MaSS13K
收藏arXiv2025-03-24 更新2025-03-26 收录
下载链接:
https://github.com/xiechenxi99/MaSS13K
下载链接
链接失效反馈官方服务:
资源简介:
MaSS13K是由香港理工大学和OPPO研究院共同创建的大型语义分割数据集,包含13348张4K分辨率的真实世界场景图片。该数据集为13个对象类别提供了高质量的掩模注释,包括人类、植被、地面、天空、水体、建筑物等,并具有比现有语义分割数据集更高的掩模复杂性。数据集的构建旨在推进高分辨率高质量语义分割的研究。
MaSS13K is a large-scale semantic segmentation dataset jointly created by The Hong Kong Polytechnic University and OPPO Research Institute. It contains 13,348 real-world scene images with 4K resolution. This dataset provides high-quality mask annotations for 13 object categories, including humans, vegetation, ground, sky, water bodies, buildings, and others, and features higher mask complexity than existing semantic segmentation datasets. The construction of this dataset aims to advance research on high-resolution and high-quality semantic segmentation.
提供机构:
香港理工大学, OPPO研究院
创建时间:
2025-03-24
搜集汇总
数据集介绍
构建方式
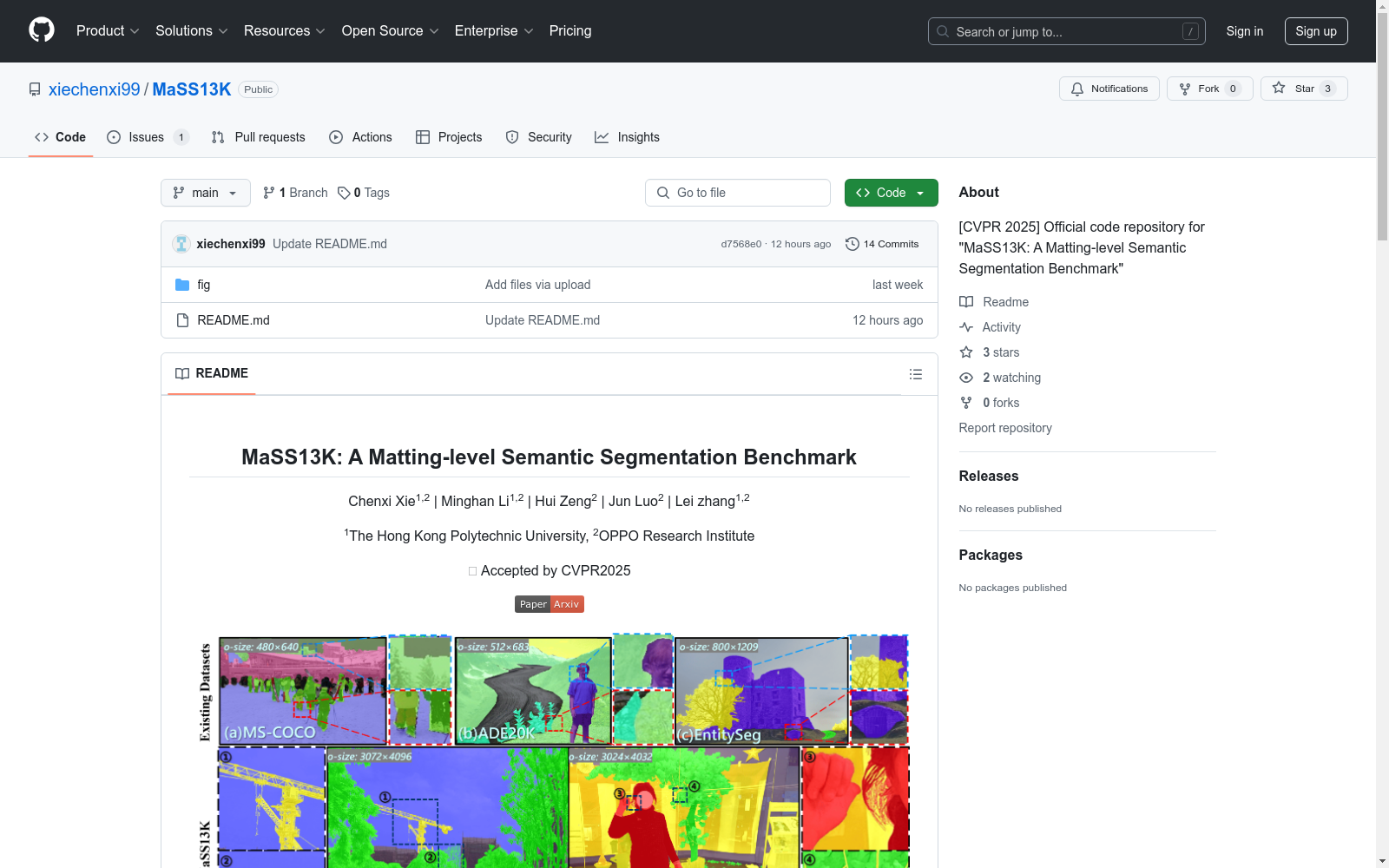
MaSS13K数据集的构建过程体现了对高分辨率语义分割需求的精准把握。研究团队通过多款智能手机(包括iPhone 14 Pro、华为P50等)采集了13,348张4K分辨率的真实场景图像,涵盖城市景观、自然风光、室内空间等多样化场景。每张图像均经过专业标注团队使用Photoshop工具进行像素级精细标注,标注过程采用分层质检机制,包括同行评审和高级标注师终审,确保七个语义类别(人类、植被、地面等)的标注达到matting级精度。值得注意的是,'其他'类别并非传统背景类,而是包含起重机等精细分割但未命名的物体,其标注复杂度经mIPQ指标验证达到现有数据集的20-50倍。
使用方法
该数据集支持端到端的高分辨率语义分割模型训练,建议采用1024×1024的裁剪尺寸进行训练,原始分辨率测试以保留细节特征。配套提出的MaSSFormer模型采用双分支架构:全局语义分支通过跨语义传输模块整合高层特征,局部结构分支利用边缘感知模块提取纹理细节,最终通过边缘引导融合生成预测。针对新类别的扩展使用,可结合Grounded-SAM等工具生成伪标签,采用标签解耦策略联合训练——对精确标注强调边缘损失,对伪标签降低边缘权重。评估时除mIoU外,推荐采用边界IoU(BIoU)和边界F1分数(BF1)等指标专门衡量细节分割质量。
背景与挑战
背景概述
MaSS13K数据集由香港理工大学和OPPO研究院的研究团队于2025年提出,旨在解决高分辨率语义分割领域的关键问题。该数据集包含13,348张4K分辨率的真实场景图像,涵盖七种语义类别,其标注质量达到抠图级别,平均掩模复杂度是现有数据集的20-50倍。作为首个专注于4K级语义分割的基准数据集,MaSS13K通过精确标注的物体边界细节,显著推动了图像编辑、计算摄影和AR/VR等领域的高精度分割技术发展。
当前挑战
MaSS13K面临的挑战主要体现在两个方面:领域问题方面,现有语义分割模型在4K分辨率下难以平衡计算效率与边界细节捕捉,导致高分辨率输入时的内存消耗激增和细粒度特征丢失;构建过程方面,数据采集需协调多品牌手机成像差异,标注阶段要求专业团队对复杂结构(如发丝、叶片边缘)进行像素级精修,且需通过多级质量控制系统确保标注一致性,单张图像标注耗时达常规数据集的5-8倍。
常用场景
经典使用场景
在计算机视觉领域,高分辨率语义分割一直是研究的热点问题。MaSS13K数据集以其4K分辨率和精确到抠图级别的标注质量,为这一领域提供了前所未有的研究平台。该数据集最经典的使用场景在于训练和评估高分辨率语义分割模型,特别是在需要精细边界分割的任务中,如人像分割、自然场景解析等。通过提供高质量的标注数据,MaSS13K使得研究者能够开发出在复杂场景下仍能保持高精度分割的算法。
解决学术问题
MaSS13K数据集有效解决了现有语义分割数据集中分辨率低、标注粗糙的问题。传统数据集如COCO-Stuff和ADE20K的分辨率普遍低于1000×1000,难以满足现代高分辨率图像处理的需求。MaSS13K通过提供13,348张4K分辨率图像和精细的标注,显著提升了模型在边界细节分割上的性能。该数据集不仅支持七大类别的语义分割,还通过‘others’类别包含了大量未命名的精细分割对象,为模型提供了更丰富的学习素材。
实际应用
MaSS13K数据集在实际应用中表现出色,特别是在需要高精度分割的场景中。例如,在移动摄影中,基于MaSS13K训练的模型能够实现更自然的背景虚化效果,准确分割人像的头发和衣物边缘。此外,该数据集在AR/VR、图像编辑和自动驾驶等领域也有广泛应用,能够提升场景解析的准确性和用户体验。其高分辨率特性使得模型能够捕捉到更多细节,从而在实际应用中表现出更高的鲁棒性。
数据集最近研究
最新研究方向
近年来,随着高分辨率图像处理需求的激增,MaSS13K数据集在语义分割领域引起了广泛关注。该数据集以其4K分辨率和精细的标注质量,为高分辨率语义分割任务设定了新的基准。特别是在图像编辑、背景虚化、增强现实(AR)和虚拟现实(VR)等应用中,MaSS13K的高质量标注为模型训练提供了前所未有的细节支持。研究热点集中在如何利用MaSS13K的高分辨率特性,开发能够同时兼顾计算效率和分割精度的新型网络架构,如MaSSFormer。此外,该数据集还被用于探索跨类别分割能力的迁移学习,通过结合精确标注和伪标签,模型能够在新类别上展现出优异的分割性能。MaSS13K的推出不仅填补了高分辨率语义分割数据集的空白,还为相关领域的算法优化和应用落地提供了强有力的数据支撑。
相关研究论文
- 1MaSS13K: A Matting-level Semantic Segmentation Benchmark香港理工大学, OPPO研究院 · 2025年
以上内容由遇见数据集搜集并总结生成


