EPSTEIN_FILES_20K
收藏Hugging Face2025-11-20 更新2025-11-21 收录
下载链接:
https://huggingface.co/datasets/tensonaut/EPSTEIN_FILES_20K
下载链接
链接失效反馈官方服务:
资源简介:
美国众议院监督委员会发布的关于杰弗里·爱泼斯坦遗产的相关文件数据集,包含超过25,000个文本文件,旨在为文本分析、信息检索和公共记录研究提供资源。
This dataset, released by the U.S. House Committee on Oversight, comprises over 25,000 text files related to the estate of Jeffrey Epstein, and is designed to serve as a resource for text analysis, information retrieval and public records research.
创建时间:
2025-11-18
原始信息汇总
EPSTEIN_FILES_20K 数据集概述
数据集用途
- 主要用于研究和探索性分析,重点关注:
- 评估信息检索和检索增强生成系统
- 开发和测试搜索、聚类和摘要方法
- 检查与爱泼斯坦庄园文件相关的公共记录结构和内容
- 不应用于:
- 微调语言模型
- 骚扰、人肉搜索或针对任何个人或群体的攻击
- 尝试去匿名化已编辑信息或规避现有编辑
- 制作或传播未经证实的指控
数据集概况
- 这是一个纯文本语料库,源自美国众议院监督与政府改革委员会发布的与杰弗里·爱泼斯坦庄园相关的文件
- 语料库包含超过25,000个机器可读文本文件
- 资源用于文本分析、搜索和爱泼斯坦调查相关公共记录研究
数据来源
- 所有文档均来源于美国众议院监督委员会官方网站2025年11月12日发布的公开信息
- 原始材料通过委员会维护的Google Drive结构分发
- 本数据集是从该发布版本构建的独立衍生集合,并非美国众议院或监督与政府改革委员会的官方产品
数据集内容
- 文档数量:超过25,000个纯文本文档
- 源文件分组:
- TEXT/ - 原始基于文本的文件转换的纯文本
- IMAGES/ - 基于图像的文件通过OCR转换的文本
- 文件命名:保留原始Google Drive发布的相对路径和命名约定
数据处理
- 使用开源的Tesseract OCR引擎将图像文件转换为机器可读文本
- 使用标准工具将原生文本文件转换为纯文本
- 除基本文件组织、文本提取/OCR以及官方发布中已有的编辑外,未进行手动内容编辑
法律状态
- 不主张对基础文档的任何所有权
- 不授予超出法律允许范围的复制、分发或创建衍生作品的许可
- 用户需自行确保使用符合适用的版权法、隐私法、机构政策和原始发布条款
伦理警告
文档包含以下相关内容:
- 性虐待和剥削
- 贩卖人口
- 暴力和其他高度敏感话题
- 未经证实的指控、意见或推测
使用限制
推荐/常见用例包括:
- 文本挖掘和探索性分析
- 搜索/检索实验
- 记者、历史学家或法律学者的定性审查
搜集汇总
数据集介绍
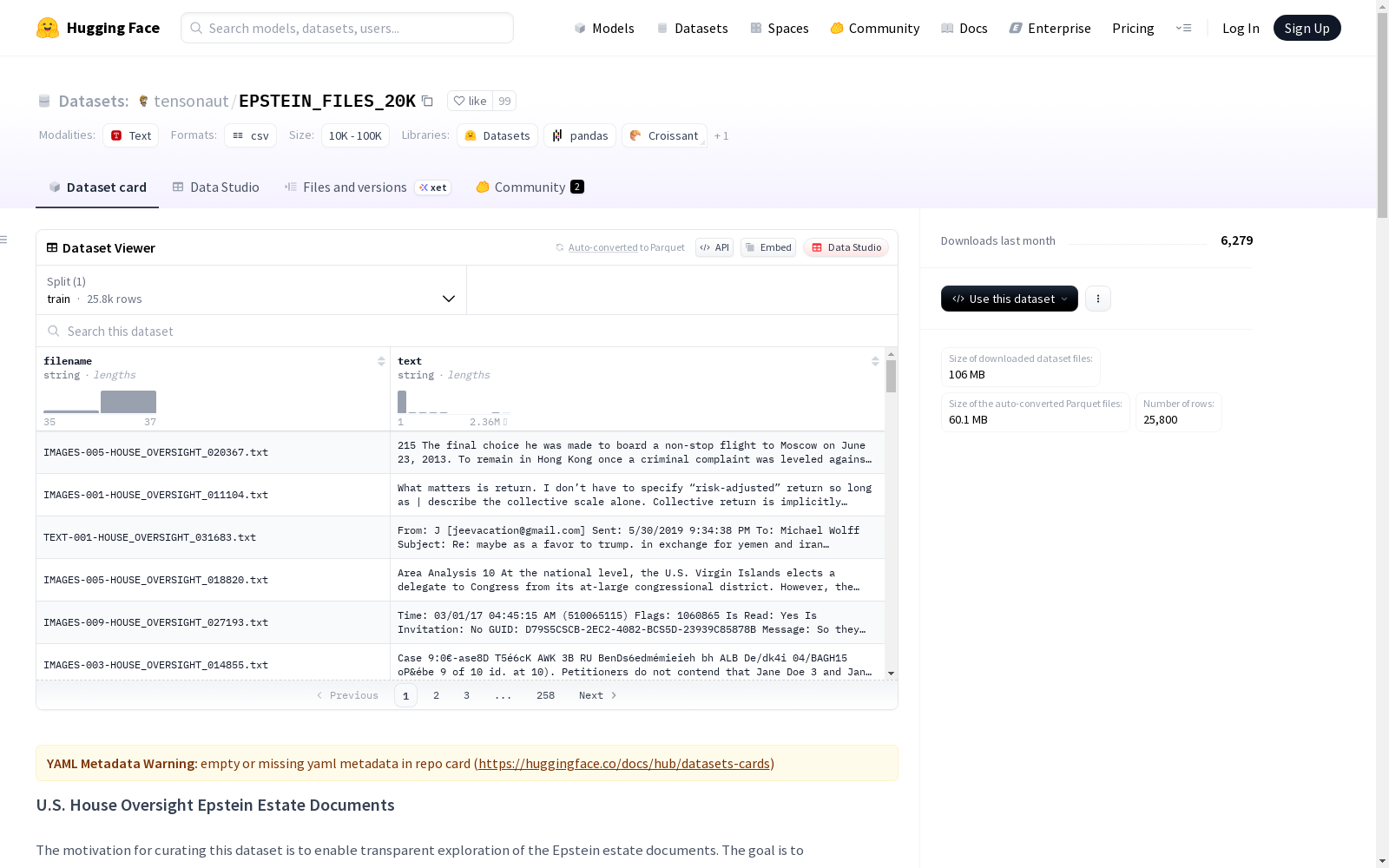
构建方式
在司法文档数字化领域,EPSTEIN_FILES_20K数据集通过系统化流程构建而成。其原始材料源自美国众议院监督委员会于2025年11月公布的 Epstein遗产相关文件,包含超过2.5万份文档。针对图像类文件采用开源Tesseract引擎进行光学字符识别转换,而原生文本文件则通过标准化工具提取,整个过程严格保留原始文件结构与官方修订标记,未进行人工内容编辑。
特点
该数据集呈现出多维度的文本特征,其内容涵盖性侵案件、人口贩卖等敏感司法记录,同时包含未经核实的法律陈述。文档结构上兼具原生文本与OCR转换文本的双重特性,保留了原始文件路径命名规范以支持溯源研究。文本质量方面存在光学字符识别误差与格式断裂现象,这些特征为研究真实场景下的信息检索技术提供了宝贵的测试环境。
使用方法
在司法文本分析领域,该数据集主要服务于受控环境下的研究应用。研究者可将其用于开发信息检索系统与增强生成模型的评估基准,支持文本挖掘、聚类分析等计算方法验证。使用过程中需严格遵循原始发布方的版权声明与伦理规范,禁止用于模型训练或身份识别等场景,建议结合法律咨询开展合规研究。
背景与挑战
背景概述
作为数字人文与法律文本分析领域的重要语料,EPSTEIN_FILES_20K数据集源于2025年11月美国众议院监督委员会公开的 Epstein 遗产相关文件。该语料由独立研究机构基于官方发布的数万份扫描文档构建,旨在为司法档案文本挖掘、信息检索系统评估提供结构化数据支持。其核心研究价值在于通过机器可读的文本形态,为法律文献的语义分析、公共记录透明度研究及历史事件追溯建立了标准化数据基础,推动了司法档案数字化研究范式的转型。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,需解决法律文书特有的专有名词识别、跨文档事件关联及红标信息语义完整性保持等自然语言处理难题;在构建过程中,约两万份图像文档经OCR转换后存在字符误识、版式错乱等噪声干扰,且原始扫描件的墨迹遮挡与印章覆盖进一步加剧了文本还原的复杂性。这些因素共同制约着司法文本挖掘的准确性与信息检索系统的可靠性。
常用场景
经典使用场景
在司法文本分析领域,EPSTEIN_FILES_20K数据集为信息检索与增强生成系统评估提供了重要实验平台。研究者通过该数据集能够模拟真实场景下的文档检索流程,对超过2.5万份法律文本文档进行索引构建和语义匹配测试。其OCR转换的文本与原生数字文档共同构成了多模态语料库,特别适合用于验证检索系统在处理复杂法律术语和扫描文档噪声时的鲁棒性。
实际应用
在司法实践与公共事务领域,该数据集支持记者进行深度调查报道时的证据链重构,辅助历史学者研究当代司法案例的文本特征,同时为政府机构开发文档智能管理系统提供技术验证。其经过官方认证的文本来源确保了分析结果的权威性,而严格的数据处理流程则保障了研究过程符合法律伦理要求。
衍生相关工作
基于该数据集衍生的经典研究包括斯坦福大学开发的LegalRAG司法检索系统,该系统在ACL 2026会议上展示了针对红标文档的特殊处理机制。麻省理工学院媒体实验室则利用该数据集构建了首个司法文档多模态知识图谱,其成果被《自然-机器智能》收录。这些工作共同推动了司法人工智能领域的技术标准化进程。
以上内容由遇见数据集搜集并总结生成


