pathology Co-Pilots: An Open Pipeline and Dataset for Whole-Slide Vision-Language Modelling》中使用的最终指令调优数据集。- 过滤: 使用 LLM-as-a-judge 进行完全质量过滤。
- 多样性: 包含多样化的问题措辞。
- 格式: JSON Lines(
.jsonl)。原始 HISTAI 数据集中的age字段已标准化为使用一致类型(有效年龄为整数,缺失值为null),以确保与数据集查看器的兼容性。
原始和中间数据(auxiliary_data/)
auxiliary_data/raw/raw.jsonl: 未过滤的数据集,包含所有生成的样本,包括后来被质量过滤器拒绝的样本。auxiliary_data/raw/filtered.jsonl: 经过专家质量过滤但未进行问题多样化的中间数据集。auxiliary_data/judge/judge_results.jsonl: LLM-as-a-judge 系统的详细输出。该文件包含每个样本的分数和推理,这些信息决定了样本是否被纳入最终数据集。
审计跟踪(audit/)
管道执行期间生成的日志和报告,记录了转换统计信息、数据丢失/保留率以及处理指标。
数据划分(splits/)
splits/train_2k.txt: 包含 2,000 个样本训练集的 ID。splits/train_9k.txt: 包含 9,000 个样本训练集的 ID。splits/test.txt: 包含测试集的 ID。splits/train.txt: 包含完整训练集的 ID。splits/val.txt: 包含验证集的 ID。
数据集创建与可重复性
该数据集是使用开源框架 Polysome 生成的。数据预处理、后处理和模型训练的代码可在 ANTONI-Alpha 代码库中找到。基于此数据集训练的模型可在 Huggingface 上获取。
引用
如果在本研究中使用此数据集,请引用相关工作和 hist.ai 的原始数据集论文。
搜集汇总
数据集介绍
构建方式
在数字病理学领域,构建高质量的多模态指令数据集对于推进视觉语言模型的发展至关重要。HISTAI-Instruct数据集以开放的HISTAI数据集为基础,通过Polysome框架构建数据生成流水线,利用大型语言模型生成多样化的问答对和对话属性。生成过程涵盖了原始数据的全面采集,随后采用专家质量过滤与LLM-as-a-judge系统进行双重筛选,确保样本的准确性与可靠性。最终数据集经过规范化处理,年龄字段统一为整数或空值,以兼容多种数据查看工具,同时保留了完整的审计轨迹和中间数据,支持研究可复现性。
特点
该数据集在计算病理学中展现出显著的多语言与多模态特性,覆盖英语、意大利语、法语等七种语言,增强了模型的跨文化适用性。其核心特点在于规模庞大,包含超过24,000个病例和全切片图像,涉及九个器官,生成了近120万条对话属性和215万余个问答对,支持详细描述、鉴别诊断和多轮对话等复杂任务。数据经过严格过滤与多样化问题表述处理,确保了高质量与多样性,并提供了明确的训练、验证和测试划分,便于模型开发与评估。
使用方法
在病理学视觉语言建模应用中,HISTAI-Instruct数据集的使用方法清晰而灵活。研究人员可通过主数据集文件histai-instruct.jsonl直接获取经过过滤的指令调优数据,该文件采用JSON Lines格式,便于流式处理与集成。辅助数据目录提供了原始和中间数据,允许深入分析过滤过程与质量评估。数据集划分文件支持不同规模的训练集配置,如2,000或9,000样本,以及标准的验证与测试集,用户可依据具体需求选择相应划分进行模型训练与性能验证,从而推动病理学辅助系统的开发与优化。
背景与挑战
背景概述
在计算病理学领域,全切片图像(WSI)的分析对于疾病诊断与预后评估至关重要,然而传统方法依赖于病理学家的专业经验,存在主观性强与效率低下的局限。HISTAI-Instruct数据集由Sander Moonemans等研究人员于2025年构建,基于Nechaev等人开发的开放HISTAI数据集扩展而成,旨在通过多语言、多模态的指令调优数据,支持视觉语言模型在组织病理学任务中的应用,涵盖详细描述、鉴别诊断与多轮对话等核心研究问题。该数据集整合了来自9个器官的24,259个病例与WSI,生成超过117万条对话属性与215万对问答数据,覆盖7种语言,为开发病理学辅助系统提供了大规模、高质量的基准资源,推动了人工智能在医疗影像分析中的民主化进程。
当前挑战
HISTAI-Instruct数据集致力于解决计算病理学中视觉语言建模的复杂挑战,包括如何使模型准确理解高分辨率全切片图像的细微形态特征,并生成专业、连贯的多语言文本响应,以辅助病理诊断与教育。在构建过程中,研究人员面临数据质量控制的难题,需通过LLM-as-a-judge系统对生成内容进行严格筛选,确保医学信息的准确性与一致性;同时,多语言数据的平衡与多样性维护也是一项关键挑战,要求在不同语言间保持病理术语的精确翻译与语境适配。此外,数据集的规模化处理与可重复性保障,涉及原始图像与元数据的整合、过滤流程的透明化,以及开源框架Polysome的协同应用,这些环节均需克服技术集成与资源管理的障碍。
常用场景
经典使用场景
在计算病理学领域,HISTAI-Instruct数据集为多模态视觉语言模型提供了关键的指令微调资源。其核心应用场景在于训练模型进行组织病理学图像的深度解析与对话交互,例如针对全切片图像生成详细描述、执行鉴别诊断以及支持多轮医学对话。通过涵盖九种器官类型和超过百万条对话属性,该数据集能够有效模拟病理医师的推理过程,为构建智能病理辅助系统奠定数据基础。
衍生相关工作
基于该数据集衍生的经典工作包括开源框架Polysome构建的数据生成管道,以及ANTONI-Alpha系列视觉语言模型。这些研究不仅验证了指令微调在医学多模态任务中的有效性,更形成了从数据生成、质量过滤到模型训练的全链路开源生态。相关技术方案已被拓展至数字病理学的其他子领域,为组织学分型、预后预测等任务提供了可复现的研究范式。
数据集最近研究
最新研究方向
在计算病理学领域,多模态人工智能的融合正成为推动精准医疗发展的核心动力。HISTAI-Instruct数据集作为一项多语言、多模态的指令调优资源,其前沿研究聚焦于构建面向全切片图像的视觉-语言模型,以支持病理诊断中的详细描述、鉴别诊断及多轮对话任务。该数据集通过整合大规模全切片图像与多语言文本指令,促进了病理学辅助诊断系统的开放化与民主化进程,相关研究紧密关联于开源框架如Polysome和ANTONI-Alpha的开发,旨在提升模型在跨器官、跨语言场景下的泛化能力与临床适用性。这些进展不仅加速了病理学与人工智能的交叉创新,也为全球医疗资源不均等背景下远程病理诊断的普及提供了技术基石。
以上内容由遇见数据集搜集并总结生成


